0. Recent Advances of Reinforcement Learning in Multi-Robot Collaborative Decision-Making: A Review
1. Introduction
The escalating complexity of real-world tasks necessitates the development of sophisticated autonomous systems capable of operating collaboratively. Multi-Robot Systems (MRS) have emerged as a pivotal solution, offering significant advantages over single robot systems in terms of efficiency, reliability, and flexibility across diverse applications, including automated manufacturing, disaster relief, and search and rescue . Effective multi-robot coordination, underpinned by robust communication, seamless cooperation, and precise synchronization, is crucial for achieving shared objectives .

In this context, collaborative decision-making is paramount, as traditional pre-programmed behaviors are insufficient to address the dynamic interactions and unpredictable environments characteristic of MRS .
Reinforcement Learning (RL) and, more specifically, Multi-Agent Deep Reinforcement Learning (MADRL) have demonstrated considerable promise in enabling robots to learn autonomously from experience and adapt their performance in complex, dynamic environments . This paradigm shift fosters more resilient and adaptive robotic swarms, with the potential to revolutionize fields such as disaster response and space exploration .
Despite its transformative potential, the application of RL and MADRL in multi-robot systems faces formidable challenges. These include the "curse of dimensionality" due to expansive state-action spaces, the non-stationarity inherent in multi-agent learning environments, the delicate balance between exploration and exploitation, and the imperative for effective coordination strategies . Furthermore, limitations in communication, environmental adaptability, and generalization capabilities present significant hurdles . A notable challenge, particularly in Deep Reinforcement Learning (DRL), is "data inefficiency," which constrains practical application . Distributed learning approaches, such as Distributed Deep Reinforcement Learning (DDRL), are being explored as a crucial avenue to enhance data efficiency and scalability in multi-robot settings . Beyond technical considerations, the increasing sophistication and autonomy of MRS also bring forth significant societal implications, underscoring the critical need for responsible AI development and ethical deployment .
This survey aims to provide a comprehensive review of the recent advances, challenges, and applications at the intersection of Reinforcement Learning and multi-robot collaborative decision-making. While prior surveys have offered valuable insights into general Multi-Agent Reinforcement Learning (MARL), distributed MARL, or distributed deep reinforcement learning (DDRL), often categorizing algorithms or discussing foundational connections to game theory , this work distinguishes itself by specifically focusing on the integration of advanced RL techniques within the complexities of multi-robot systems. It provides a focused examination of how multi-robot applications, multi-agent learning, and deep reinforcement learning are currently being integrated . Unlike broader reviews that encompass various robot learning technologies, this survey emphasizes "recent advances" of RL in the multi-robot collaboration context, bridging the gap between MARL research and its practical application in MRS .
The primary objective is to offer a comprehensive overview of MADRL for multi-robot systems, analyzing key methodological challenges and emerging approaches, including attention mechanisms and advanced MADRL algorithms . Furthermore, the survey explores practical applications across domains such as navigation, cooperative manipulation, and distributed task allocation, while also considering crucial aspects like human-robot interaction, scalability, robustness, and emerging trends such as blockchain integration and edge computing . By meticulously classifying reviewed papers based on their multi-robot applications and providing insights into potential future developments, this survey aims to significantly advance the current state-of-the-art and inspire future research directions within multi-robot collaborative decision-making .
1.1 Background and Motivation
The emergence and increasing significance of multi-robot systems (MRS) represent a critical area of research, driven by their inherent advantages in achieving complex objectives that are beyond the capabilities of single robot systems (SRS) . MRS offer enhanced efficiency, reliability, and flexibility, making them indispensable for a broad spectrum of applications, including automated manufacturing, disaster relief, harvesting, last-mile delivery, port and airport operations, and search and rescue . The core challenge in these systems lies in achieving effective multi-robot coordination, which necessitates robust communication, seamless cooperation, and precise synchronization among numerous robots to accomplish shared goals efficiently .
Collaborative decision-making is paramount for the advancement of MRS because it addresses the complexities arising from dynamic interactions and the imperative for real-time decision-making in unpredictable environments . Traditional pre-programmed behaviors are insufficient given the complexity of tasks and the variability of environments; thus, robots must possess the capacity to learn from experience and adapt their performance autonomously . Reinforcement Learning (RL) and particularly Multi-Agent Deep Reinforcement Learning (MADRL), have emerged as potent approaches to enable these collaborative decision-making capabilities within MRS . MADRL empowers multi-robot systems to learn and adapt in complex, dynamic environments, fostering more resilient and adaptive robotic swarms for diverse scenarios, potentially revolutionizing fields such as disaster response and space exploration .
Despite its promise, the application of RL and MADRL in multi-robot systems faces several significant challenges. These include the "curse of dimensionality" stemming from large state-action spaces, the non-stationarity of the learning problem due to the simultaneous learning of multiple agents, the intricacies of balancing exploration and exploitation, and the critical need for effective coordination strategies . Furthermore, issues such as communication constraints, environmental adaptability, and generalization capabilities present considerable hurdles . A particularly prominent challenge that motivates current research is "data inefficiency," a common limitation in Deep Reinforcement Learning (DRL) that hinders practical application . Distributed learning approaches, such as Distributed Deep Reinforcement Learning (DDRL), are being actively explored as a critical solution to improve data efficiency and scalability in multi-robot settings .
The increasing sophistication and autonomy of multi-robot systems also bring forth broader societal implications, necessitating a critical consideration of responsible AI. While many existing works focus on technical advancements, some acknowledge the potential ethical implications and societal impacts of advanced multi-robot systems . Ensuring the safe, reliable, and ethically sound deployment of these systems is paramount, setting the stage for a comprehensive discussion on responsible AI and ethical considerations later in this survey.
1.2 Scope and Contributions of the Survey
This survey focuses on the intersection of Reinforcement Learning (RL) and multi-robot collaborative decision-making, aiming to provide a comprehensive review of recent advances, challenges, and applications within this rapidly evolving field. While existing literature offers valuable insights into related areas, this survey carves out a distinct niche by specifically concentrating on the dynamic interplay between advanced reinforcement learning techniques and the complexities of multi-robot systems.
Several prior surveys have addressed aspects of this domain, each with a particular emphasis. For instance, some reviews provide a general overview of Multi-Agent Reinforcement Learning (MARL), categorizing algorithms by task type (e.g., fully cooperative, fully competitive, mixed) and agent awareness, as well as discussing challenges like non-stationarity and coordination . Such surveys often highlight the foundational connections of MARL with game theory and evolutionary computation but do not exclusively focus on multi-robot systems or offer a specific abstract overview tailored for robotics . Other works delve into the state-of-the-art in distributed MARL for multi-robot cooperation, analyzing challenges such as non-stationarity and partial observability in decentralized multi-robot systems (MRS) . These reviews also often include benchmarks and robotic applications of distributed MARL, identifying open research avenues . Furthermore, some surveys focus on distributed deep reinforcement learning (DDRL), categorizing methods and identifying components for efficient distributed learning across various agent configurations, from single-player single-agent to multi-player multi-agent scenarios . A key contribution of such reviews can be the examination of toolboxes facilitating DDRL implementation and the development of new platforms for complex environments like Wargame .
In contrast, this survey provides a focused examination of recent advances, distinguishing itself by synthesizing how multi-robot applications, multi-agent learning, and deep reinforcement learning are integrated in current research . Unlike surveys that broadly cover robot learning in MRS, including theoretical foundations and various key technologies like Reinforcement Learning (RL), Transfer Learning (TL), and Imitation Learning (IL) , this review specifically concentrates on the "recent advances" aspect of RL in the multi-robot collaboration context. It aims to bridge the gap between MARL research and its practical application in multi-robot systems, building upon efforts to create scalable emulation platforms for Multi-Robot Reinforcement Learning (MRRL) that allow for training in simulation and evaluation in real-world systems .
The primary objective of this survey is to offer a comprehensive overview of Multi-Agent Deep Reinforcement Learning (MADRL) for multi-robot systems, highlighting key methodological challenges and emerging approaches. This includes a detailed analysis of recent developments such as attention mechanisms and advanced MADRL algorithms . Furthermore, the survey explores practical applications across various domains, including navigation, cooperative manipulation, and distributed task allocation, while also considering crucial aspects like human-robot interaction, scalability, robustness, and emerging trends such as blockchain integration and edge computing . By meticulously classifying reviewed papers based on their multi-robot applications and providing insights into potential future developments, this survey aims to significantly advance the current state-of-the-art and inspire future research directions within multi-robot collaborative decision-making .
2. Fundamentals of Reinforcement Learning for Multi-Robot Systems
This section lays the groundwork for understanding the application of Reinforcement Learning (RL) in Multi-Robot Systems (MRS). It begins by defining key terminology essential for comprehending the field, specifically detailing what constitutes an MRS, the concept of Multi-robot Cooperation (MRC), and the broader scope of robot learning. Subsequently, it introduces the core principles of Reinforcement Learning, elaborating on its modeling paradigms, such as Markov Decision Processes (MDPs), and differentiating between model-based and model-free RL approaches. The section then extends these foundational concepts to the multi-agent domain, providing a comprehensive introduction to Multi-Agent Reinforcement Learning (MARL), including its architectural framework and the unique challenges it presents when transitioning from single-agent to multi-agent learning scenarios. This systematic progression from fundamental definitions to the intricacies of MARL establishes a robust theoretical framework for the subsequent discussions on advanced topics and applications in multi-robot collaborative decision-making .
2.1 Background and Key Definitions
This section establishes a foundational understanding of key terms and concepts essential for comprehending the application of Reinforcement Learning (RL) in Multi-Robot Systems (MRS).
Multi-robot systems (MRS) are fundamentally defined as collections of two or more robots that interact to accomplish specific tasks, often emphasizing communication and coordination to leverage collective intelligence . This definition is consistent with other descriptions that characterize an MRS as a group of homogeneous or heterogeneous robots working towards a common objective, aiming for enhanced efficiency, adaptability, and robustness . Mathematically, an MRS can be represented as a tuple (N, S, A, T, R, C, G), encompassing the robot set, state space, action space, transition function, reward function, communication model, and goal function . While some papers implicitly frame an MRS as an environment for robot controllers , the explicit definitions from provide a more holistic view of the system's components and objectives.
Multi-robot Cooperation (MRC) is a critical aspect of MRS, defined as the process where a group of robots shares information and coordinates actions to achieve a common task, typically guided by a common goal function . This aligns closely with the definition of multi-robot coordination, which emphasizes managing multiple robots to work together efficiently and effectively through communication, cooperation, and synchronization to reach a shared objective . The concepts of "coordinated robot" and "multi-robot task allocation," which involves assigning tasks based on capabilities and workload, further elaborate on the practical aspects of MRC within an MRS .
Robot learning is broadly defined as the process by which a robot integrates hardware and software to acquire knowledge or skills through data, experience, or interaction, leading to improved performance. This involves perception, decision-making, and action, with the ultimate goal of autonomous adaptation to novel tasks and environments . Within this context, a robot's strategy is framed as a mapping from state to action, , and the objective of a learning algorithm is to enhance this strategy using collected data .
Reinforcement Learning (RL) is a paradigm where an agent learns through trial-and-error interaction with its environment, evaluating transitions based on scalar reward signals . This learning process enables robots to learn from experience, adapt to dynamic environments, and enhance their performance, making RL a promising approach for multi-robot coordination challenges . While some works focus on specific aspects like Distributed Deep Reinforcement Learning (DDRL) without explicitly defining fundamental RL concepts , or implicitly assume an understanding of these concepts when discussing multi-agent deep reinforcement learning , a comprehensive understanding of core RL components is essential.
In single-agent RL, the learning process is typically modeled as a Markov Decision Process (MDP), which includes states, actions, transition probability functions, reward functions, policies (stochastic or deterministic), discounted return, and action-value functions (Q-functions) . The optimal action-value function, , is governed by the Bellman optimality equation: where represents the state, is the action, is the next state, is the transition probability, is the reward function, and is the discount factor .
RL paradigms are broadly categorized into model-based and model-free methods. Model-based RL explicitly learns or uses a model of the environment's dynamics to plan actions, which can be computationally efficient but relies on the accuracy of the learned model. Conversely, model-free RL directly learns policies or value functions without constructing an explicit environment model, making it more robust to model inaccuracies but often requiring more interaction data. Q-learning, for instance, is a prominent model-free algorithm . In the context of robot control, model-based methods can be advantageous when accurate environmental models are available or can be learned efficiently, allowing for proactive planning and safer exploration. However, their sensitivity to model errors can be a significant weakness in complex, dynamic, or unknown multi-robot environments. Model-free methods, particularly those leveraging deep learning, excel in handling high-dimensional state and action spaces, which are common in robotics, and can learn effective policies in complex scenarios without explicit environmental knowledge. Their primary weakness is often their sample inefficiency, requiring extensive interaction with the environment, which can be time-consuming or resource-intensive for physical robots. Furthermore, the extension of MDPs to multiple agents is known as a Stochastic Game (SG), incorporating states, individual agent actions, joint action sets, state transition probability functions, and individual reward functions for each agent . This adaptation is crucial for understanding multi-agent reinforcement learning (MARL), which addresses coordination and collaboration challenges in MRS by enabling robots to learn and adapt collectively .
2.2 Introduction to Multi-Agent Reinforcement Learning (MARL)
Multi-Agent Reinforcement Learning (MARL) represents the application of Reinforcement Learning (RL) techniques to systems comprising multiple interacting agents . Unlike single-agent RL, where a solitary agent learns to maximize its own cumulative reward in a static environment, MARL necessitates agents to consider and adapt to the behaviors of other agents, which are themselves learning and evolving . This paradigm is crucial for multi-robot coordination, enabling robots to learn, adapt, and improve performance in dynamic, real-world scenarios, encompassing challenges such as communication constraints and environmental adaptability .
The fundamental framework for MARL extends the single-agent Markov Decision Process (MDP) to a Multi-Agent Markov Decision Process (MAMDP), defined as a tuple . Here, denotes the global state space, represents the joint action space of all agents, is the state transition probability function, is the reward function, and is the discount factor. Each agent aims to learn an individual policy to maximize its expected cumulative discounted reward, ultimately seeking an optimal joint policy . This framework can be further extended to Partially Observable MAMDP (MAPOMDP) to account for scenarios where agents have limited information about the global state .
MARL introduces several unique challenges that differentiate it from single-agent RL, primarily due to the interactive and dynamic nature of multi-agent environments. These challenges can be systematically categorized as follows:
-
Non-stationarity: In single-agent RL, the environment is typically considered stationary, meaning its dynamics remain consistent. However, in MARL, the optimal policy for a given agent depends on the policies of other learning agents . As other agents continuously update their strategies, the environment from the perspective of any single agent becomes non-stationary . This makes it challenging for an agent to converge to an optimal policy, as the target is constantly shifting. For instance, in a multi-robot patrol task, if one robot changes its patrol route, the optimal route for another robot might also change.
-
Curse of Dimensionality / Scalability: Single-agent RL already faces the curse of dimensionality, where the state-action space grows exponentially with the number of relevant variables. In MARL, this challenge is compounded because the joint state-action space of the system grows exponentially with the number of agents and their individual state and action spaces . This makes it computationally expensive, if not impossible, to explore the entire joint policy space, especially as the number of robots in a team increases .
-
Credit Assignment Problem: This challenge, implicitly present in MARL, refers to the difficulty of attributing specific actions of individual agents to overall system rewards or penalties, particularly in scenarios involving delayed or sparse rewards. Unlike single-agent RL where an agent directly receives feedback for its actions, in a multi-agent system, the collective reward might be a result of complex interactions among agents over time. It becomes challenging to determine which agent's actions were most responsible for a positive or negative outcome. For example, in a multi-robot construction task, if the structure collapses, identifying which robot's specific action (or lack thereof) contributed to the failure is difficult.
-
Exploration-Exploitation Trade-off: While present in single-agent RL, this trade-off is more complex in MARL. An agent's exploration—trying new actions to discover better policies—can inadvertently destabilize the learning process of other agents, leading to poorer collective performance or even oscillating behaviors . A global exploration strategy is often necessary to ensure effective learning across the multi-agent system .
-
Coordination Mechanisms: The inherent need for agents to coordinate and collaborate distinguishes MARL from single-agent RL . This includes defining clear learning goals for individual agents within a collective objective, managing communication constraints, and addressing potential heterogeneity among agents (e.g., varying capabilities, roles, or resource limitations like battery life) . Effective coordination mechanisms are vital for achieving synergistic behavior and overall system performance.
These challenges collectively underscore the increased complexity of MARL compared to its single-agent counterpart. Addressing them requires novel algorithmic approaches that account for the dynamic, interactive, and often partially observable nature of multi-agent environments.
3. Paradigms of Reinforcement Learning for Multi-Robot Systems
Reinforcement Learning (RL) has emerged as a powerful paradigm for enabling multi-robot systems to achieve complex collaborative decision-making. The architectural choices for applying RL in multi-robot contexts significantly impact system performance, scalability, and robustness.
This section systematically explores the primary paradigms: centralized RL, decentralized RL, and hybrid approaches, particularly Centralized Training with Decentralized Execution (CTDE). Each paradigm presents distinct advantages and disadvantages concerning global optimality, computational complexity, communication requirements, and resilience to failure.
Centralized RL architectures, while theoretically capable of achieving optimal global policies by treating the multi-robot system as a single-agent Markov Decision Process (MDP), face significant practical challenges . The primary hurdle is the "curse of dimensionality," where the joint action-observation space expands exponentially with the number of robots, rendering learning and computation intractable for large-scale systems . Furthermore, a centralized controller introduces a single point of failure, compromising system robustness.
Conversely, decentralized RL empowers individual robots to make decisions based primarily on local observations, fostering scalability and robustness . This approach mitigates the computational burden and enhances resilience to individual agent failures, making it widely adopted in multi-robot systems . However, decentralized methods grapple with challenges such as partial observability and non-stationarity, arising from the dynamic interactions and co-adaptation of multiple learning agents within a shared environment . Achieving effective coordination without explicit global communication remains a significant hurdle, potentially leading to sub-optimal global solutions compared to centralized approaches .
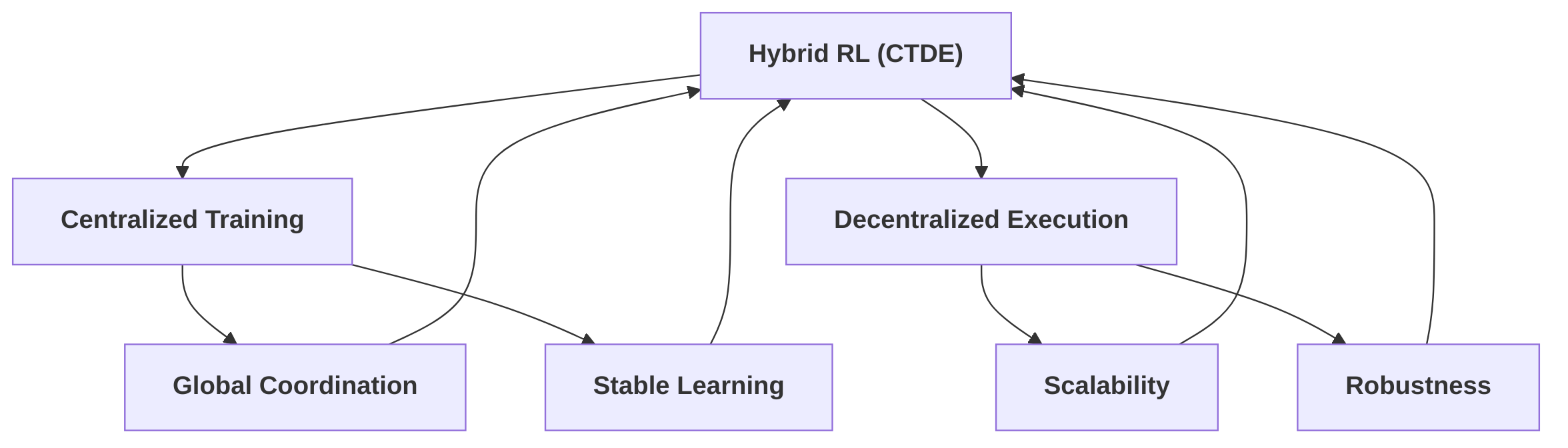
Hybrid approaches, particularly CTDE, represent a compelling synthesis, aiming to capitalize on the strengths of both centralized training and decentralized execution . In CTDE, a centralized component processes global information during the training phase to facilitate coordination and stable learning, addressing issues like non-stationarity and credit assignment . During deployment, however, individual robots execute their learned policies independently, leveraging the benefits of decentralized operation such as scalability and robustness. Key mechanisms within CTDE include centralized critics, which provide global reward signals, and value decomposition methods, which factorize the global Q-function into individual agent contributions, allowing for coordinated policy learning without continuous global oversight during execution . The integration of communication learning and advanced attention mechanisms further enhances information sharing and coordination capabilities within CTDE frameworks . This paradigm effectively balances the pursuit of global optimality with the practical demands of real-world multi-robot deployments, making it a foundational approach in contemporary Multi-Agent Reinforcement Learning (MARL) for multi-robot systems.
3.1 Centralized Reinforcement Learning
Centralized Reinforcement Learning (RL) architectures in multi-robot systems typically involve a single learning agent or controller that observes the complete global state of all robots and the environment, then issues actions for each robot. While the provided digests do not explicitly detail numerous instances of purely centralized RL for multi-robot systems, they implicitly or directly reference its characteristics and implications, primarily by contrasting it with distributed methods or by discussing the "centralized training, decentralized execution" paradigm .
A primary advantage of centralized RL is its potential to achieve optimal global policies, as a single controller can directly optimize the joint actions of all agents to maximize a common return . This means that the system can theoretically reach the highest possible performance by coordinating all robots towards a unified objective. If a centralized controller were available in a fully cooperative stochastic game, the problem could be reduced to a single-agent Markov Decision Process (MDP), which is amenable to established solutions like Q-learning, leveraging learned optimal joint-action values .
However, centralized RL architectures are fraught with significant disadvantages, particularly concerning scalability and robustness. A key limitation is the inherent scalability issue with respect to an increasing number of robots and task complexity. As the number of robots grows, the joint action-observation space expands exponentially, leading to a prohibitive computational burden for the centralized controller to learn and compute optimal policies. This "curse of dimensionality" makes it impractical for large-scale multi-robot systems . Furthermore, centralized control introduces a single point of failure; if the central controller malfunctions or becomes unavailable, the entire multi-robot system can become incapacitated.
The trade-offs between performance and computational complexity are particularly stark in centralized approaches. While offering the theoretical benefit of global optimality, this often comes at the cost of immense computational complexity. Practical limitations often outweigh these theoretical benefits when dealing with real-world multi-robot deployments. For instance, the coordination problem highlighted in cooperative stochastic games, where greedy action selection by individual agents in a decentralized setup can lead to suboptimal joint actions if ties are broken inconsistently, implicitly suggests the need for centralized oversight to enforce globally optimal actions, but this comes with the aforementioned computational challenges .
Despite these limitations, the concept of centralized learning is often leveraged in hybrid paradigms, such as "centralized training, decentralized execution" . In this paradigm, a centralized learner processes global information to train individual policies for each robot, which are then executed decentralizably without continuous global coordination. This approach aims to combine the benefits of global policy optimization during training with the scalability and robustness of decentralized execution during deployment, mitigating some of the inherent drawbacks of fully centralized systems.
3.2 Decentralized Reinforcement Learning
Decentralized reinforcement learning (RL) in multi-robot systems involves individual agents making decisions based primarily on local observations, fostering a paradigm that is inherently distributed and often implemented to handle issues of scalability and robustness . The core principle of decentralized RL, particularly in the context of distributed deep reinforcement learning, centers on agents learning independent policies from their local perspectives . This approach supports efficient distributed learning in complex multi-player multi-agent settings, where each robot adaptively improves its performance over time . In fact, decentralized approaches are widely adopted, with over 92.9% of reviewed multi-robot system (MRS) methods reflecting this independent decision-making assumption .
However, decentralized learning for robot teams is confronted by several common challenges. These include partial observability, where agents only have limited information about the global state, and non-stationarity, arising from the co-adaptation of multiple learning agents within a shared environment . Coordination among agents without explicit communication also poses a significant hurdle, as agents must infer or anticipate the actions of others to achieve collective goals effectively . Furthermore, communication overhead, while potentially reduced in decentralized settings, can still impact system performance if not managed efficiently.
Despite these challenges, decentralized Multi-Agent Reinforcement Learning (MARL) offers substantial benefits, especially in terms of robustness and scalability for large multi-robot systems . The inherent focus on "persistent autonomy" in decentralized systems allows robots to operate effectively without constant centralized control, enhancing their resilience to individual agent failures or communication disruptions . The distributed nature of learning improves overall learning efficiency by reducing the computational burden on any single entity, making it comparable to single-agent Q-learning in some cases .
Common techniques for achieving coordination in decentralized settings, even without explicit communication, often rely on agents observing each other's behaviors and potentially employing shared learning strategies . Approaches like Independent Learning, where each agent optimizes its policy oblivious to others, represent the most basic form of decentralized coordination . More advanced techniques, such as those employing centralized critics or value decomposition, provide mechanisms for agents to coordinate indirectly by leveraging global information during training while maintaining decentralized execution . For instance, CTDE (Centralized Training Decentralized Execution) architectures are specifically designed to overcome limitations like partial observability and non-stationarity in decentralized MRS, leading to more efficient and scalable controllers . While some purely decentralized methods like Distributed Q-learning are computationally efficient, their applicability may be limited to deterministic problems, underscoring the trade-offs between computational complexity and problem generality .
When comparing the performance implications of decentralized decision-making relative to centralized approaches, decentralized methods generally offer superior robustness to failures and enhanced scalability for large numbers of agents . The computational complexity is often reduced, making them more feasible for real-world deployments . However, a potential disadvantage is the risk of sub-optimality, as decentralized agents, operating with limited information and coordination, may not always converge to globally optimal solutions compared to centralized systems that have full access to global state and actions . This trade-off between optimality and practical considerations like scalability and robustness often dictates the choice of architecture in multi-robot collaborative decision-making.
3.3 Hybrid Reinforcement Learning Approaches / Centralized Training with Decentralized Execution (CTDE) Approaches
Hybrid reinforcement learning (RL) architectures integrate elements of both centralized and decentralized control to balance the pursuit of global optimality with the demands of scalability and robustness in multi-agent systems. While purely centralized approaches struggle with scalability as the number of agents increases due to a rapidly expanding state-action space, and purely decentralized methods face challenges such as non-stationarity of the environment from the perspective of individual agents, hybrid approaches aim to mitigate these limitations . A prominent paradigm within hybrid RL is Centralized Training with Decentralized Execution (CTDE), which has become a foundational approach for recent Multi-Agent Reinforcement Learning (MARL) methodologies, particularly in multi-robot systems .
The rationale behind CTDE is to leverage the benefits of global information during the training phase to facilitate coordination and learning, while maintaining the robustness and scalability of independent decision-making during deployment. This bridge between global knowledge and local action enables CTDE to address the inherent challenges of both centralized and decentralized paradigms. During centralized training, agents can access shared observations, communicate, or utilize a global critic to learn coordinated policies, thereby mitigating the issue of non-stationarity that often plagues decentralized learning where individual agents perceive the environment as changing due to the actions of other independent agents. For example, coordination-based methods, such as those employing coordination graphs, decompose a global Q-function into local Q-functions dependent on subsets of agents . This allows for the aggregation of local maximizations to achieve coordinated action selection, effectively combining global information (decomposed Q-values) with decentralized execution (local maximizations) .
Variations of CTDE architectures often involve mechanisms like centralized critics and value decomposition, which are crucial components for enabling distributed learning approaches . Centralized critics, for instance, evaluate the joint actions of all agents during training, providing a global reward signal that helps individual agents learn optimal behaviors. This centralized feedback facilitates more stable and efficient learning by mitigating issues of credit assignment in complex multi-agent interactions. Value decomposition methods, on the other hand, factorize the global Q-function into individual agent contributions, allowing each agent to learn its own Q-function while ensuring that the sum or combination of these local functions approximates the global optimum. This approach facilitates learning coordinated policies even when execution remains decentralized, as the underlying value functions implicitly account for inter-agent dependencies learned during training .
Furthermore, communication learning is emphasized as a key aspect for coordinated policies and decentralized execution within CTDE frameworks . By learning communication protocols during training, agents can exchange relevant information, improving their ability to make coherent decisions when deployed independently. Emerging approaches, such as those incorporating attention mechanisms and advanced multi-agent reinforcement learning algorithms, are frequently associated with CTDE frameworks to enhance information sharing and coordination capabilities . While some research acknowledges the existence of hybrid methods, accounting for a notable percentage of reviewed approaches, further detailed discussion on how these mitigate limitations and their specific mechanisms for information sharing during training and independent action during deployment is still developing . The development of toolboxes for distributed deep reinforcement learning, particularly in multi-player multi-agent systems, further supports the implementation and research into CTDE frameworks, leveraging distributed learning for enhanced efficiency in complex scenarios .
4. Deep Reinforcement Learning Approaches in Multi-Robot Systems
Deep Reinforcement Learning (DRL) has significantly advanced the capabilities of multi-robot systems (MRS) by enabling robots to learn complex behaviors and coordinated strategies in dynamic and partially observable environments.
This section provides a comprehensive overview of the Deep Reinforcement Learning approaches employed in multi-robot collaborative decision-making, highlighting key architectures, algorithmic paradigms, and the inherent challenges that must be addressed for robust real-world deployment.

The first subsection, "MADRL Architectures and Algorithms for Multi-Robot Systems," delves into the foundational concepts of Multi-Agent Deep Reinforcement Learning (MADRL) and its architectural designs. It explains how MADRL overcomes the limitations of traditional Reinforcement Learning in multi-agent settings, particularly concerning the curse of dimensionality and non-stationarity . A particular focus is placed on the Centralized Training Decentralized Execution (CTDE) paradigm, which balances the need for global coordination during training with the practicalities of decentralized decision-making during deployment. Within this paradigm, the subsection examines prominent distributed learning approaches, including independent learning, centralized critics, value decomposition, and communication learning . Specific algorithms like Value Decomposition Networks (VDN) and QMIX are discussed as prime examples of the value decomposition approach, illustrating how they enable cooperative multi-agent learning by decomposing a global Q-function into individual agent contributions or non-linearly combining them while maintaining monotonicity . The discussion extends to how these architectures address the credit assignment problem and non-stationarity, ultimately influencing performance metrics such as success rate, convergence speed, and scalability in multi-robot applications .
Following this, the "Challenges in MADRL for Multi-Robot Systems" subsection comprehensively outlines the significant obstacles hindering the widespread adoption and robust performance of MADRL in multi-robot environments. It critically examines issues such as non-stationarity, which arises from the simultaneous learning of multiple agents and violates fundamental RL assumptions ; scalability, driven by the exponential growth of state-action spaces with increasing agent numbers, leading to the "curse of dimensionality" ; and data inefficiency, a critical concern given the cost and safety implications of real-world data collection . Furthermore, the challenges of partial observability, where agents have limited environmental information, and the complexities of exploration strategies in a multi-agent context are explored . Finally, the subsection addresses the significant hurdles associated with practical deployment and robust evaluation, including communication constraints, unpredictable environments, and the necessity for adaptable and persistently autonomous systems . These challenges are often interdependent, exacerbating the complexity of designing and deploying effective multi-robot collaboration systems.
4.1 MADRL Architectures and Algorithms for Multi-Robot Systems
Multi-Agent Deep Reinforcement Learning (MADRL) represents a significant advancement over traditional Reinforcement Learning (RL) in addressing the complexities of multi-robot systems (MRS). Traditional RL often struggles with the curse of dimensionality and the non-stationary environments inherent in multi-agent settings, where the optimal policy for one agent depends on the evolving policies of others . MADRL, by integrating deep learning components, enhances the capabilities of multi-agent reinforcement learning by enabling agents to process high-dimensional sensory inputs and learn complex, non-linear policies. This allows for more sophisticated decision-making and coordination in dynamic and partially observable multi-robot environments . The integration of deep neural networks facilitates feature extraction and policy approximation, which are critical for scaling RL to real-world multi-robot applications .
Prominent MADRL architectures in multi-robot systems largely fall under the Centralized Training Decentralized Execution (CTDE) paradigm, which aims to leverage global information during training while maintaining decentralized decision-making during execution for scalability and robustness. This paradigm addresses the trade-off between optimal coordination and practical deployability in multi-robot scenarios. Key categories of distributed learning approaches relevant to MADRL in multi-robot systems include independent learning, centralized critics, value decomposition, and communication learning .
While several surveys classify MARL algorithms by task type (cooperative, competitive, mixed) and agent awareness (independent, tracking, aware) , specific MADRL algorithms such as QMIX and VDN (Value Decomposition Networks) exemplify the value decomposition approach within the CTDE framework. These algorithms are designed for cooperative multi-agent tasks where a global reward is shared among agents. VDN postulates that the global Q-function can be additively decomposed into individual agent Q-functions, , where denotes the joint trajectory and the joint action . This additive decomposition simplifies the learning problem by allowing each agent to learn its local Q-function independently, while the sum of these local Q-functions approximates the global Q-function.
QMIX extends VDN by introducing a mixing network that non-linearly combines the individual agent Q-values to produce a joint Q-value, subject to a monotonicity constraint. This constraint ensures that if an individual agent's Q-value increases, the global Q-value also increases, thus preserving the optimal joint action. The mixing network is typically a neural network whose weights are non-negative, ensuring the monotonicity. This architectural choice aims to capture more complex non-linear relationships between individual Q-values while maintaining the benefits of decentralized execution. However, the restrictive monotonicity constraint of QMIX can limit its expressiveness in scenarios involving complex agent interactions where the optimal joint action might not correspond to a simple summation or monotonic combination of individual optimal actions. For instance, in tasks requiring complex negotiation or emergent behaviors, this constraint might prevent the model from learning truly optimal joint policies.
In terms of information sharing, VDN and QMIX both centralize the training process, where the individual Q-functions are learned with access to global state information, or at least a centralized critic that observes all agents' observations and actions. During decentralized execution, each agent only needs its local observation to derive its policy. This contrasts with purely decentralized approaches, such as Independent Q-Learning, where each agent learns its policy without explicit knowledge or coordination with other agents' policies, leading to issues like non-stationarity and suboptimal performance . While centralized approaches offer global optimality, they typically struggle with scalability as the number of agents increases due to the exponential growth of the joint action-observation space . Conversely, decentralized methods improve scalability by reducing computational complexity per agent but face significant challenges in achieving robust coordination and global optimal performance . The CTDE paradigm, through algorithms like QMIX and VDN, attempts to strike a balance, mitigating the scalability issues of fully centralized methods while improving coordination over fully decentralized ones.
The specific performance metrics, such as success rate, convergence speed, and scalability with agent number, vary significantly across different multi-robot scenarios and algorithm implementations. While specific comparative metrics for QMIX and VDN in multi-robot systems are not detailed in the provided digests, general trends can be inferred. Algorithms adopting value decomposition (like VDN and QMIX) typically show improved coordination compared to independent learning methods, leading to higher success rates in cooperative tasks. Their convergence speed can be faster than fully centralized methods for moderate numbers of agents due to reduced complexity during execution. Scalability, a critical factor in MRS, is better addressed by these CTDE approaches than by purely centralized ones, as each robot's policy depends only on its local observations during deployment. This distributed nature for execution is supported by discussions on distributed learning approaches in MADRL, including those focusing on multi-player multi-agent distributed DRL toolboxes for complex environments .
The ability of MADRL algorithms to mitigate challenges in multi-robot systems is directly tied to their architectural designs. Value decomposition methods like VDN and QMIX primarily address the credit assignment problem in cooperative tasks by breaking down the global reward into components attributable to individual agents. They also tackle non-stationarity by training a centralized critic or mixing network that observes the policies of all agents. For instance, in tasks like multi-robot navigation or formation control, VDN and QMIX can achieve coherent team behavior by learning how individual actions contribute to the overall objective. The inclusion of attention mechanisms, as an emerging approach in MADRL for MRS , further enhances coordination by allowing agents to selectively focus on relevant information from other agents or the environment, improving adaptability and decision-making in complex, dynamic scenarios. Ongoing research, such as that conducted at the PeARL lab, continues to advance these approaches for persistent autonomy and robot learning .
4.2 Challenges in MADRL for Multi-Robot Systems
The application of Multi-Agent Deep Reinforcement Learning (MADRL) to multi-robot systems presents a unique set of formidable challenges that impede widespread adoption and robust performance. Key challenges identified include non-stationarity, scalability, data inefficiency, partial observability, and the complexities associated with practical deployment and evaluation .
Non-Stationarity (non_stationarity_handling_defect): This is a fundamental challenge in MARL, particularly evident in multi-robot systems where decentralized learning is prevalent . Non-stationarity arises because each agent's optimal policy depends on the policies of other agents, which are simultaneously learning and evolving. As other agents update their behaviors, the environment from the perspective of a single agent changes, violating the Markov assumption crucial for standard single-agent RL algorithms . This dynamic environment makes it difficult for agents to converge to stable policies, leading to unstable training and suboptimal performance . For instance, in a cooperative task, if one robot suddenly changes its strategy due to learning, other robots, expecting its previous behavior, might fail to coordinate effectively, leading to mission failure. The multi_agent_deep_reinforcement_learning_for_multi_robot_systems_a_survey_of_challenges_and_applications_international_journal_of_environmental_sciences survey explicitly identifies this as a key methodological challenge.
Scalability (scalability_defect): The complexity of MARL increases exponentially with the number of agents and the dimensionality of the state-action space, leading to the "curse of dimensionality" . This challenge is particularly acute in multi-robot systems, which often involve numerous robots interacting in complex environments. Centralized methods, where a single learner controls all agents, suffer from high computational complexity, rendering them impractical for large robot teams. The joint state-action space grows rapidly, where is the number of agents, is the global state space, and is the action space of agent . For instance, a system with 10 robots, each having 5 possible actions, results in joint actions, making exploration and learning computationally prohibitive. While decentralized methods alleviate the computational burden by allowing agents to learn independently, they grapple with the non-stationarity issues discussed previously. The need for a "scalable emulation platform" implicitly underscores this challenge for real-world deployments .
Data Inefficiency (data_inefficiency): MARL algorithms typically require a vast amount of interaction data with the environment to learn effective policies. This data inefficiency is a significant barrier for multi-robot systems, especially in real-world scenarios where data collection can be costly, time-consuming, and potentially dangerous . The state_of_the_art_in_robot_learning_for_multi_robot_collaboration_a_comprehensive_survey survey highlights "data inefficiency" as a key challenge, emphasizing the difficulty of learning from limited data and achieving generalization. This issue often motivates the development of distributed reinforcement learning methods to parallelize data collection and learning processes .
Partial Observability (partial_observability_defect): In many multi-robot scenarios, individual robots have only a partial view of the global state and the actions of other agents . This partial observability introduces significant ambiguity and uncertainty, as agents must infer the true state of the environment and the intentions of their collaborators from limited local observations . The problem is compounded in dynamic environments where communication might be constrained or unreliable . For instance, a robot operating in a cluttered environment might have its sensors blocked, preventing it from observing a collaborating robot or a critical environmental feature, thus leading to suboptimal or conflicting actions. The state_of_the_art_in_robot_learning_for_multi_robot_collaboration_a_comprehensive_survey acknowledges that Multi-Agent Markov Decision Processes (MAMDPs) can be extended to handle partial observability.
Exploration Strategy (exploration_strategy_defect): The exploration-exploitation dilemma is inherently more complex in MARL than in single-agent RL . Agents must not only explore their own action space to discover optimal individual behaviors but also explore the joint action space to understand how their actions affect and are affected by other agents . Excessive or uncoordinated exploration by multiple robots can destabilize the learning process, making it difficult for the system to converge to a cooperative solution. A global exploration strategy is often needed to guide the collective discovery of optimal team behaviors, which can be challenging to design and implement in decentralized systems .
Practical Deployment and Robust Evaluation (evaluation_challenge): Beyond theoretical challenges, the practical deployment of MADRL algorithms in real-world multi-robot systems faces significant hurdles . This includes handling communication constraints, dynamic and unpredictable environments, and ensuring adaptability to unforeseen situations . Moreover, robust evaluation frameworks are crucial to assess the true performance and generalization capabilities of MARL algorithms in complex, real-world scenarios. The what_is_multi_robot_coordination_activeloop survey explicitly identifies "evaluating the performance of MARL algorithms in real-world multi-robot systems" as a key challenge. This necessitates moving beyond simulation-based evaluations to real-world testing, which inherently involves safety concerns and the need for reliable systems. The challenges of "persistent autonomy," including robustness and adaptability, are also highlighted, suggesting a need for systems that can operate reliably over long durations in dynamic conditions . Furthermore, handling agent-specific constraints like limited battery life or restricted mobility adds another layer of complexity to practical deployments .
These challenges are often interdependent. For example, scalability issues are exacerbated by data inefficiency, as larger robot teams require even more data to learn, and non-stationarity makes it harder to learn efficiently. The complexity of multi-robot systems, coupled with the intrinsic difficulties of reinforcement learning, generates new problems that are not present in single-agent scenarios . Addressing these challenges is critical for the advancement of MARL in multi-robot collaborative decision-making, paving the way for more autonomous and robust robotic systems.
5. Solutions and Methodologies for Key MARL Challenges
Multi-Agent Reinforcement Learning (MARL) in multi-robot systems faces several inherent challenges, including effective communication and coordination, handling non-stationarity, ensuring scalability and generalization, and providing robust computational frameworks.

This section delves into the methodologies and solutions proposed to address these critical issues, drawing on recent advances in the field. Effective multi-robot collaboration relies fundamentally on efficient communication, robust coordination, and synchronization . However, the dynamic and interdependent nature of multi-robot environments introduces significant challenges.
To enhance team cohesion and task completion, various communication and coordination mechanisms have been explored. Explicit strategies, such as establishing social conventions and roles, can constrain agent actions to resolve conflicts and predefine acceptable behaviors . Agents can also sequentially select actions and broadcast them to the team, with communication further enabling negotiation of choices . Learning coordination structures online, including social conventions and role assignments, offers a dynamic adaptation to evolving environments . Communication learning approaches are crucial for achieving coordinated policies and decentralized execution by allowing agents to exchange data like state measurements or Q-table portions . While specific protocols like attention or generative models are not always detailed in general surveys , attention mechanisms show promise in processing and prioritizing information from multiple agents, especially in complex multi-robot systems . Critical future directions include developing RL-based methods for adaptive communication protocols and integrating attention mechanisms more deeply into communication architectures, as well as robust communication strategies resilient to varying bandwidth and latency, possibly leveraging decentralized consensus mechanisms.
Non-stationarity, a key challenge in multi-robot systems, arises because the optimal policy for an individual robot shifts as other robots learn and adapt, continuously altering the target function for RL . While widely acknowledged, detailed algorithmic solutions are often less explored . To address this, "agent-aware" approaches, such as opponent modeling, enable agents to track and predict others' behaviors, adapting their own strategies accordingly . This explicit modeling helps maintain a stable learning environment and can enhance robustness, but it incurs significant computational load in large-scale systems . Fictitious Play, though primarily for static tasks, can also inform beliefs about opponents' stationary strategies based on historical actions . Implicit methods like attention mechanisms are also hinted at for filtering relevant information in dynamic environments, though specific RL algorithms are often not detailed . Future research should focus on a systematic comparison of non-stationarity handling techniques' effectiveness and computational efficiency.
Scalability and generalization are crucial for deploying MARL in large-scale and dynamic multi-robot systems, where the "curse of dimensionality" becomes a pervasive challenge . Distributed learning inherently reduces computational complexity, with algorithms like Distributed Q-learning offering scalability in agent numbers . The modularity of multi-agent systems also facilitates agent integration . To enhance generalization, Transfer Learning (TL) leverages knowledge from related tasks to improve data efficiency, while Meta-Learning (ML) allows robots to quickly adapt to novel cooperative tasks by learning from prior experiences . Future work should focus on robust Centralized Training with Decentralized Execution (CTDE) frameworks incorporating partial observability and dynamic team compositions, leveraging meta-learning or domain randomization to enhance generalization and address data inefficiency .
Finally, the development and deployment of Distributed Deep Reinforcement Learning (DDRL) in multi-robot applications are significantly supported by robust toolboxes and frameworks. These tools simplify distributed training, enhance data efficiency, and provide scalable platforms. An important example is a multi-player multi-agent distributed deep reinforcement learning toolbox, designed to minimize modifications from non-distributed RL algorithms and streamline development for multi-agent systems . Another significant platform, SMART, provides a scalable emulation environment for multi-robot reinforcement learning (MRRL), including both simulation and real-world multi-robot systems, bridging the simulation-to-reality gap . Despite their utility, many surveyed papers do not explicitly review or discuss existing DDRL toolboxes, highlighting a gap in comprehensive reviews . Future toolboxes should provide flexible architectures to accommodate various non-stationarity mitigation strategies, allowing researchers to benchmark different techniques within a consistent framework.
5.1 Communication and Coordination Mechanisms
Effective communication and coordination mechanisms are paramount for achieving robust multi-robot collaboration in Reinforcement Learning (RL) systems. Multi-robot coordination fundamentally relies on communication, cooperation, and synchronization among robots . Various approaches to communication and coordination have been explored in advanced Multi-Agent Reinforcement Learning (MARL), aiming to enhance team cohesion and task completion.
One category of coordination mechanisms involves explicit strategies, such as the establishment of social conventions and roles. These mechanisms restrict agents' action choices, thereby resolving potential conflicts or "coordination_challenge_defect" by predefining allowable behaviors or sequences of actions . For instance, agents can sequentially select actions based on an established order and broadcast their selections to the team . The integration of communication with these conventions or roles can further relax assumptions and simplify application, allowing for negotiation of action choices . Furthermore, learning coordination structures online, including social conventions, role assignments, and coordination graph structures, represents a dynamic approach to adapting to evolving environments .
Communication itself is a critical element, serving as a means for agents to exchange relevant data, such as state measurements or portions of Q-tables, to ensure consistency and facilitate joint decision-making . The field widely acknowledges "communication learning approaches" as a significant category within distributed learning methods for multi-agent systems, essential for achieving coordinated policies and decentralized execution . While these approaches are recognized for their potential to create efficient and scalable controllers, specific details on their underlying protocols or mechanisms, such as attention or generative models, are often not extensively elaborated in general surveys . However, "attention mechanisms" are emerging as a promising approach to address challenges in MADRL for multi-robot systems, particularly in processing and prioritizing information from multiple agents .
The impact of communication bandwidth, latency, and reliability on overall system performance is substantial, especially in complex environments where limited communication presents a significant challenge . High latency or unreliable communication can lead to outdated information, increasing the "non_stationarity_handling_defect" as agents operate on stale observations of their teammates' policies. Robust communication protocols, such as those incorporating message prioritization, adaptive data rates, or error correction, can help mitigate these issues by ensuring timely and accurate information exchange. For instance, protocols that dynamically adjust bandwidth based on task criticality can reduce latency for crucial messages while conserving resources for less time-sensitive data.
In terms of mitigating the "non_stationarity_handling_defect," communication protocols can play a vital role. Unlike techniques such as opponent modeling or fictitious play, which primarily make assumptions about other agents' behaviors and may incur high computational loads, communication-based solutions directly address the information asymmetry that contributes to non-stationarity. For example, explicitly communicating policy updates or belief states can keep agents synchronized, reducing the degree of non-stationarity introduced by independent learning. While opponent modeling assumes agents are rational and predictable, and fictitious play assumes agents play best responses to historical average behaviors, learned communication mechanisms can directly convey intentions or planned actions, providing real-time insights that are often more valuable in dynamic, multi-robot environments. However, complex communication protocols themselves can introduce new challenges, such as increased computational overhead for encoding/decoding messages or the potential for communication failures in noisy channels.
Future research directions should focus on developing more sophisticated communication mechanisms. This includes exploring novel RL-based communication methods that learn optimal communication protocols adaptively, rather than relying on pre-defined structures. Investigating how to integrate attention mechanisms more deeply into communication architectures, enabling agents to dynamically focus on salient information from specific teammates, could significantly enhance coordination efficiency. Furthermore, research into robust communication strategies that are resilient to varying bandwidth, latency, and reliability constraints, potentially leveraging decentralized consensus mechanisms, will be crucial for real-world multi-robot deployments. The goal is to move towards communication systems that are not only efficient but also inherently intelligent, contributing to more cohesive and adaptable multi-robot teams.
5.2 Handling Non-Stationarity in Multi-Robot Environments
Non-stationarity presents a significant challenge in multi-robot systems (MRS) learning, primarily because the optimal policy for an individual robot changes as other robots learn and adapt, making the environment dynamic from any single robot's perspective . This dynamic nature hinders stable and convergent learning outcomes, as the target function for reinforcement learning (RL) is continuously shifting . While several reviews acknowledge non-stationarity as a fundamental issue in decentralized MRS and multi-agent reinforcement learning (MARL) , many do not delve into specific algorithms or methodologies designed to explicitly mitigate its effects .
To address non-stationarity, some approaches focus on making agents "agent-aware" by enabling them to track and predict the behaviors of other agents . One prominent technique in this category is opponent modeling. Opponent modeling involves learning explicit or implicit models of other agents' policies and adapting one's own strategy accordingly . For instance, algorithms might use empirical models of strategies, such as the JAL algorithm, to understand and predict the actions of fellow agents. The core assumption behind opponent modeling is that by anticipating others' moves, a robot can maintain a more stable learning environment for itself, even as the collective behavior evolves. This approach contributes to the robustness of collaborative decision-making by allowing robots to exploit suboptimal opponents or better coordinate with competent ones . However, a significant drawback of complex opponent modeling is the increased computational load required to learn and maintain accurate models of multiple agents, which can become prohibitive in large-scale MRS.
Another related concept is Fictitious Play, which is mentioned in the context of static tasks . While generally applied to game theory scenarios where agents iteratively update their beliefs about opponents' strategies based on observed historical play, its principles can be extended. In fictitious play, each agent assumes that other agents play a stationary (though unknown) mixed strategy, which is approximated by the empirical frequencies of their past actions. The agent then selects its best response to this empirical distribution. The key distinction from general opponent modeling is that fictitious play typically assumes a stationary opponent policy, which is approximated over time. In contrast, dynamic opponent modeling aims to track and adapt to non-stationary opponent policies. Therefore, while fictitious play can lead to convergence in certain game-theoretic settings, its direct applicability to highly dynamic multi-robot environments with continuously adapting agents might be limited unless combined with mechanisms to handle the non-stationarity of opponents' true policies.
Beyond explicit opponent modeling, other implicit methods hinted at for managing non-stationarity include the use of attention mechanisms. These mechanisms can help agents filter out irrelevant information and focus on crucial aspects of the dynamic environment, which could implicitly aid in handling the variability introduced by other agents' learning and actions . However, specific RL algorithms that leverage attention for non-stationarity mitigation are not detailed in existing reviews . Furthermore, broad approaches such as "independent learning, centralized critics, value decomposition, and communication learning" are identified as general solutions for decentralized MRS, but their specific contributions to mitigating non-stationarity are not elaborated upon .
In summary, while the challenge of non-stationarity is widely recognized in multi-robot collaborative decision-making, the current literature often identifies the problem without providing detailed comparative analyses of specific RL algorithms designed to counteract it . While opponent modeling offers a promising avenue by allowing agents to explicitly adapt to changing behaviors, it introduces computational overhead. Future research needs to systematically compare the effectiveness, scalability, and computational efficiency of various non-stationarity handling techniques in diverse multi-robot scenarios to ensure more robust and convergent learning outcomes.
5.3 Scalability and Generalization in Large-Scale Multi-Robot Systems
Scalability and generalization are critical for practical deployments of multi-robot systems, particularly in large-scale and dynamic environments . The complexity of multi-agent reinforcement learning (MARL) systems inherently increases with the number of robots, leading to the pervasive "curse of dimensionality" that challenges traditional approaches . This defect, highlighted in Section 4.2, necessitates advanced architectural innovations and learning paradigms to develop efficient and scalable controllers for robot teams .
One primary strategy to address scalability is distributed learning, which inherently reduces computational complexity compared to centralized methods . Algorithms like Distributed Q-learning and FMQ offer exceptions to the curse of dimensionality concerning agent numbers, though their applicability can be restricted, for instance, to deterministic problems in the case of Distributed Q-learning . The inherent modularity of multi-agent systems allows for the straightforward integration of new agents, contributing to a high degree of scalability . Furthermore, the development of scalable emulation platforms, such as SMART, specifically targets the challenges of multi-robot reinforcement learning by facilitating algorithm development and bridging the gap between research and practical deployment .
To enhance generalization, which is crucial for algorithms to adapt to new and dynamic environments beyond training data, several learning paradigms are explored. Transfer Learning (TL) is a prominent method that can significantly improve generalization and mitigate the issue of data inefficiency by leveraging knowledge from related tasks or domains . Similarly, Meta-Learning (ML) enables robots to acquire the ability to quickly adapt to novel cooperative tasks or environments by learning from prior experiences . ML's core aim is to improve learning efficiency and performance when confronted with new tasks, offering a robust solution for dynamic team compositions and unseen scenarios .
While various techniques like independent learning, centralized critics, value decomposition, and communication learning approaches are proposed to achieve scalable controllers , the digests generally lack detailed specific techniques such as graph neural networks, attention mechanisms, or explicit hierarchical RL frameworks for bolstering scalability and generalization. Future research should focus on developing robust Centralized Training with Decentralized Execution (CTDE) frameworks that explicitly incorporate partial observability and dynamic team compositions. This can be achieved by leveraging meta-learning or domain randomization to significantly enhance generalization capabilities and address data inefficiency in large-scale multi-robot systems . Such advancements would directly contribute to overcoming the limitations of traditional MARL approaches in the face of increasing robot numbers and environmental dynamism.
5.4 Toolboxes and Frameworks for DDRL in Multi-Agent Systems
The advancement and deployment of Distributed Deep Reinforcement Learning (DDRL) in multi-agent systems, particularly in multi-robot applications, are significantly accelerated by the availability of robust toolboxes and frameworks. These tools aim to simplify the complexities inherent in distributed training, enhance data efficiency, and provide scalable platforms for research and real-world implementation.
One notable contribution in this domain is the toolbox presented in . This novel multi-player multi-agent distributed deep reinforcement learning toolbox is specifically designed to facilitate the realization of DDRL, particularly for multi-agent systems. A key advantage of this toolbox is its ability to minimize the modifications required from non-distributed versions of reinforcement learning algorithms, thereby streamlining the development process and reducing the barrier to entry for researchers and practitioners . By simplifying the transition from single-agent to multi-agent distributed learning paradigms, this toolbox can significantly accelerate research and deployment of MARL in complex multi-robot applications. Its validation on a complex environment underscores its practical utility . This type of toolbox has the potential to address challenges such as data inefficiency by providing standardized and optimized implementations for distributed learning, which can leverage parallel processing to collect and process data more effectively. This can guide future research by establishing a baseline for comparative studies and facilitating rapid prototyping of new algorithms.
Another significant platform mentioned is SMART, a "scalable emulation platform for multi-robot reinforcement learning (MRRL)" . SMART provides a comprehensive environment that includes both a simulation environment for training and a real-world multi-robot system for performance evaluation. This dual-faceted approach is crucial for bridging the simulation-to-reality gap, a common challenge in multi-robot systems. By offering a unified platform for both virtual prototyping and physical validation, SMART facilitates the entire pipeline of MRRL research and implementation, from algorithm development to real-world deployment. The emphasis on scalability within SMART addresses a critical need in multi-robot applications, where the number of agents can vary significantly, requiring robust solutions that maintain performance as system complexity increases.
While these toolboxes and platforms offer substantial advantages in accelerating MARL research, it is important to acknowledge that several surveyed papers do not explicitly review or discuss existing toolboxes and frameworks for DDRL . This highlights a potential gap in comprehensive reviews that specifically focus on the practical implementation tools and platforms available for DDRL in multi-robot contexts. Although some papers, such as the technical report from the Persistent Autonomy and Robot Learning Lab , may reference practical implementations or tools, detailed information on their specific functionalities, advantages, and limitations is often not readily available without full access to the content.
The discussion of challenges like non-stationarity in multi-agent environments necessitates a thorough comparative analysis of solutions provided by or supported by these toolboxes. For instance, techniques like opponent modeling, which involves learning models of other agents' behaviors to predict their actions, contrast sharply with approaches like fictitious play, where agents assume opponents are playing an optimal stationary strategy in response to their historical average actions. Opponent modeling offers a more dynamic and adaptive response to non-stationary environments, allowing agents to explicitly account for the evolving policies of their counterparts. However, this sophistication often comes at the cost of increased computational load and complexity, particularly when the number of agents is large or their behaviors are highly intricate. Fictitious play, while computationally less demanding, operates under a stronger assumption of opponent rationality and convergence to Nash equilibrium, which may not hold in highly dynamic or adversarial multi-robot environments. Toolboxes must provide flexible architectures that can accommodate both types of approaches, allowing researchers to explore the trade-offs between computational cost and adaptability. The potential for toolboxes to integrate modular components for various non-stationarity mitigation strategies would significantly enhance their utility, enabling researchers to benchmark different techniques within a consistent framework.
6. Applications of Reinforcement Learning in Multi-Robot Collaborative Decision-Making

Reinforcement Learning (RL) and Multi-Agent Reinforcement Learning (MARL) are instrumental in advancing multi-robot collaborative decision-making across a wide spectrum of applications, ranging from structured environments like warehouse logistics and manufacturing to unstructured and hazardous areas such as deep-sea exploration and disaster response . These techniques enable robot teams to achieve complex collective behaviors, enhance efficiency, and ensure adaptability in dynamic and uncertain settings.
This section provides a comprehensive overview of how RL and MARL are applied in key multi-robot domains, highlighting their unique advantages, specific implementations, and remaining challenges.
The first subsection, "Collaborative Exploration and Mapping," discusses the use of MARL for autonomous discovery and mapping of unknown environments, emphasizing the role of different architectural choices—centralized, decentralized, and Centralized Training Decentralized Execution (CTDE)—in balancing scalability and optimality. It identifies the need for more detailed examples of reward functions and communication strategies to facilitate efficient coverage and map generation .

The second subsection, "Multi-Robot Task Allocation and Scheduling," explores how MARL addresses the complexities of optimizing resource utilization and enhancing operational efficiency in dynamic multi-robot scenarios. It contrasts MARL's adaptive learning capabilities with the limitations of traditional optimization methods, particularly in automated manufacturing and logistics. A significant gap is identified in the literature regarding specific methodological details of MARL implementation for dynamic task allocation, including the impact of various reward structures and how robot capabilities, task priorities, and environmental constraints are accounted for .
"Collaborative Manipulation and Assembly," the third subsection, focuses on the precise coordination required among robots in shared workspaces for tasks like assembly and material handling. It highlights challenges such as collision avoidance and force control, and underscores MARL's potential for enabling implicit coordination without explicit communication. However, the subsection notes a lack of detailed analyses in existing surveys concerning how specific MARL methodologies address these unique challenges, calling for more empirical studies on various MARL architectures in physically interactive multi-robot applications .

Finally, "Swarm Robotics and Collective Behavior" examines how MARL drives the development of sophisticated collective behaviors and persistent autonomy in robot swarms. It discusses the transition from individual learning to complex group dynamics through decentralized control and local interactions, emphasizing the concept of "persistent autonomy." This subsection identifies a critical challenge in large-scale decentralized MARL for swarm robotics: the limitations of value decomposition methods for credit assignment in emergent behaviors. It proposes hierarchical credit assignment and attention-based mechanisms as promising directions to more accurately attribute collective success to individual actions, thereby enhancing the robustness and adaptability of multi-robot swarm systems .
Overall, this section synthesizes the current state of RL and MARL applications in multi-robot collaborative decision-making, highlighting both their successes and the significant research gaps that need to be addressed for further advancement. These challenges primarily revolve around developing more effective reward functions, robust communication strategies, scalable architectures, and precise credit assignment mechanisms to enable true emergent intelligence and persistent autonomy in complex multi-robot systems. Future research should prioritize detailed empirical studies and the development of novel algorithmic solutions to bridge these gaps.
6.1 Collaborative Exploration and Mapping
Multi-robot systems leverage Reinforcement Learning (RL) and Multi-Agent Reinforcement Learning (MARL) to address complex collaborative decision-making problems across diverse application domains. Key areas include multi-robot navigation, cooperative manipulation, and distributed task allocation . Furthermore, these techniques find utility in disaster response, environmental monitoring, search and rescue operations, automated manufacturing, and last-mile delivery, where coordinated teams are essential for efficient coverage and task completion . Applications span structured environments such as warehouse logistics and manufacturing, semi-structured settings like automated agriculture, and unstructured or hazardous areas including deep-sea exploration, underground caves, and outer space .
In the context of collaborative exploration and mapping, MARL techniques are crucial for enabling robots to autonomously discover and map unknown environments over extended periods . While numerous surveys acknowledge the application of MARL in these fields, specific methodologies and detailed examples concerning reward functions or communication strategies for efficient coverage and map generation are frequently not elaborated . This highlights a gap in providing concrete examples of how MARL contributes to problems like exploring unknown territories or generating concurrent maps.
The employment of specific MARL architectures—centralized, decentralized, or Centralized Training Decentralized Execution (CTDE)—is dictated by the inherent trade-offs in collaborative exploration and mapping. Centralized approaches, while capable of optimal global coordination, suffer from scalability issues and single points of failure, making them less suitable for large-scale or dynamic exploration environments where robustness is paramount. Decentralized policies offer increased robustness and scalability, as each robot makes decisions independently based on local observations, but they often struggle with achieving global optimality due to limited information sharing and potential for sub-optimal local optima. CTDE architectures are particularly well-suited for collaborative exploration and mapping because they combine the benefits of both: global knowledge during training facilitates coordinated learning, while decentralized execution enables robust and scalable deployment in real-world scenarios. This allows robots to learn complex collaborative behaviors, such as intelligent area coverage or information fusion for map building, by sharing critical information during the training phase without incurring communication overhead or relying on a central authority during deployment. The integration of advanced techniques like explicit communication protocols and coordination mechanisms within these architectures further enhances their suitability, enabling robots to effectively exchange map information, coordinate exploration paths, and avoid redundant coverage or conflicts.
Key challenges in collaborative exploration and mapping using MARL include designing effective reward functions that incentivize efficient coverage and accurate map generation, developing robust communication strategies to handle noisy or intermittent connections, and ensuring scalability for large robot teams and complex environments. Addressing these challenges is crucial for advancing the capabilities of multi-robot systems in various real-world applications.
6.2 Multi-Robot Task Allocation and Scheduling
Multi-robot task allocation (MRTA) and scheduling are critical for optimizing resource utilization, enhancing operational efficiency, and enabling adaptability in dynamic environments within multi-robot systems (MRS) . Traditional optimization methods often struggle in complex, dynamic, and uncertain multi-robot scenarios due to their reliance on predefined models and computational intensity for re-planning in response to environmental changes. In contrast, Multi-Agent Reinforcement Learning (MARL) offers a robust paradigm for enabling adaptive and efficient task allocation and scheduling by allowing robots to learn optimal strategies through iterative interactions with their environment. This adaptability is particularly valuable in applications such as automated manufacturing and logistics, where robots collaboratively assemble products, transport goods, and manage inventory to boost productivity and reduce labor costs .
However, a comprehensive review of existing literature reveals a notable gap in specific methodological details regarding the application of MARL to dynamic MRTA and scheduling. While several surveys acknowledge distributed task allocation as a critical application area, they often do not provide concrete examples or elaborate on how MARL techniques are specifically implemented to address the complexities of dynamic environments, or why these techniques are uniquely suited for such challenges . For instance, general discussions on MRS applications in manufacturing and logistics highlight the importance of efficient task assignment based on robot capabilities, workload, and proximity, but they do not detail the specific MARL algorithms or reward structures employed to achieve this efficiency in dynamic settings . Key considerations such as the impact of various reward structures on task assignment effectiveness, or how specific MARL techniques account for robot capabilities, task priorities, and environmental constraints, are often not thoroughly addressed in these broad reviews . This indicates a need for more focused research and discussion on the practical implementation and comparative advantages of MARL in dynamic multi-robot task allocation and scheduling.
6.3 Collaborative Manipulation and Assembly
The application of Multi-Agent Reinforcement Learning (MARL) in collaborative manipulation and assembly tasks necessitates precise coordination among robots, particularly given challenges such as shared workspaces, collision avoidance, and the requirement for precise force control. These tasks demand complex cooperative behaviors, where robots must learn to interact physically with objects and each other in a highly synchronized manner. While several surveys acknowledge "automated manufacturing" or "cooperative manipulation" as relevant application areas for multi-robot systems and robot learning , a detailed analysis of how MARL specifically addresses the unique challenges of collaborative manipulation and assembly remains largely undiscussed in the provided literature .
Current review papers primarily focus on broader multi-robot applications such as path planning, pattern formation, pursuit-evasion, information collection, and object transportation, without delving into the specific MARL methodologies for complex, physically interactive tasks like assembly or the precise coordination mechanisms required . The effectiveness of MARL in these domains stems from its ability to enable decentralized learning of policies that account for inter-robot dependencies and environmental dynamics. For instance, in a shared workspace, MARL can facilitate the emergence of collision avoidance strategies through learned penalty signals for undesirable proximity or contact. Precise force control, crucial for delicate assembly, could be achieved by integrating force feedback into the MARL observation space and designing reward functions that penalize deviations from target force profiles.
The critical analysis of how MARL techniques address coordination challenges in collaborative manipulation highlights the potential for agents to learn implicit coordination strategies without explicit communication protocols. This is particularly effective why they are effective for tasks requiring precise physical interaction because MARL can adapt to unforeseen dynamic changes and uncertainties inherent in real-world manipulation. However, the absence of detailed case studies in the provided digests on specific MARL architectures (e.g., centralized training with decentralized execution, or fully decentralized methods) for collaborative manipulation prevents a deeper evaluation of their comparative effectiveness and limitations in managing coordination, shared workspaces, collision avoidance, and precise force control. Future research should delineate specific MARL frameworks and their empirical performance in these challenging, physically grounded multi-robot applications.
6.4 Swarm Robotics and Collective Behavior
Recent advancements in Multi-Agent Reinforcement Learning (MARL) have significantly propelled the development of persistent autonomy and advanced robot learning, particularly in the domain of swarm robotics . MARL's capacity for fostering cooperation in multi-agent environments directly translates to achieving sophisticated collective behaviors in robot swarms through coordinated strategies . This paradigm shift moves beyond individual robot capabilities, enabling the emergence of complex group dynamics from local interactions and decentralized control, which are crucial for global objectives in large-scale multi-robot systems. The concept of "persistent autonomy," where swarms maintain operational integrity and task accomplishment over extended periods without constant human intervention, is a direct implication of these MARL advancements .
While existing surveys acknowledge the potential for advanced multi-robot systems and intelligent swarm behaviors, they often fall short of detailing the specific application of MARL principles to achieve emergent collective behaviors in large swarms. For instance, some surveys highlight applications like "search and rescue" that could involve swarm behavior , or illustrate pattern formation with multiple robots, a clear visual representation of collective behavior . However, they do not elaborate on how MARL mechanisms facilitate the transition from individual learning to these complex group dynamics through decentralized control and local interactions . Similarly, while "robotic teams" and "distributed control" are identified as relevant application domains for multi-agent systems, the precise methodologies for achieving emergent collective behaviors in large swarms through MARL are not extensively covered .
Despite these advancements, a significant challenge in large-scale decentralized MARL teams for swarm robotics lies in the limitations of value decomposition methods for credit assignment. These methods often struggle to accurately attribute collective success to individual actions, particularly in emergent scenarios where behaviors are not explicitly programmed but arise from complex interactions. To address this, concrete algorithmic directions are needed. One promising avenue is the exploration of hierarchical credit assignment, where credit can be distributed at different levels of abstraction—from individual agent contributions to sub-group or overall swarm performance. Another critical direction involves developing novel attention-based mechanisms. These mechanisms could enable individual agents to selectively focus on relevant actions or observations of other agents, thereby attributing collective success more effectively. By leveraging attention, the system could learn to identify which individual or group actions were most instrumental in achieving a global objective, thus providing a more granular and accurate form of credit assignment in emergent, large-scale swarm behaviors. Such advancements are crucial for developing robust and adaptable multi-robot systems capable of executing complex tasks in dynamic and unpredictable environments.
7. Future Directions and Open Challenges

The advancement of Multi-Agent Reinforcement Learning (MARL) in multi-robot systems (MRS) presents significant opportunities but is concurrently challenged by inherent complexities and practical constraints. This section provides a comprehensive overview of the current open challenges and promising future research directions, alongside a critical examination of the ethical implications and societal impacts of these emerging technologies.
The first major aspect to address involves the Open Challenges in MARL for Multi-Robot Systems, which collectively impede robust and widespread adoption. A fundamental hurdle is non-stationarity, stemming from the interdependent and simultaneous learning of multiple agents, leading to dynamic optimal policies and unstable convergence . This is closely linked to the scalability defect, where centralized MARL methods face exponential computational complexity, while decentralized approaches introduce non-stationarity issues, limiting applications to smaller robot teams . Data inefficiency is another critical concern, as deep reinforcement learning requires extensive data, which is costly and difficult to acquire in real-world multi-robot scenarios, exacerbating non-stationarity and hindering adaptation . Furthermore, partial observability due to limited sensor data and communication constraints leads to sub-optimal collective behaviors and coordination failures in decentralized systems . The heterogeneity of agents, with diverse capabilities and roles, complicates policy learning and credit assignment . Finally, the absence of standardized evaluation frameworks hinders rigorous comparison and progress in the field, necessitating comprehensive metrics beyond mere task success to include robustness, adaptability, and communication efficiency .
Addressing these challenges informs the Promising Research Directions. Future work should prioritize developing robust Centralized Training with Decentralized Execution (CTDE) frameworks that effectively mitigate non-stationarity and partial observability, incorporating techniques like meta-learning or domain randomization to enhance generalization and data efficiency . Efficient and robust communication protocols that adapt dynamically to task context are crucial for improved coordination . Enhancing sample efficiency through advanced exploration strategies and effective sim-to-real transfer learning is also vital, supported by dedicated platforms . Proposing novel credit assignment mechanisms, possibly leveraging game theory or causal inference, will be essential for large-scale decentralized teams and emergent behaviors . Furthermore, improving interpretability by explaining learned policies and building ethically aligned MARL systems from the outset are critical research avenues . Finally, the development of sophisticated simulation environments and formal verification methods, along with the integration of large language models for enhanced human-robot interaction, will be key to achieving persistent autonomy in multi-robot systems .
The final crucial aspect concerns Ethical Considerations and Societal Impact. Despite significant technical progress, there is a notable gap in dedicated discussions on ethical implications within existing literature . As multi-robot systems become more pervasive, concerns such as accountability in case of failure, potential impact on employment, bias in decision-making, and the need for robust safety, transparency, and explainability become paramount. Integrating principles of responsible AI and fostering interdisciplinary collaboration among researchers, ethicists, and policymakers are essential to ensure these transformative technologies are developed and deployed responsibly.
7.1 Open Challenges in MARL for Multi-Robot Systems
The widespread adoption and robust performance of Multi-Agent Reinforcement Learning (MARL) in multi-robot systems (MRS) are significantly hindered by several critical open challenges. These challenges stem from the inherent complexity of multi-agent interactions, the dynamic nature of robotic environments, and the practical constraints of real-world deployment. A comprehensive understanding of these issues is crucial for advancing the field.
One pervasive challenge is non-stationarity, explicitly identified by several surveys as a fundamental hurdle in MARL for multi-robot systems . The root cause of non-stationarity is the simultaneous and interdependent learning of multiple agents; as one agent updates its policy, the optimal policies of other agents may change, rendering the environment dynamic from any single agent's perspective. This phenomenon complicates the convergence of learning algorithms, as the underlying optimal policy is constantly shifting. For practical deployment, non-stationarity leads to unstable learning, poor performance generalization, and difficulties in achieving coordinated behaviors, particularly in dynamic environments .
Closely related to non-stationarity is the scalability defect, a critical concern for MARL in MRS. Centralized MARL methods, while potentially offering global optimality, suffer from computational complexity that scales exponentially with the number of agents and the state-action space, rendering them impractical for large-scale multi-robot systems (as discussed in section 3.1). This "curse of dimensionality" is explicitly highlighted as a key challenge . Decentralized methods (as discussed in section 3.2), while addressing the computational burden of centralized approaches, introduce non-stationarity issues due to independent learning without explicit coordination mechanisms . The implications for practical deployment are significant: limited scalability restricts MARL applications to small teams of robots, failing to leverage the full potential of large-scale multi-robot collaboration.
Data inefficiency is another prominent challenge, frequently cited as a key motivator for distributed learning paradigms in MRS . Deep reinforcement learning algorithms typically require vast amounts of interaction data to learn effective policies. In multi-robot systems, collecting such data, especially in real-world scenarios, is time-consuming, expensive, and potentially hazardous. This data scarcity exacerbates the non-stationarity problem by slowing down adaptation to changing policies of other agents. The term "global exploration strategy" also implicitly relates to efficient data collection, aiming to reduce the samples needed to explore the complex joint action space . Improving sample efficiency would directly mitigate non-stationarity issues by enabling faster adaptation to environmental changes and other agents' policies.
Partial observability is a fundamental challenge for decentralized multi-robot systems using model-free MARL . Robots often possess limited local perception, having access only to their own sensor data and potentially restricted communication with neighbors. This incomplete information about the global state or the intentions of other robots complicates decision-making and coordination. The root cause is sensor limitations and communication constraints . Its implications include sub-optimal collective behaviors and increased risk of collisions or task failures due to misunderstanding the environment or other agents. Better communication mechanisms between robots could significantly reduce the burden of local perception, allowing agents to share critical information and infer a more complete understanding of the global state, thereby addressing partial observability.
Furthermore, heterogeneity of agents poses a considerable challenge . Robots in a team may have diverse capabilities, limited battery life, restricted mobility, or distinct roles . Developing a single MARL framework that effectively accounts for and leverages these differences is complex. This heterogeneity complicates credit assignment, policy learning, and overall coordination.
The absence of standardized and comprehensive evaluation frameworks for MARL in multi-robot systems is a significant impediment to progress . Unlike single-agent RL, where benchmarks like OpenAI Gym facilitate comparisons, MARL for MRS lacks universally accepted metrics and simulation scenarios. This makes rigorous comparison of different approaches challenging and hinders the identification of truly superior algorithms. Future research needs to propose specific metrics that capture not only task success but also robustness, adaptability, communication efficiency, and energy consumption in multi-robot contexts. Simulation scenarios should encompass diverse environmental complexities, robot heterogeneity, and dynamic task requirements to provide a realistic assessment of algorithm performance. For instance, metrics could include:
- Collective Reward/Success Rate: Overall task achievement.
- Individual Contribution Metrics: How each robot contributes to the collective goal.
- Robustness to Failures: Performance degradation under agent failures or noisy communication.
- Adaptation Speed: How quickly the team adapts to sudden environmental changes or new agents.
- Communication Load: Bandwidth and latency requirements.
In summary, the interdependencies among these challenges are profound. For example, improved sample efficiency can accelerate learning, thereby aiding in adapting to non-stationarity. More robust communication mechanisms can alleviate partial observability, which in turn might simplify the learning problem by providing richer state information. Addressing these challenges requires holistic approaches that consider their interconnectedness, moving beyond isolated solutions to foster truly robust and deployable MARL systems for multi-robot collaboration.
7.2 Promising Research Directions
Future research in multi-robot collaborative decision-making is poised to address critical challenges, building upon current advancements and integrating interdisciplinary insights. A primary focus should be on developing robust Centralized Training with Decentralized Execution (CTDE) frameworks that effectively handle non-stationarity and partial observability, which are pervasive issues in real-world multi-robot systems . To enhance generalization and mitigate data inefficiency, techniques such as meta-learning or domain randomization should be incorporated into these CTDE frameworks, especially given the data inefficiency challenge highlighted in distributed deep reinforcement learning . Meta-learning, while promising for adapting to new environments, faces limitations in handling extreme domain shifts and can incur significant computational costs during meta-policy training. Domain randomization, conversely, provides a systematic way to generate diverse training data, thereby improving generalization, but its effectiveness depends on accurately modeling the range of potential real-world variations.
Another critical area involves investigating efficient and robust communication protocols within CTDE paradigms. Such protocols should dynamically adapt based on task context and uncertainty, addressing coordination challenges hinted at by "communication learning approaches" . This aligns with the broader goal of enhancing coordination and collaboration through advanced communication protocols and hierarchical learning architectures . Furthermore, enhancing Multi-Agent Reinforcement Learning (MARL) sample efficiency for robot teams is paramount, particularly through efficient exploration strategies or effective sim-to-real transfer learning, directly addressing a core challenge identified in distributed deep reinforcement learning . The development and release of platforms like the multi-player multi-agent distributed deep reinforcement learning toolbox and the SMART platform for scalable emulation serve as crucial resources to bridge the gap between research and practical application, facilitating robust algorithm development and testing in realistic settings.
Proposing novel credit assignment mechanisms for large-scale decentralized teams is also vital, especially for emergent behaviors, to overcome the limitations of current value decomposition methods . Leveraging principles from game theory, for instance, can lead to more robust coordination strategies in adversarial multi-robot scenarios, as MARL itself represents a fusion of temporal-difference reinforcement learning, game theory, and policy search . Investigating causal inference for improved credit assignment in highly cooperative tasks, building on recent advancements in causal reinforcement learning, offers a pathway to more interpretable and effective multi-robot systems .
Addressing the current gap in interpretability is another critical direction. Research should focus on methods to visualize or explain the learned policies of Multi-Agent Deep Reinforcement Learning (MADRL) agents. This could involve analyzing attention weights in transformer-based MADRL architectures, as attention mechanisms have been identified as an emerging approach to address challenges , or employing rule extraction techniques to derive human-understandable policies.
Beyond technical performance, building ethically aligned MARL systems is an imperative research area. This involves proposing research on how to integrate ethical considerations directly into the design and training of MARL algorithms, ensuring that multi-robot systems operate responsibly and align with human values. Furthermore, the integration of causal inference can contribute to increased interpretability and better joint decision-making, which can indirectly support ethical alignment .
Finally, the need for more sophisticated simulation environments that accurately model real-world complexities and facilitate robust sim-to-real transfer is paramount, drawing inspiration from fields like physics-informed machine learning. This will enable rigorous testing and validation of MARL algorithms before real-world deployment. Complementing this, research on formal verification methods for ensuring safety and predictability in MARL-controlled multi-robot systems is crucial. The potential of large language models (LLMs) for understanding and executing complex instructions, improving human-robot interactions, and enabling more natural and efficient robot communication also represents a promising avenue . Such advancements, particularly in robust and scalable MARL algorithms, will enable long-term, autonomous operation of multi-robot systems even in dynamic or constrained environments, pushing towards persistent autonomy .
7.3 Ethical Considerations and Societal Impact
While the technical advancements in multi-robot collaborative decision-making driven by Reinforcement Learning (RL) are significant, it is imperative to address the profound ethical implications and societal impacts associated with their development and deployment. A review of existing literature, including prominent surveys on distributed deep reinforcement learning and multi-agent reinforcement learning for multi-robot systems, reveals a notable gap in dedicated discussions concerning these critical non-technical aspects . One notable exception briefly acknowledges the ethical implications and the need for responsible development, yet it stops short of providing specific discussions on crucial concerns such as safety, accountability, or job displacement .
The advent of highly autonomous multi-robot systems necessitates critical reflection on the responsibilities of researchers and developers. As these systems become more integrated into various sectors, their societal footprint will expand, presenting both significant benefits and potential risks. In logistics, multi-robot systems can optimize supply chains and improve efficiency, but also raise concerns about workforce displacement. In healthcare, collaborative robots could assist in complex surgeries or patient care, yet questions of accountability in case of errors become paramount. During disaster response, autonomous multi-robot teams can perform dangerous tasks, saving human lives, but their deployment must be framed within ethical guidelines to ensure their actions align with humanitarian principles and do not inadvertently cause harm.
Drawing from the broader discourse on autonomous systems and artificial intelligence, several common ethical concerns emerge as critical areas for future research in multi-robot collaboration. These include: \begin{itemize} \item \textbf{Accountability in Case of Failure:} Determining liability when a multi-robot system malfunctions or causes harm is complex, especially given the distributed nature of decision-making in MARL. Clear frameworks are needed to assign responsibility among designers, operators, and the agents themselves. \item \textbf{Impact on Employment:} The increasing automation powered by multi-robot systems may lead to significant shifts in labor markets, requiring proactive strategies for reskilling and re-employment to mitigate negative societal impacts. \item \textbf{Bias in Decision-Making:} If the data used to train MARL systems contains biases, the resulting robotic behaviors can perpetuate or even amplify societal inequalities. Ensuring fairness and transparency in training data and algorithmic design is crucial. \item \textbf{Safety and Robustness:} While a technical concern, safety also carries profound ethical implications. Ensuring that multi-robot systems operate reliably and predictably in dynamic and uncertain environments is essential to prevent unintended consequences and build public trust. \item \textbf{Transparency and Explainability:} Understanding how multi-robot systems arrive at their collaborative decisions is vital for auditing, debugging, and ensuring public acceptance. Developing methods to make complex MARL behaviors more interpretable is a significant challenge. \end{itemize} These concerns underscore the need for a concerted effort to research how to build ethically aligned MARL systems. Integrating principles of responsible AI from the outset of development, and fostering interdisciplinary collaboration between AI researchers, ethicists, policymakers, and societal stakeholders, will be crucial to navigate the complex ethical landscape of advanced multi-robot collaboration and ensure that these transformative technologies serve humanity responsibly.
8. Conclusion
This survey has systematically reviewed the recent advances of Reinforcement Learning (RL) and Multi-Agent Deep Reinforcement Learning (MADRL) in multi-robot collaborative decision-making, highlighting their critical role in enhancing the efficiency and effectiveness of multi-robot systems across diverse applications . The comprehensive review encompassed various algorithms and categorized them by task type and agent awareness, underscoring the benefits of MARL, such as accelerated computation through parallelism, experience sharing, and inherent robustness and scalability .
A central contribution of this survey is the detailed exposition of how MADRL addresses coordination and collaboration challenges in multi-robot systems, enabling applications across various domains . Specifically, the application of distributed Multi-Agent Reinforcement Learning (MARL) has been shown to devise efficient and scalable controllers for multi-robot systems, building upon paradigms such as Centralized Training with Decentralized Execution (CTDE), independent learning, centralized critics, value decomposition, and communication learning . Tools like the multi-player multi-agent distributed deep reinforcement learning toolbox further facilitate research and development in this domain . The survey also provided insights into how deep reinforcement learning techniques are integrated into multi-robot applications, aiming to advance the state-of-the-art in MADRL for this context .
Despite significant progress, several key challenges persist in the field. These include defining precise learning goals, managing non-stationarity in dynamic environments, addressing the curse of dimensionality, and ensuring effective global exploration strategies . Scalability, safety, and reliability also remain critical areas requiring further research and development in MADRL for multi-robot systems . While current methods achieve good results in customized tasks, they still face limitations in generalization and restricted operational conditions .
Looking ahead, the future of multi-robot collaborative decision-making with RL and MADRL is promising. Important open questions revolve around developing algorithms that can effectively balance stability and adaptation, alongside improving performance in the face of existing challenges . Future research directions include leveraging Large Language Models (LLMs) for complex instructions and interactions, combining various machine learning techniques for enhanced flexibility, incorporating causal inference for improved interpretability, and reducing energy consumption . The increasing frequency of interactions between robots and their environment solidifies robot learning as a pivotal research area . Platforms like SMART are crucial in bridging the gap between MARL research and practical applications by facilitating both training and real-world evaluation, thereby accelerating the deployment of multi-robot coordination technologies . This survey aims to serve as a valuable resource for researchers and practitioners, guiding future work and shaping the continued evolution of this dynamic field .
References
Multi-Agent Deep Reinforcement Learning For Multi-Robot Systems: A Survey Of Challenges And Applications | International Journal of Environmental Sciences https://theaspd.com/index.php/ijes/article/view/435
What is Multi-Robot Coordination - Activeloop https://www.activeloop.ai/resources/glossary/multi-robot-coordination/
Multi-Agent Deep Reinforcement Learning for Multi-Robot Applications: A Survey - PubMed https://pubmed.ncbi.nlm.nih.gov/37050685/
A comprehensive survey of multi-agent reinforcement learning - Delft Center for Systems and Control https://www.dcsc.tudelft.nl/~bdeschutter/pub/rep/07\_019.pdf
[2204.03516] Distributed Reinforcement Learning for Robot Teams: A Review - arXiv https://arxiv.org/abs/2204.03516
[2412.21088] Advances in Multi-agent Reinforcement Learning: Persistent Autonomy and Robot Learning Lab Report 2024 - arXiv https://arxiv.org/abs/2412.21088
Multi-Agent Deep Reinforcement Learning For Multi-Robot Systems: A Survey Of Challenges And Applications http://theaspd.com/index.php/ijes/article/download/435/373
State-of-the-art in Robot Learning for Multi-Robot Collaboration: A Comprehensive Survey https://arxiv.org/html/2408.11822v1
[2212.00253] Distributed Deep Reinforcement Learning: A Survey and A Multi-Player Multi-Agent Learning Toolbox - arXiv https://arxiv.org/abs/2212.00253