0. A Review of Autonomous Agent Frameworks for Software Testing Automation
1. Introduction: The Evolving Landscape of Software Testing Automation
The field of software testing automation has undergone a significant evolution, moving from rudimentary script-based methods to sophisticated AI-driven solutions. This progression has been necessitated by the inherent inefficiencies and limitations of traditional approaches, particularly their inability to scale, adapt to dynamic changes, and reduce manual overhead . Early automation efforts, reliant on manual script creation, presented considerable challenges in terms of efficiency, scalability, and maintenance, especially in modern development environments characterized by rapid iteration cycles and complex user interfaces .
The current paradigm shift is marked by the rise of autonomous agents, which are intelligent systems capable of perceiving, deciding, and acting to achieve specific objectives within the testing environment . These agents act as "digital coworkers," autonomously generating, executing, and adapting test cases, thereby transcending the constraints of fixed-script automation . Agent-based testing specifically leverages these agents to simulate real-world user behaviors, navigate UIs, interact with components, and validate outcomes, offering a more realistic and comprehensive assessment of system quality, performance, and reliability than conventional methods .
A pivotal driver of this advancement is the synergistic integration of Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) with autonomous agents. LLMs enable agents to understand and generate human-like language, facilitating the creation of end-to-end test cases directly from natural language requirements . RAG further enhances this capability by integrating external knowledge, thereby improving the relevance and accuracy of generated test artifacts . This allows autonomous agents to manage the entire test lifecycle, from planning and generation to execution and refinement, across various platforms, significantly reducing manual effort and enabling intelligent workflows . Frameworks such as LangChain, SuperAGI, Auto-GPT, BabyAGI, and SmythOS are instrumental in abstracting development complexities, enabling a focus on high-level agent behaviors and goals .
This survey provides a comprehensive review of current autonomous agent frameworks for software testing automation, critically evaluating their capabilities and identifying existing gaps. The reviewed literature consistently highlights the limitations of traditional script-based automation in adapting to dynamic application changes and the significant manual overhead involved . The novelty of the discussed solutions lies in their ability to address these issues. For example, Functionize's intelligent test agent uses NLP and ML to create functional UI models and self-healing tests, making automation accessible to non-experts . Similarly, TestRigor and Codoid emphasize how AI agents leverage NLU and Generative AI to simplify test creation and execution, adapting to dynamic changes and reducing manual overhead . This shift aligns with Gartner's prediction that by 2027, 80% of businesses will integrate AI testing tools, signaling a move towards intelligent, proactive systems . The vision of leveraging LLM-based AI agents to automate the entire Software Development Life Cycle (SDLC) through an AI-driven chat interface exemplifies the potential to redefine software engineering paradigms, making them more inclusive, collaborative, and efficient . This collective body of work represents a substantial move toward more adaptive, intelligent, and human-centric approaches to software testing.
1.1 Historical Trajectories of Test Automation
The historical trajectory of software test automation has largely been characterized by a gradual evolution from rudimentary, script-based methodologies to more advanced paradigms, culminating in the emergence of AI-driven solutions. Early approaches to test automation predominantly relied on manual script creation, a method that, while offering initial automation, was fraught with significant limitations .
| Challenge | Description |
|---|---|
| Efficiency | Complex and time-consuming development of scripts. |
| Scalability | Hinders rapid iteration cycles demanded by modern development methodologies (CI/CD). |
| Maintenance Overhead | Brittleness of scripts leads to frequent and extensive revisions due to minor UI or code changes. |
| Adaptability | Struggles to adapt to cross-browser compatibility or modern UIs with dynamically embedded objects. |
| Overall Impact | Difficulty in scaling automation efforts to match the pace of contemporary software innovation. |
Traditional script-based automation presents notable challenges in terms of efficiency, scalability, and maintenance. The development of these scripts is often complex and time-consuming, hindering the rapid iteration cycles demanded by modern software development methodologies like Continuous Integration/Continuous Deployment (CI/CD) . Furthermore, the brittleness inherent in script-based tests leads to considerable maintenance overhead. Minor changes in the user interface or underlying code can render existing scripts obsolete, necessitating frequent and often extensive revisions. This issue is particularly pronounced in environments requiring cross-browser compatibility or involving modern UIs with dynamically embedded objects, where traditional scripts struggle to adapt and maintain reliability . Such limitations underscore the difficulty of scaling traditional automation efforts to match the pace of contemporary software innovation.
In contrast, the advent of AI-driven solutions promises to address many of these long-standing issues. While the provided digests primarily focus on the current and future impact of AI agents in software testing, implicitly, they highlight a pivotal shift away from the constraints of manual scripting towards more adaptable and intelligent automation paradigms . This transition suggests a move towards systems capable of understanding application behavior, adapting to changes, and generating tests with minimal human intervention, thereby offering enhanced efficiency, improved scalability, and reduced maintenance burdens compared to their predecessors. Although specific seminal works laying the groundwork for agent-based testing are not detailed in the provided digests, the broader shift towards AI-centric approaches represents a significant evolutionary step in the field, driven by the persistent challenges of traditional automation and the imperative for faster, more robust testing in a dynamic software landscape.
1.2 Emerging Paradigm: The Rise of Autonomous Agents in Software Testing
The landscape of software testing is undergoing a profound transformation with the emergence of AI agents and agent-based testing. AI agents are broadly understood as intelligent assistants capable of perceiving their environment, making autonomous decisions, and executing actions to achieve specific objectives . In the context of software quality assurance (QA), these agents act as "digital coworkers" that can generate, execute, and adapt test cases, moving beyond the limitations of traditional, fixed-script automation .
Agent-based testing, a specific application of this paradigm, leverages these autonomous software agents to simulate end-user behavior, particularly in complex or distributed computing environments . These agents can mimic real-world user actions, navigate user interfaces (UI), interact with components, and validate outcomes, providing crucial insights into performance, reliability, and overall system quality . By simulating multiple concurrent users and diverse user personas, agent-based testing can identify bottlenecks, evaluate scalability, and detect issues related to responsiveness, resource utilization, and data consistency that are challenging to replicate with conventional methods . This approach offers a more realistic representation of user interactions, considering preferences, browsing patterns, and transaction histories, leading to more accurate and comprehensive testing outcomes while promoting automation and reducing manual effort for continuous testing and early defect detection .
The synergistic relationship between Large Language Models (LLMs), Retrieval-Augmented Generation (RAG), and autonomous agents is a key driver in advancing test automation . LLMs enable agents to understand and generate human-like language, facilitating the creation of end-to-end test cases directly from natural language requirements . Retrieval-Augmented Generation (RAG) further enhances this capability by allowing LLMs to access and integrate external knowledge, thereby improving the relevance and accuracy of generated test artifacts . Autonomous agents, built upon these foundational technologies, can manage the entire test case lifecycle—from planning and generation to execution and refinement based on feedback—significantly reducing manual efforts and enabling intelligent workflows across UI, API, and mobile platforms . Frameworks such as LangChain, SuperAGI, Auto-GPT, BabyAGI, and SmythOS are abstracting development complexity, allowing focus on high-level agent behaviors and goals, and supporting natural language processing, knowledge retrieval, and decision-making for sophisticated AI agent creation .
This survey aims to provide a comprehensive review of current autonomous agent frameworks for software testing automation, critically evaluating their capabilities and identifying existing gaps in the literature. The papers reviewed consistently highlight a common research gap: the limitations of traditional script-based automation in adapting to dynamic application changes and the significant manual overhead involved in test creation and maintenance .
The novelty and significance of the reviewed papers lie in their proposed solutions to these entrenched problems. For instance, Functionize's intelligent test agent addresses the inefficiency of script-based automation by using NLP and an ML Engine to create a functional UI model, enabling plain English test plan creation and self-healing tests, making automation accessible to non-experts . Similarly, TestRigor emphasizes how AI agents leverage Natural Language Understanding (NLU) and Generative AI to simplify test creation and execution, overcoming the technical barriers of traditional methods . Codoid’s perspective underscores how AI agents adapt to dynamic application changes and reduce manual overhead by leveraging ML and NLP to understand applications and make testing decisions on the fly, contributing to reduced errors, improved coverage, and faster time-to-market . The concept of "agentic testing" is positioned as the next evolution, where AI agents augment testers by offloading repetitive, context-heavy tasks, thereby accelerating and simplifying work in complex, non-linear QA environments . These advancements align with Gartner's prediction that by 2027, 80% of businesses will integrate AI testing tools, signifying a shift from reactive, manual processes to intelligent, proactive systems . The vision for leveraging LLM-based AI agents to automate the entire Software Development Life Cycle (SDLC) through an AI-driven chat interface further exemplifies the potential to redefine software engineering paradigms, making them more inclusive, collaborative, and efficient . This collective body of work demonstrates a significant move towards more adaptive, intelligent, and human-centric approaches to software testing, directly confronting the limitations of prior automation paradigms.
2. Fundamentals of Autonomous Agents in Software Testing
The conceptualization of "AI agents" and "agentic AI" in the context of software testing reveals a shared understanding centered on autonomy and intelligent decision-making. An "AI agent" is broadly defined as an intelligent software entity capable of analyzing data, making decisions, and performing tasks without constant human intervention . This includes abilities such as understanding an application's UI or API, spotting bugs, and adapting testing strategies . Similarly, "agentic AI" emphasizes autonomous, AI-driven agents that can make decisions, learn from testing outcomes, and refine strategies without direct human oversight . Both terms underscore a shift from mere automation scripts to systems that exhibit proactive behavior and continuous learning. While "AI agents" can refer to a wider spectrum of intelligent systems, "agentic AI" specifically highlights the capability for self-directed action and strategic refinement in testing scenarios . These agents are often described as digital co-workers or virtual testers, augmenting human capabilities rather than replacing them .
Core attributes defining an autonomous agent within the testing paradigm include autonomy, reactivity, proactivity, and interactivity. Autonomy signifies the ability to work independently, while reactivity refers to responding to the environment and its perceptions. Proactivity involves taking initiative and planning actions, and interactivity allows communication with other agents and humans . Furthermore, these agents possess long-short term memory, enabling them to retain past information and learn from experience; tool usage, allowing them to utilize digital applications for task completion; multi-agent communication for collaboration; and fine-grained symbolic control for following specific instructions . A fundamental characteristic is their operational cycle of "sense–decide–act–learn," where they gather information, evaluate actions, execute tests, and analyze results for continuous improvement .
Specialized tools like testRigor and Functionize operationalize these agent characteristics through advanced mechanisms. Functionize, for example, leverages Natural Language Processing (NLP) to interpret plain English test plans and an ML Engine to construct a UI model. This ML Engine employs "several types of AI" to create a functional model and convert test plans into self-healing tests, demonstrating intelligent decision-making and adaptability . Similarly, testRigor defines AI agents as systems fulfilling specific goals, often guided by an "objective function" or a "reward function" for reinforcement learning agents. They create and execute task lists through data learning, pattern recognition, and decision-making, embodying key features like autonomy, reactivity, proactivity, and interactivity . Both platforms exemplify how UI modeling, NLP capabilities, and adaptive test execution mechanisms are central to implementing agentic behaviors.
The enabling AI and ML technologies for these agents are diverse, fundamentally including Machine Learning (ML), Natural Language Processing (NLP), and Reinforcement Learning (RL) . Self-healing is a crucial capability, where agents automatically fix broken test cases by analyzing application changes and updating scripts without human intervention . Natural Language Processing is vital for test authoring, allowing agents to understand human language for creating and maintaining test cases, even translating requirements into executable tests . Other significant technologies include Computer Vision for UI/UX testing, detecting visual discrepancies, and analyzing user interaction , and Generative AI, which is critical for dynamic test case generation and content creation .
Common architectures for autonomous agent implementations in testing often follow a "sense–decide–act–learn" loop, indicating a continuous feedback mechanism . Agents are broadly categorized into types such as Simple Reflex Agents, Model-based Reflex Agents, Goal-based Agents, Utility-based Agents, and Learning Agents . In software testing, Learning Agents and Goal-Based Agents are particularly prevalent due to the necessity of adapting to evolving environments and achieving specific testing objectives . Regarding AI technologies, the field employs a range from traditional ML to advanced Generative AI. While ML agents excel in analyzing historical data for defect prediction and test optimization, Generative AI and Natural Language Understanding (NLU) are increasingly important for creating dynamic test cases and understanding complex natural language instructions . Deep learning models are used by agentic AI to analyze software architecture and predict potential failure points for maximum test coverage .
Autonomous web agents (AWAs) demonstrate significant applicability across various testing scenarios, particularly for functional, end-to-end, and API testing . Their efficacy is being explored in natural language test case execution, where LLM-powered AWAs are evaluated for their ability to understand natural language instructions and interact with web applications effectively . This highlights their potential for streamlining test script creation and maintenance, improving accessibility for non-technical users in test authoring, and executing complex test scenarios across different application types, including packaged applications like Salesforce, Workday, SAP, Oracle, and Guidewire .
Studies on the fundamentals of autonomous agents in software testing are primarily guided by research questions centered on their effectiveness and limitations. For instance, research explicitly questions the efficacy of LLM-powered autonomous web agents when used as testers, exploring their capabilities in understanding natural language instructions and interacting with web applications . While many papers describe the characteristics and functionalities of AI agents, they often implicitly explore these fundamentals through their general definitions and applications rather than stating explicit research questions or hypotheses . This indicates a field that is largely descriptive in its foundational understanding, focusing on outlining capabilities and potential rather than rigorously testing specific hypotheses about agent behaviors or architectures at a fundamental level.
3. Autonomous Agent Frameworks and Architectures for Software Testing
This section provides a comprehensive overview of autonomous agent frameworks and architectures, categorizing them based on their primary features and target domains to critically evaluate their applicability and efficacy in software testing automation.
We distinguish between specialized AI agent frameworks designed specifically for testing and more general-purpose AI agent frameworks that can be adapted for testing purposes . A key focus is on comparing their approaches to codeless or no-code testing, analyzing how different frameworks facilitate the creation of tests without requiring extensive programming knowledge . Furthermore, the section evaluates the mechanisms employed by these frameworks for self-healing and adaptation to changes within the software under test, a critical capability for reducing maintenance overhead in automated testing . The discussion extends to the pros and cons of multi-agent collaboration, as supported by various frameworks, highlighting its potential for addressing complex testing scenarios .
We delve into the architectural patterns prevalent in both specialized testing tools and general-purpose AI agent frameworks, comparing their strengths and weaknesses concerning extensibility, maintainability, and seamless integration into modern CI/CD pipelines. This includes a critical evaluation of scalability, flexibility, and integration capabilities, analyzing the trade-offs between proprietary, specialized solutions and more general, adaptable open-source frameworks regarding ecosystem support and long-term viability . The subsequent sub-sections will elaborate on these distinctions. "Architectural Patterns in Specialized Testing Tools" will detail the design principles and features of tools like Functionize and testRigor, emphasizing their unique approaches to UI modeling, NLP integration, and self-healing . "General-Purpose AI Agent Frameworks and Their Adaptability to Testing" will then examine frameworks such as AutoGen, SuperAGI, and CrewAI, focusing on their versatility, multi-agent collaboration capabilities, and the necessary customizations for effective software testing applications . This structured approach will culminate in a comparative analysis, offering insights into the strengths, limitations, and optimal application scenarios for each category of framework in the evolving landscape of autonomous software testing.
3.1 Architectural Patterns in Specialized Testing Tools
Specialized autonomous testing tools leverage sophisticated architectural patterns to enable advanced test automation capabilities, notably codeless testing and self-healing. A critical comparison reveals common underlying design principles, primarily focusing on UI modeling and Natural Language Processing (NLP) integration, which fundamentally differentiate these tools from conventional automation frameworks.
Functionize's intelligent test agent exemplifies an architecture driven by NLP and deep learning . It incorporates an NLP component to interpret plain English test plans, converting them into executable tests. This design principle facilitates codeless testing by abstracting away the need for users to write traditional scripting code. Furthermore, Functionize employs a deep learning-based ML Engine to create a functional model of the User Interface (UI), which is crucial for its self-healing capabilities . This ML Engine enables the system to adapt to UI changes autonomously, implying a reactive mechanism to maintain test integrity despite application modifications. The cloud-based execution environment of Functionize suggests an architectural pattern designed for scalability .
Similarly, testRigor operationalizes AI through Generative AI and Natural Language Understanding (NLU) to achieve codeless testing . Users define test cases using natural language prompts, which the AI translates into high-level, executable steps in plain English. This approach significantly reduces the requirement for coding expertise and minimizes test maintenance overhead, as the descriptions are declarative and independent of specific implementation details. TestRigor also features a self-healing mechanism, allowing test scripts to adapt to UI or API changes autonomously by understanding the contextual role of elements, rather than relying on brittle identifiers. For instance, if a button's tag changes, testRigor identifies its function within the application to update the script . While testRigor emphasizes the benefits for maintainability through high-level descriptions, its explicit architectural details regarding UI modeling, scalability, and extensibility beyond its core functionalities are not deeply elaborated .
Other specialized tools exhibit similar patterns. Tools like Browser Use and Skyvern integrate Large Language Models (LLMs) with computer vision for UI testing . Browser Use extracts interactive elements and uses LLMs to determine actions, while Skyvern utilizes a visual parser and a reasoning model to automate workflows on unfamiliar websites . This combination of LLMs and computer vision represents a sophisticated UI modeling approach that aims to eliminate the reliance on brittle UI selectors, thereby enhancing the robustness of automated tests. For self-healing, frameworks like CodeceptJS demonstrate an architectural pattern where HTML and error information are sent to a GPT model to receive updated locators, showcasing a reactive mechanism for test resilience against UI changes . UI TARS and Hercules also employ vision language models for web UI tests and convert Gherkin specifications to executable tests, respectively . SeeAct-ATA and pinATA are described as agents for natural language test case execution, implicitly relying on NLP for test generation and execution, with pinATA being a more advanced implementation that considers design and operational limitations .

The common architectural patterns observed across these specialized tools include:
- NLP/NLU Integration: Nearly all tools, including Functionize and testRigor, integrate NLP or NLU to enable codeless testing by translating natural language inputs into executable test steps. This significantly lowers the barrier to entry for test creation.
- AI-driven UI Modeling: Tools like Functionize, Browser Use, and Skyvern employ deep learning, computer vision, or LLMs to build dynamic models of the UI. This moves beyond static element identification to contextual understanding, which is crucial for robust test execution and self-healing.
- Self-Healing Mechanisms: Self-healing is a pervasive feature, often enabled by AI models (e.g., ML Engines, LLMs) that analyze UI changes or error information to autonomously update test scripts. This directly addresses the high maintenance cost associated with traditional automated tests.
- Cloud-Based Execution: While not explicitly detailed for all tools, Functionize's cloud-based environment suggests a common pattern for scalability, allowing tests to be executed across various environments without significant infrastructure overhead for the user.
These architectural patterns collectively facilitate advanced features like codeless testing by abstracting technical complexities and enable robust self-healing through intelligent adaptation to application changes. The reliance on AI for UI modeling and NLP for test creation inherently improves maintainability by reducing the fragility of tests and the effort required for updates. Scalability is often addressed through cloud-based infrastructures that can provision resources on demand. However, the exact implications for extensibility and the detailed architectural designs of some specialized tools, beyond their stated benefits, often remain underexplored in current literature.
3.2 General-Purpose AI Agent Frameworks and Their Adaptability to Testing
General-purpose AI agent frameworks serve as the foundational infrastructure for developing sophisticated autonomous testing agents, offering versatile features that can be adapted to various software testing contexts. Frameworks like
AutoGen, SuperAGI, and CrewAI provide robust capabilities for multi-agent collaboration and cooperative task-solving, which are crucial for addressing complex testing scenarios .
AutoGen, for instance, facilitates multi-agent collaboration through asynchronous messaging, enabling agent-to-agent (A2A) communication . This capability is particularly beneficial for complex testing tasks such as system-level or integration testing, where different specialized agents can collaborate. For example, a Test Discovery Agent might identify potential test cases, a Test Executor Agent could execute them using tools like Playwright, and a Fix Recommender Agent could analyze failures and suggest solutions. This distributed approach leverages the strengths of individual agents to tackle intricate workflows .
Other frameworks also contribute to this foundational infrastructure. SuperAGI is designed for creating fully autonomous AI agents with autonomous task management, while CrewAI focuses on role-based autonomous agents with specialized team structures and coordinated task execution . These frameworks offer versatility, simplicity, customizability, and ease of use, positioning them as essential tools for AI development beyond just testing applications . LangChain is another versatile framework that connects Large Language Models (LLMs) with external data, APIs, and AI agent tools, boasting robust memory features for dynamic, context-aware applications . Its adaptability to test automation has been noted, although its specific principles and features in this context are not always detailed .
The adaptability of these general-purpose frameworks to software testing is significantly enhanced by features such as Model Context Protocols (MCP), which allow LLMs to command external tools via a JSON-based interface, thereby enabling real-world actions like interacting with Playwright or databases . Additionally, LlamaIndex focuses on managing and interacting with large-scale language models, crucial for data organization, retrieval, and analysis in testing scenarios, while LangGraph is highlighted for creating knowledge graphs and advanced data-driven reasoning, vital for understanding complex system behaviors .
Despite their broad capabilities, critical assessment reveals potential gaps and areas for extension or customization when adapting these frameworks specifically for software testing. While frameworks like UiPath Agent Builder allow for custom AI agent development, enabling testers to choose foundational LLMs and define agent goals and behaviors using natural language prompts, general-purpose frameworks may not inherently address all the unique challenges of software testing . These challenges include ensuring test coverage, handling dynamic UI elements, managing test data, and providing actionable insights from test results. Therefore, while general-purpose frameworks provide a strong base, specialized integrations, custom tool connections, and domain-specific optimizations are often required to fully meet the rigorous demands of robust software testing automation.
4. Applications and Key Capabilities of Autonomous Agents in Software Testing
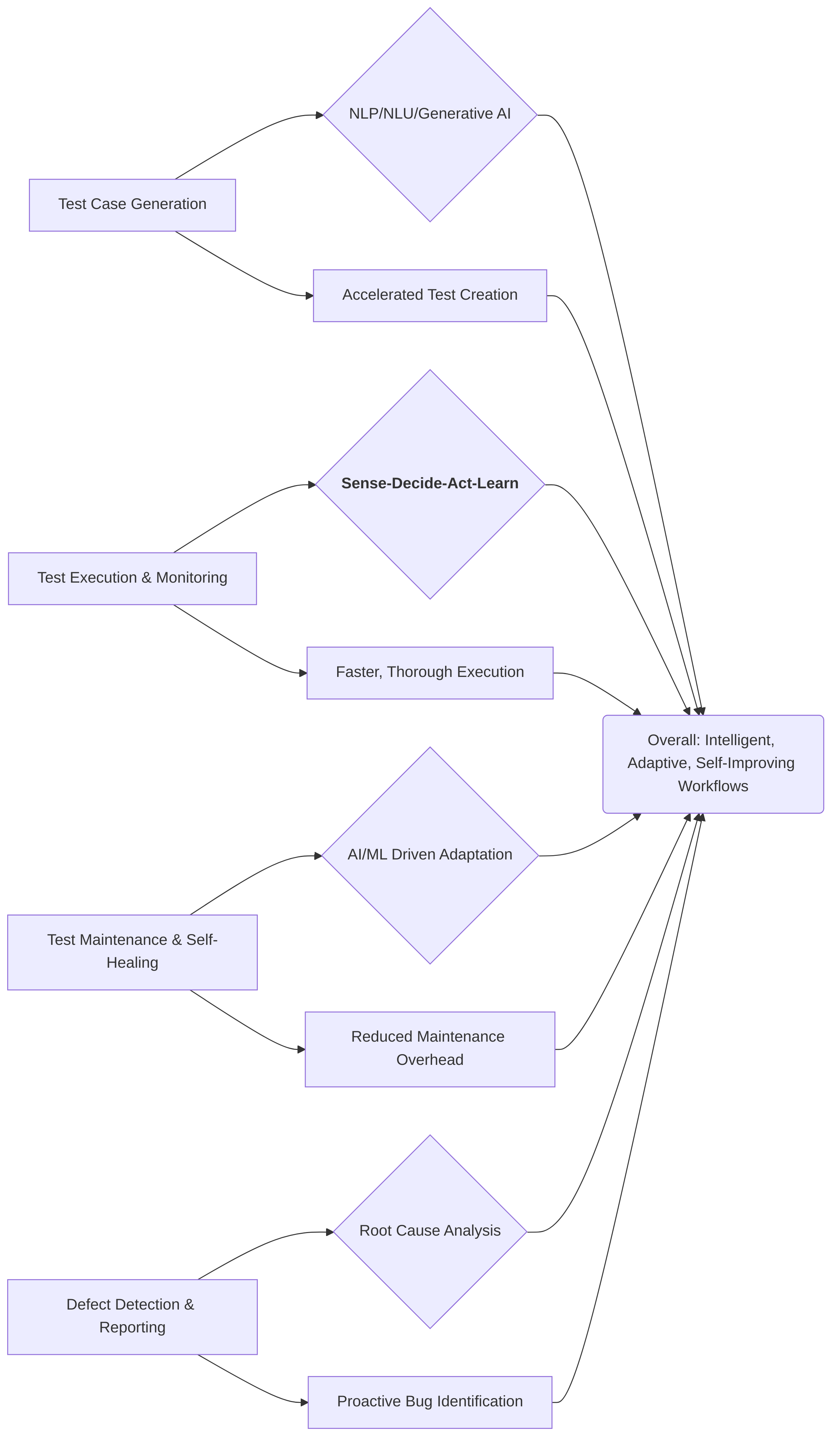
Autonomous agents are profoundly transforming software testing by extending automation beyond traditional scripts to encompass intelligent, adaptive, and self-improving workflows across various domains and phases of the software development lifecycle . This section delves into the diverse applications of autonomous agents in software testing, from generating and optimizing test cases to executing, monitoring, and maintaining them, and finally, to enhancing defect detection and reporting.
The application of autonomous agents spans a broad spectrum of software testing domains, including UI, API, and mobile testing . While specific examples like web, mobile, desktop, game, car infotainment systems, or Mixed Reality applications are highlighted , the overarching capability is their adaptability across diverse platforms and ecosystems, such as SAP®, ServiceNow, or Salesforce . This versatility allows agents to simulate complex user interactions and high-load scenarios that are challenging for traditional methods .
A key benefit universally highlighted is the significant improvement in automation, efficiency, and rapid innovation . Agents automate repetitive tasks like regression testing, accelerate release cycles, and allow human testers to focus on more strategic work . This efficiency is achieved through capabilities such as continuous, parallel test execution around the clock, rapid feedback cycles, especially when integrated into CI/CD pipelines, and dynamic prioritization of tests based on recent changes .
The intelligence of these agents is significantly bolstered by Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG). LLMs facilitate intelligent test automation by enabling the generation of test cases from natural language requirements and high-level specifications . This democratizes test writing, making it accessible to non-technical stakeholders and speeding up the initial test creation phase . For instance, Functionize's agent uses an ML Engine to convert plain English test plans into functional UI models, reducing test creation from 35 days to 3 days for 50 test plans . testRigor similarly translates user prompts into executable actions . LLMs can also convert OpenAPI specifications into API test scripts, often enhanced by RAG to provide context from documentation or bug data, improving test coverage and accuracy in test generation and defect localization .
Self-healing and smart-fix functionalities represent a pivotal advancement, addressing the brittleness of traditional automation scripts due to frequent application changes . These capabilities involve sophisticated object recognition and dynamic locator adaptation, where AI agents automatically detect UI element modifications (e.g., changes in position or name) and adjust test scripts accordingly . Virtuoso claims up to a 90% reduction in test maintenance, while Functionize highlights an 85% reduction, attributing this to their ML Engine's understanding of UI behavior and root cause analysis for proposing solutions . TestRigor also offers self-healing capabilities that adapt to UI or API changes, reducing maintenance overhead . This adaptability is critical in agile environments with frequent updates .
The efficacy of autonomous web agents as testers has been evaluated in several studies. Systems like SeeAct-ATA and pinATA demonstrate their ability to interpret natural language instructions, execute test steps, and verify assertions against web applications, with pinATA showing a 50% improvement over SeeAct-ATA in execution efficiency . These agents have demonstrated high specificity (up to 94%) in providing correct verdicts on test case execution, indicating strong capability in identifying passing tests .
A critical comparison of these applications across studies reveals varying contexts and reported efficacies. While many papers emphasize benefits like increased speed, efficiency, and reduced manual effort , specific quantitative results or detailed methodologies are not always provided, especially for claims regarding optimization or general self-healing beyond specific tools . For instance, while Functionize and Virtuoso provide impressive metrics on test creation and maintenance reduction , some sources offer more general assertions without specific data . The continuous learning capabilities of these agents, often implicit, suggest iterative refinement processes for test suites . However, limitations such as potential AI "hallucinations" in natural language-driven generation are acknowledged, with tools like testRigor aiming to facilitate easier correction . The integration of AI agents into CI/CD pipelines for real-time feedback and proactive bug detection represents a significant shift from reactive to proactive testing . The granular, method-driven contrast highlights that capabilities are realized through varied approaches, including NLP, NLU, Generative AI, LLMs with RAG for intelligent content generation, ML Engines for functional UI modeling and root cause analysis, and advanced object recognition for self-healing. While some sources detail these underlying mechanisms, others provide a higher-level overview, underscoring the need for more uniform and empirically validated reporting of methodologies and architectural choices in future research.
4.1 Test Case Generation and Optimization
Autonomous agents significantly enhance test authoring by enabling the generation of test cases directly from natural language requirements and high-level specifications . This capability democratizes test writing, making it accessible to non-technical stakeholders and speeding up the initial test creation phase .
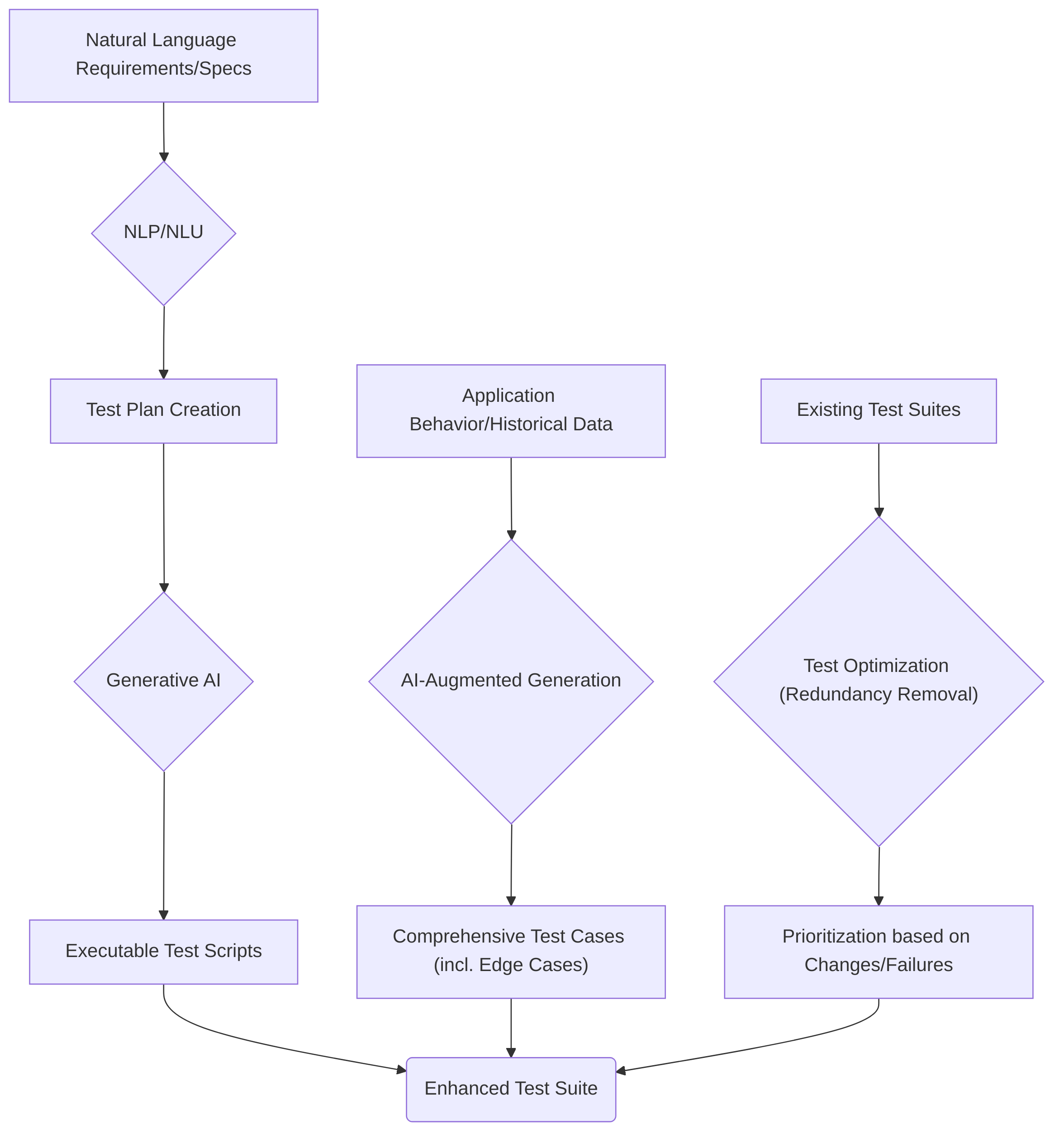
The primary mechanism involves Natural Language Processing (NLP), Natural Language Understanding (NLU), and Generative AI. For instance, Functionize's intelligent test agent processes plain English test plans via an ML Engine to construct a functional UI model, dramatically accelerating test creation velocity. This approach has demonstrated a capability to create, model, and run 50 test plans across browsers in 3 days, a notable improvement over the 35 days typically required by legacy systems . Similarly, testRigor leverages Generative AI and NLU to translate user prompts such as "find and add a Kindle to the shopping cart" into executable sequences of actions, like searching, clicking, and adding to cart . This natural language interface extends to converting high-level specifications into concrete test scripts, including converting English instructions into Selenium code or orchestrating API calls based on documentation . Large Language Models (LLMs) can further convert OpenAPI specifications or user stories into complete API test scripts, often employing Retrieval-Augmented Generation (RAG) to ground the LLM with relevant documentation or bug data, thereby enhancing test coverage . AI agents also contribute to test design by quality-checking requirements, generating detailed manual test cases with steps and expected outcomes, and allowing testers to refine outputs with prompts for specific scenarios like usability or invalid inputs .
Beyond generation, autonomous agents play a crucial role in optimizing existing test cases and suites based on insights derived from application behavior and historical data. AI-augmented generation analyzes source code, historical defects, and real-time application behavior to generate comprehensive test cases, including edge cases, with minimal human intervention . Test optimization is achieved by eliminating redundant or ineffective test cases . AI agents can prioritize tests based on recent software changes or failure rates and criticality, thereby saving time and resources . This dynamic prioritization ensures that critical tests are executed first, leading to early defect identification and reduced overall testing costs . While specific algorithms for optimization are not always detailed, the continuous learning capabilities of these agents imply an iterative refinement process for test suites . Furthermore, ML agents assist in optimizing test coverage and generating large quantities of realistic synthetic test data, mimicking real-world scenarios and edge cases essential for comprehensive testing .
The effectiveness of these techniques varies based on context and implementation. While the rapid test creation demonstrated by Functionize highlights significant velocity improvements , some agents, like those mentioned in the GeeksforGeeks paper, do not provide specific quantitative results, performance improvements, or detailed methodologies for their optimization claims . A stated limitation for natural language-driven generation is the potential for AI "hallucinations," where the AI deviates from expectations, though tools like testRigor aim to facilitate easier correction of such deviations . While the paper on autonomous web agents is not directly focused on test case generation from requirements, its implicit address of optimization through comparing performance of different ATA implementations (e.g., pinATA showing a 50% improvement over SeeAct-ATA in execution) highlights the potential for efficiency gains in the testing process, even if applied to pre-defined test cases . The continuous learning aspect, although not always detailed with specific optimization methodologies, suggests an iterative refinement of test suites to improve their efficacy over time .
4.2 Test Execution and Monitoring
Autonomous agents significantly enhance test execution by accurately understanding application states and performing comprehensive root cause analysis .
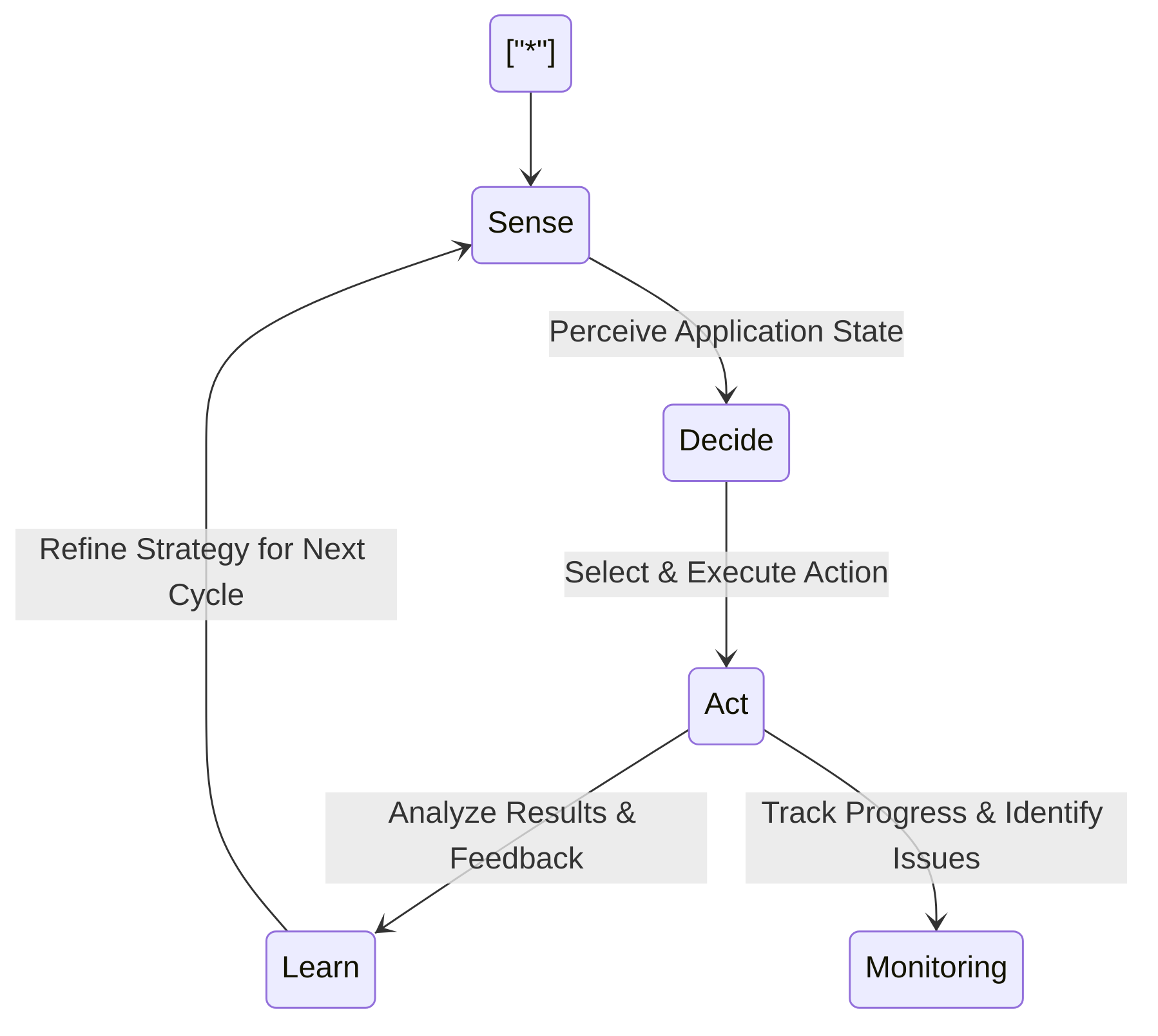
Agents initiate actions, such as clicking buttons or sending API requests, based on learned decisions, forming a "sense-decide-act-learn" loop for continuous improvement . This capability extends to interpreting natural language commands and verifying assertions against application states, as demonstrated by systems like SeeAct-ATA and pinATA, which quantify their effectiveness through metrics like correct verdict percentages and specificity in experimental settings . Furthermore, agents are adept at analyzing test results to identify common failure patterns, pinpointing root causes, and suggesting targeted fixes . This analytical prowess is also leveraged for debugging, predicting potential error locations, and identifying precise faulty code, thereby supporting shift-left testing by detecting issues earlier in the development lifecycle .
Agent-driven execution offers substantial advantages in terms of speed and thoroughness. Agents execute tests considerably faster than humans, enabling round-the-clock, parallel test execution to achieve extensive test coverage without manual intervention . This expedites feedback cycles, particularly when integrated into Continuous Integration/Continuous Delivery (CI/CD) pipelines, triggering test suites automatically upon code changes . The ability to prioritize tests based on recent software modifications further optimizes resource allocation and time savings . Moreover, their capacity for parallel execution, often facilitated by cloud-based platforms, allows for thousands of tests to run concurrently, dramatically boosting test productivity and ensuring thoroughness by capturing detailed statistics and visual evidence at every step . This thoroughness also extends to intelligent load testing, where agents dynamically simulate user behavior and system load to provide accurate performance insights, and predictive performance analysis to proactively identify bottlenecks .
The effectiveness of agent-driven monitoring and adaptation during execution is evident in several contexts. Agents continuously monitor application states and adapt test execution in real-time, often implied by their ability to analyze results and learn from them . This includes "self-healing" automation, where agents automatically update test cases to accommodate changes in application UI or functionality, significantly reducing maintenance overhead . Such adaptability also involves optimizing test execution by distributing tests across diverse environments, including various devices, operating systems, and cloud platforms . Furthermore, continuous testing features, powered by machine learning, enable real-time execution and proactive bug detection . Agents facilitate proactive defect identification by providing real-time feedback on potential issues and suggesting relevant tests based on code changes . They can also integrate with defect management systems to automatically raise defects and share reports . In the context of API testing, agents can automate the entire lifecycle and provide iterative feedback, such as suggesting "Add boundary tests" . For system behavior, anomaly detection using statistical methods and machine learning algorithms helps identify unusual patterns, aiding early problem identification and enhancing security .
However, specific implementation details and quantitative results regarding how agents monitor test environments or adapt to changes during execution are often not extensively provided in some discussions, beyond the general concept of self-healing . This lack of detailed quantitative evidence represents a limitation in fully assessing the extent and precision of their real-time monitoring and adaptation capabilities.
4.3 Test Maintenance and Self-Healing
The concept of "self-healing tests with the power of AI and ML" represents a significant advancement in software testing, aiming to mitigate the substantial effort associated with test maintenance . Traditional automation scripts are inherently brittle, prone to breaking with even minor application changes, leading to considerable downtime for manual adjustments . AI agents, conversely, introduce adaptability and resilience by automatically updating test scripts to accommodate changes in the application under test .
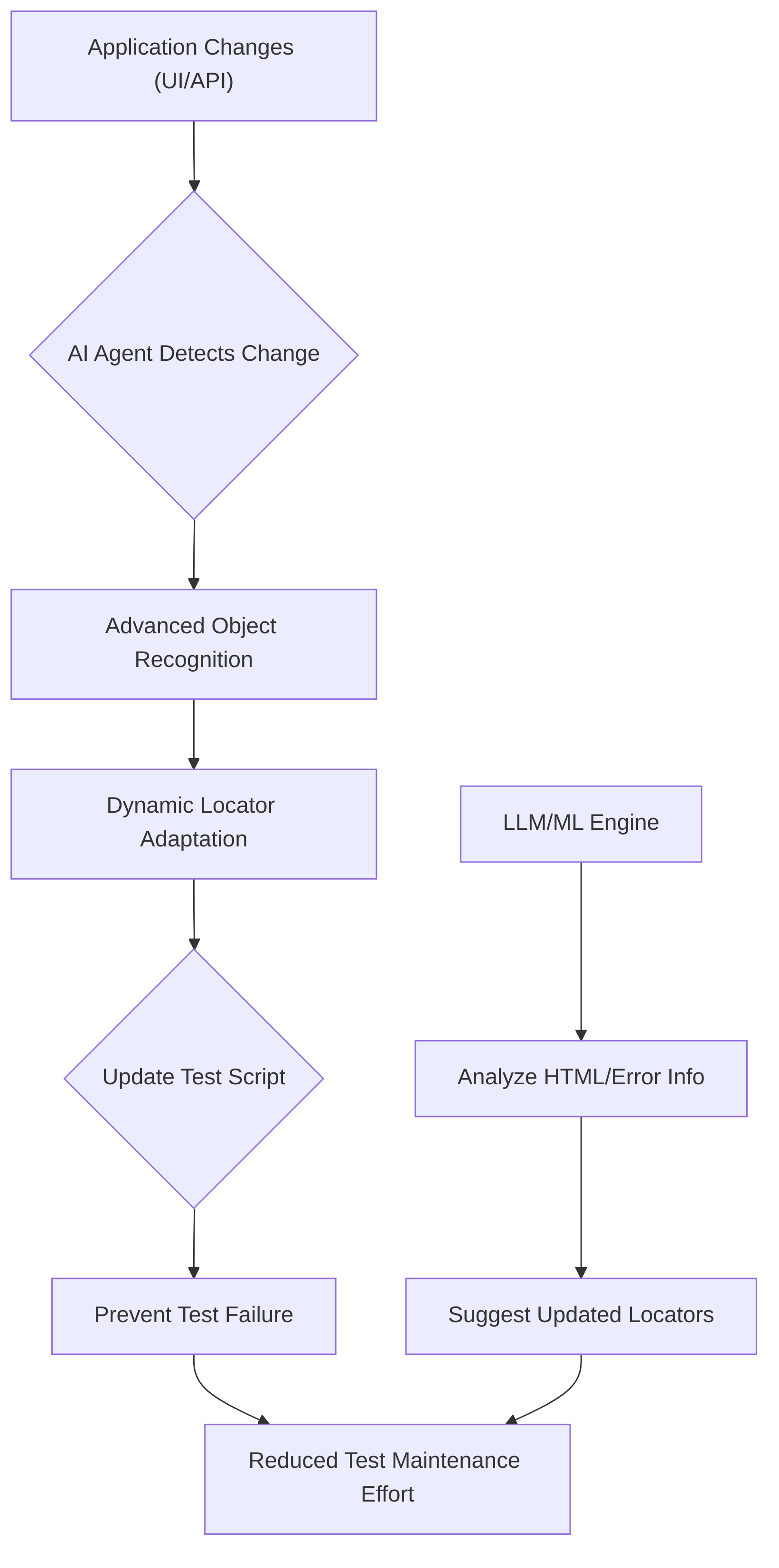
The technical mechanisms underpinning self-healing capabilities primarily revolve around advanced object recognition and dynamic locator adaptation. AI agents can detect modifications in UI elements, such as changes in position or name, and automatically adjust the test scripts to interact with the new elements, preventing test failures . For instance, if a button's underlying HTML tag changes (e.g., from <button> to <a>), AI agents from tools like testRigor are designed to understand the semantic role of the element and adapt the test script accordingly, rather than relying on a static, brittle locator . This adaptability extends to other UI and API changes, significantly reducing the maintenance effort, particularly in agile development cycles characterized by frequent updates .
A notable approach involves leveraging Large Language Models (LLMs) for self-healing. When an element's selector is updated, tools can transmit the application's HTML and error information to an LLM. The LLM then processes this context to suggest an updated and functional locator, effectively repairing the test script . While the continuous learning aspects of ML agents and the adaptability of Reinforcement Learning (RL) agents implicitly contribute to maintaining testing relevance over time, direct self-healing mechanisms are more explicitly focused on immediate test script repair .
In critically comparing self-healing mechanisms, claims regarding resilience and maintenance reduction are central. Virtuoso's platform, for instance, asserts a reduction of up to 90% in test maintenance through its self-healing capabilities, which automatically detect and repair broken scripts . Similarly, Functionize's Intelligent Test Agent highlights a claimed reduction of up to 85% in test maintenance, attributing this to its ML Engine's understanding of the UI's intended behavior. This allows the system to manage minor UI or styling changes without test breakage. For more substantial alterations, it employs Root Cause Analysis to pinpoint issues and propose solutions, thus enabling effective test self-healing and addressing the considerable maintenance effort associated with legacy automation . Tools like testRigor also offer self-healing capabilities that automatically adapt test scripts to UI or API changes, claiming to significantly reduce maintenance overhead and improve automated tests over time . However, some sources, while acknowledging the self-healing functionality and its benefits in reducing maintenance, do not provide specific quantitative results or detailed implementation methodologies to substantiate these claims, emphasizing the need for more empirical validation in future research . Overall, the consensus is that AI-powered self-healing significantly reduces manual effort and increases the longevity of automated tests, thereby enhancing the efficiency and stability of software testing processes.
4.4 Defect Detection and Reporting
Autonomous agents significantly enhance defect detection and reporting by moving beyond traditional pass/fail mechanisms to provide richer diagnostic insights . Unlike conventional methods that typically offer binary outcomes, agent-based systems analyze execution results to identify common failure patterns, link them to root causes, and offer actionable insights through interactive reporting interfaces, even recommending potential fixes . This capability is further extended by their ability to review test results independently, group similar defects, and pinpoint data patterns to accelerate root cause identification .
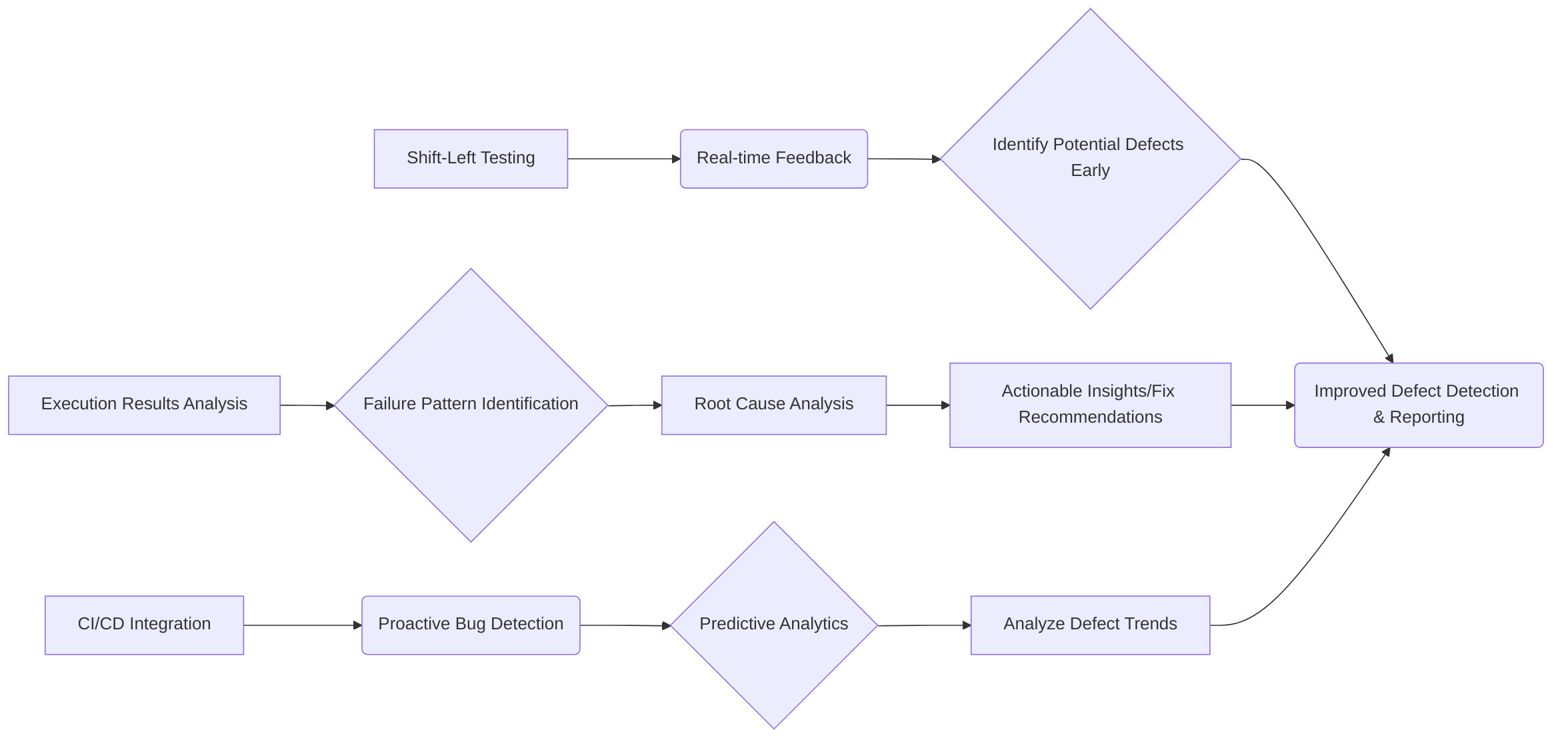
Agents facilitate a "shift-left" approach to testing by providing real-time feedback on potential defects, allowing developers to identify and resolve issues earlier in the development lifecycle . They achieve this by continuously analyzing application changes, predicting potential defects before system failures occur, and identifying UI changes that necessitate automation script adjustments . Furthermore, agentic AI integrates into Continuous Integration/Continuous Deployment (CI/CD) pipelines to offer real-time feedback, enabling earlier defect detection. This includes predictive analytics that anticipate potential failures by analyzing historical test data and production logs, and the analysis of defect trends to prioritize testing on vulnerable application areas, identifying recurring failure patterns from past data .
The accuracy and efficiency of agent-based defect detection and reporting mechanisms are notable. Agents contribute to automated bug detection and classification by analyzing code for anomalies and categorizing them by severity and type, which aids in efficient prioritization . Machine Learning (ML) models are employed for defect prediction, analyzing historical data, code complexity, and developer activity to predict likely defect locations, thereby enabling proactive measures . AI-powered Root Cause Analysis (RCA) leverages ML algorithms and data analytics to identify underlying issues by collecting data from diverse sources, recognizing patterns, and detecting anomalies . Moreover, AI automates bug triaging and assignment, classifying bugs and allocating them to appropriate team members based on expertise and workload, streamlining integration with development tools .
Some studies highlight quantitative achievements in this area. For instance, autonomous web agents have demonstrated up to 94% specificity in providing "verdicts" on test case execution, indicating a high capability to correctly identify passing tests . While some papers imply improved defect detection through comprehensive test coverage and proactive anomaly identification , they sometimes lack detailed specific mechanisms or quantitative results regarding reporting depth or accuracy . Nevertheless, capabilities like capturing screenshots at each test step and providing detailed performance statistics implicitly support defect detection and reporting by visualizing changes and tracking performance metrics, allowing users to identify anomalies and understand the impact of UI modifications or test failures . The self-healing capabilities of these agents also indirectly ensure that defects are correctly identified and not masked by broken tests .
5. Benefits and Challenges of Autonomous Agent Frameworks
Autonomous agent frameworks are revolutionizing software testing by offering substantial benefits that fundamentally alter traditional QA paradigms . These benefits encompass heightened automation and efficiency, fostering rapid innovation and accelerated software delivery , alongside broader trends and advantages identified across the field . The subsequent sub-sections will elaborate on these advantages, detailing how autonomous agents reduce manual effort, enhance test coverage, and improve overall software quality.
Despite their transformative potential, the widespread adoption of autonomous agent frameworks is met with several significant challenges. These include inherent technical complexities and the pressing need for robust, reliable agent frameworks capable of handling the intricacies of real-world software development . Furthermore, the advanced nature of this technology often necessitates specialized expertise, implying a demand for "world-class scientists" and highly skilled professionals to effectively leverage and manage these systems . Current AI capabilities also present limitations, particularly in addressing highly dynamic or undefined test scenarios, leading to issues such as "AI hallucinations" or the generation of nonsensical test steps .
The following sub-sections will delve into these identified challenges, analyzing their root causes and comparing their severity and nature across different studies. This includes examining the economic implications, such as the compute overhead of powerful models, and structural issues like the fragmentation of current AI testing tools. Furthermore, the discussion will extend to critical ethical considerations, including potential job displacement, algorithmic bias, and the complex issues of accountability in an increasingly automated testing landscape. Where applicable, proposed mitigation strategies and solutions mentioned within the papers will be discussed, providing a forward-looking perspective that anticipates future developments in the field.
5.1 Key Benefits
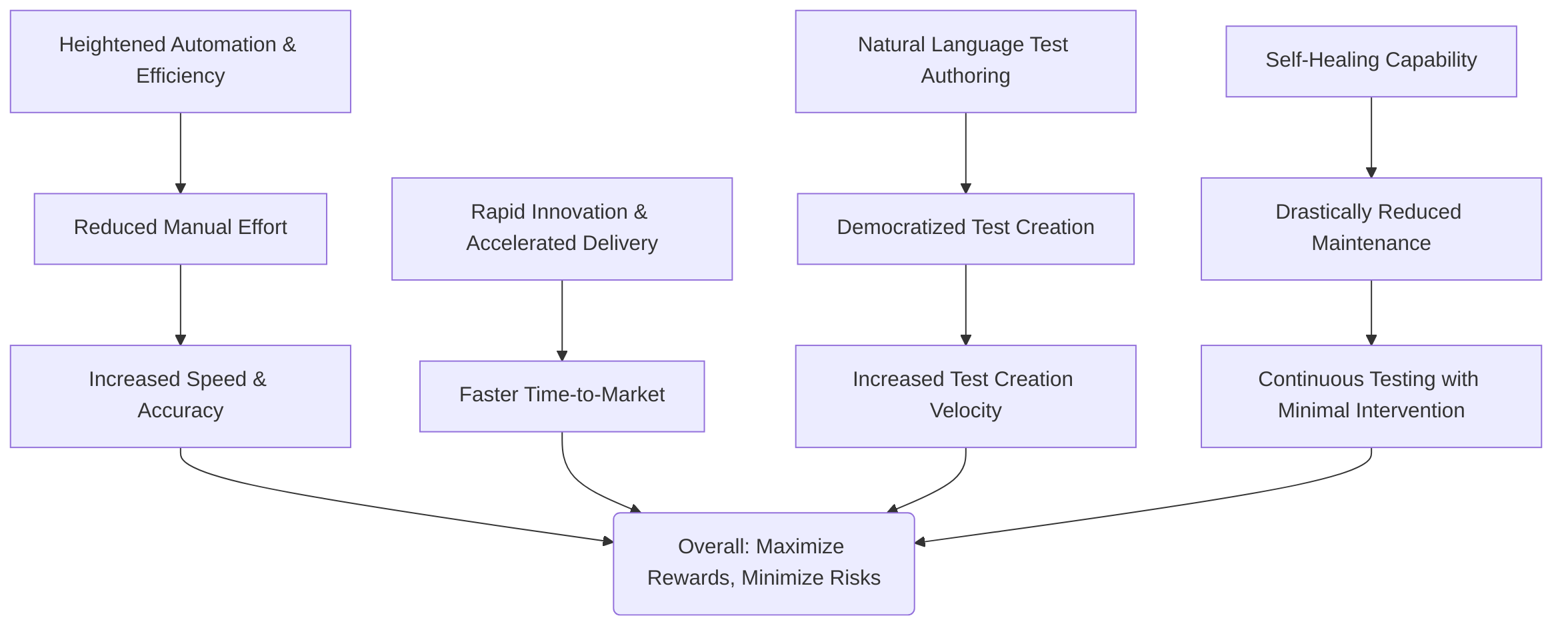
Autonomous agent frameworks revolutionize software testing by maximizing rewards and minimizing product risks, primarily through significant enhancements in quality, test coverage, and acceleration of testing processes . These agents drastically reduce manual effort by automating repetitive tasks, thereby decreasing human errors in test scripting and allowing QA engineers to focus on more strategic activities . This automation leads to increased speed, improved accuracy, and accelerated software delivery .
A critical feature contributing to these efficiencies is natural language test authoring, which democratizes test creation by enabling non-technical users to generate robust test scripts in plain English . This capability, often coupled with low-code/no-code platforms, makes testing faster and more accessible, increasing the velocity of test creation significantly, with examples citing 50 tests in 3 days compared to 35 days manually .
Another paramount benefit is the self-healing capability, which drastically reduces test maintenance effort—up to 85% or even 90% in some instances—by automatically adapting test scripts to application changes . This autonomous adaptation ensures continuous testing with minimal human intervention, preventing broken scripts from hindering the testing pipeline .
Beyond these core features, the consolidated benefits across the reviewed literature include:
- Enhanced Efficiency and Speed: Agents facilitate continuous and faster test execution, automating repetitive tasks and significantly reducing manual effort . This results in accelerated software releases and quicker time-to-market .
- Improved Quality and Reliability: AI agents enhance software quality through intelligent test case generation, comprehensive test coverage, and proactive defect detection, often before issues impact users . Continuous learning capabilities further refine test quality and accuracy over time .
- Cost Efficiency: By reducing labor costs associated with manual testing, minimizing human errors, and enabling early defect detection, autonomous agents contribute to significant cost savings throughout the software development lifecycle .
- Scalability and Adaptability: Agentic frameworks offer inherent scalability, allowing for intelligent test creation across diverse platforms such as UI, API, and mobile . Their ability to adapt test scripts and optimize tests facilitates practices like shift-left testing .
- Enhanced Security and Compliance: Beyond functional testing, agentic AI contributes to better security against cyber threats and aids in compliance efforts .
- Innovation and Workflow Streamlining: Tools and frameworks supporting multi-agent collaboration, such as AutoGen, SuperAGI, CrewAI, and LangChain, enable tackling complex challenges beyond typical test automation, fostering innovation and streamlining entire software development workflows . This extends to automating the entire SDLC, significantly reducing development time and making software creation more inclusive .
- Accessibility and Collaboration: By simplifying test creation through intuitive interfaces and natural language processing, agentic systems make test automation accessible to both technical and non-technical users, fostering better alignment and collaboration between product and testing teams .
In summary, the deployment of autonomous agent frameworks provides a multi-faceted advantage, moving beyond simple automation to deliver intelligent, adaptable, and highly efficient testing solutions that directly impact product quality, time-to-market, and overall operational costs, thus enabling a strategic shift for QA engineers and development teams .
5.2 Identified Challenges and Limitations
Despite the promotional emphasis on the transformative potential of autonomous agents in software testing, several significant challenges and limitations persist, hindering their widespread adoption and full autonomy.
| Challenge | Description | Impact |
|---|---|---|
| Expertise Requirement | Need for specialized skills ("world-class scientists," advanced solutions) for effective deployment and management. | High barrier to entry for organizations lacking necessary talent. |
| AI Hallucinations | LLMs generating non-existent selectors, methods, or nonsensical test steps. | Unpredictability, requires continuous validation, especially in dynamic or undefined scenarios. |
| Cost & Compute Overhead | High cost associated with powerful models (e.g., GPT-4) for large-scale operations. | Limits adoption for smaller organizations. |
| Fragmentation & Integration | Experimental and fragmented AI testing tool landscape, lacking robust integration with IDEs and CI/CD pipelines. | Complicates toolchain management, deployment, and debugging. |
| Data Privacy | Concerns regarding data handling and compliance when using SaaS LLMs for sensitive projects. | Potential compliance risks and data security breaches. |
| Security Concerns | Risks with code-generation agents require secure sandboxing to prevent malicious code execution. | Vulnerability to code injection and unauthorized access. |
| Vendor Lock-in | Reliance on proprietary ML Engines and NLP capabilities can limit flexibility and interoperability. | Reduced ability to switch providers or integrate with diverse ecosystems. |
| Reliability & Robustness | Current agents not yet robust or reliable enough for widespread adoption without further development. | Hinders full replacement or significant augmentation of traditional methods. |
A primary concern is the implicit barrier to entry for organizations lacking specialized expertise or access to "world-class scientists" and "advanced solutions," as highlighted by the need for top-tier tools and skilled testers to leverage platforms like UiPath Agent Builder . This suggests that while these tools promise to augment human capabilities, their effective deployment still demands a level of sophistication in implementation and ongoing management.
A critical technical limitation frequently identified is "AI hallucinations," particularly with Large Language Models (LLMs), where models may generate non-existent selectors, methods, or nonsensical test steps . This issue stems from the inherent probabilistic nature of LLMs and their reliance on the quality of provided guidance and training data. For instance, without proper constraints, agents may deviate from expected behavior, necessitating careful implementation and continuous validation of LLM-generated test cases and locators . While some approaches, such as representing prompts as specific English actions, aim to simplify corrections for hallucinations , the underlying unpredictability remains a considerable hurdle, especially in highly dynamic or undefined test scenarios.
Another significant challenge is the cost and compute overhead associated with powerful models like GPT-4, particularly for large-scale testing operations . This economic factor can prohibit smaller organizations from fully leveraging advanced agent frameworks. Furthermore, the current landscape of AI testing tools is often described as experimental and fragmented, lacking robust integration with established Integrated Development Environments (IDEs) and Continuous Integration/Continuous Delivery (CI/CD) pipelines . This fragmentation complicates toolchain management and deployment, leading to increased debugging complexity when tracing issues through intricate agent chains or model-generated code .
Data privacy is also a major concern, particularly when sensitive projects utilize SaaS LLMs, raising questions about data handling and compliance . Additionally, security considerations arise with code-generation agents, necessitating secure sandboxing environments to prevent malicious code execution or data breaches . The reliance on proprietary Machine Learning Engines and Natural Language Processing (NLP) capabilities, as seen in tools like Functionize, also suggests a potential for vendor lock-in, limiting flexibility and interoperability with other systems .
While some papers implicitly suggest "careful implementation" and continuous monitoring and improvement as mitigation strategies , specific detailed solutions are often sparse. The acknowledgment that a fully autonomous AI is still "a little way off" and that "human testers are very much necessary" underscores the current limitations of AI agents, implying that human oversight and collaboration remain indispensable for robust and reliable software testing . Qualitative evaluations of current Autonomous Web Agents (AWAs) as Automated Test Agents (ATAs), such as pinATA, reveal that while promising, they are not yet robust or reliable enough for widespread adoption without further development, highlighting the ongoing need for research into resilience and reliability .
5.3 Ethical Considerations and Societal Impact
The proliferation of autonomous agents in software testing presents significant ethical considerations and potential societal impacts, particularly concerning job displacement, algorithmic bias, and accountability. A thorough analysis of the provided literature indicates a nascent stage of discourse regarding these critical issues within the domain of autonomous software testing.
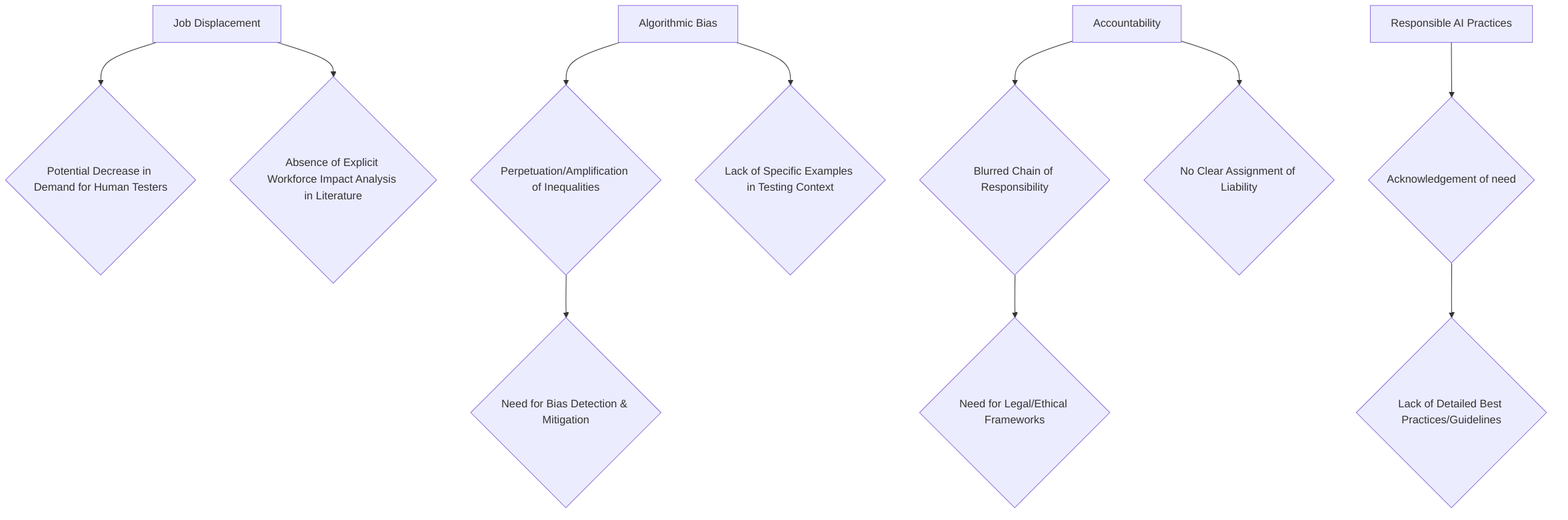
One primary concern revolves around the potential for job displacement within the software testing field. As autonomous agents assume more complex and repetitive testing tasks, the demand for human testers specializing in these areas may decrease. However, the current corpus of research, as evidenced by the analyzed digests, does not explicitly address the socio-economic implications of this automation on the workforce . This absence suggests a gap in the current research focus, which predominantly centers on the technical capabilities and efficiency gains of autonomous testing systems rather than their broader societal ramifications.
Another critical ethical dimension pertains to algorithmic biases inherent in the AI models underpinning these autonomous agents. If the training data used for these AI models is unrepresentative or contains biases, the autonomous testing agents could perpetuate or even amplify existing inequalities in software quality and accessibility. For instance, an agent trained on data primarily reflecting the usage patterns of a specific demographic might inadvertently overlook defects or usability issues critical to other user groups. While the general concept of "responsible AI" is acknowledged, as indicated by the mention of the "UiPath AI Trust Layer" ensuring "open, flexible, and responsible AI that’s easy to track and respects your enterprise data policies" , specific critical examinations of how algorithmic biases might manifest in software testing automation or concrete strategies for mitigation are largely absent from the reviewed digests. This highlights a need for more in-depth research into the potential for bias propagation within autonomous testing frameworks and the development of robust bias detection and mitigation techniques.
Furthermore, the complexities of assigning responsibility when errors or critical failures occur due to the actions of autonomous testing systems represent a significant challenge. In traditional testing paradigms, accountability is typically attributed to human testers or development teams. However, with systems capable of independent decision-making and execution, the chain of responsibility becomes blurred. The analyzed papers do not delve into the legal or ethical frameworks required to address this issue, such as determining liability for undetected critical bugs or unintended system behaviors caused by autonomous agents during testing . This area demands rigorous ethical and legal analysis to establish clear guidelines for accountability in the context of autonomous software testing.
Finally, the synthesis of proposed ethical guidelines or best practices for the development and deployment of autonomous agents in software testing is limited within the current body of reviewed literature. While some providers express a commitment to "responsible AI" , comprehensive frameworks or detailed best practices specifically tailored to the unique challenges of autonomous software testing, such as guidelines for bias audits, transparency in AI decision-making for testing, or human oversight protocols, are not extensively discussed. Future research and industry initiatives should prioritize the development of such ethical frameworks to ensure the responsible and beneficial integration of autonomous agents into the software testing ecosystem.
6. Future Trends and Research Directions
The landscape of software testing is undergoing a profound transformation due to the advent of autonomous agent frameworks, shifting from traditional automation to more intelligent and proactive methodologies .
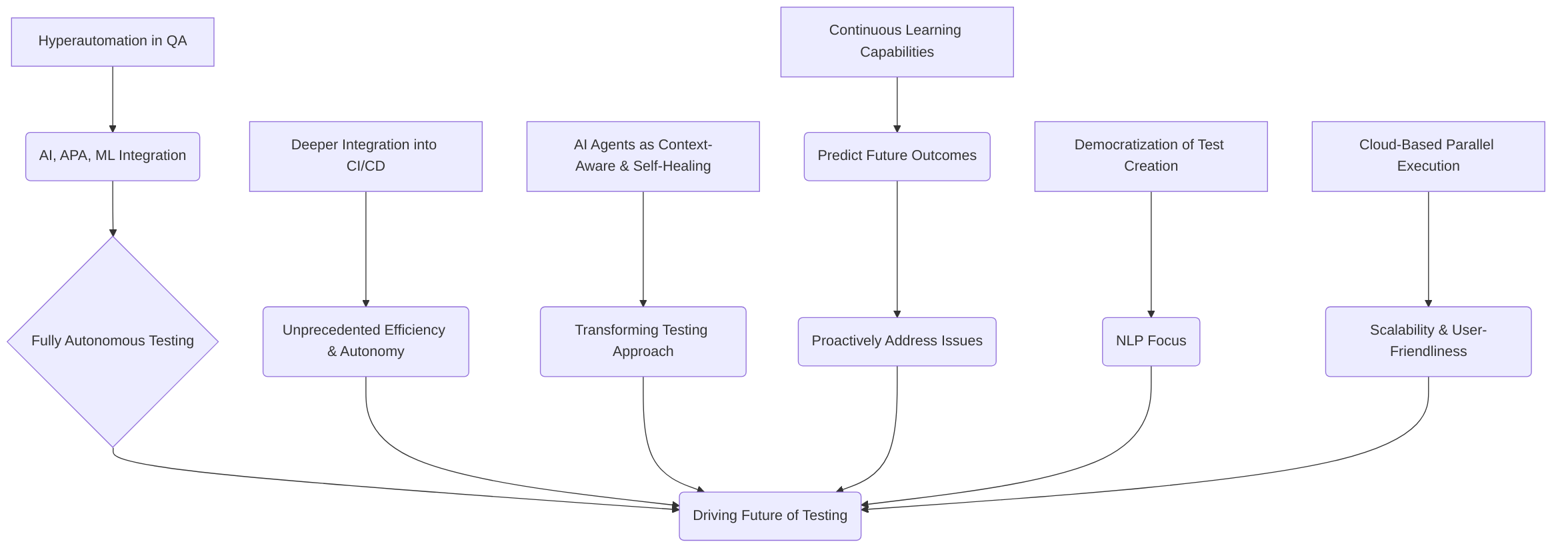
Current trends indicate a move towards hyperautomation in Quality Assurance (QA), integrating Artificial Intelligence (AI), Agentic Process Automation (APA), and Machine Learning (ML) to achieve fully autonomous testing with minimal human intervention . This evolution is driven by the increasing complexity and speed of modern software development, necessitating more sophisticated testing solutions .
A key trend is the deeper integration of AI agents into DevOps and Continuous Integration/Continuous Deployment (CI/CD) pipelines, enabling these pipelines to reach unprecedented levels of efficiency and autonomy . By 2025, AI testing agents are expected to be highly integrated, context-aware, and even self-healing, fundamentally changing the approach to testing rather than merely automating existing tasks . This includes the continuous learning capabilities of AI agents, allowing them to analyze past testing cycles to predict future outcomes and proactively address potential issues . Furthermore, the democratization of test creation through Natural Language Processing (NLP) and the emphasis on cloud-based parallel execution are emerging as critical directions for enhancing user-friendliness and scalability .
Future research avenues are largely shaped by addressing current limitations and leveraging emerging technologies. One significant direction involves the full integration of advanced Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) into more sophisticated multi-agent testing environments . This fusion is poised to redefine test automation, making AI-powered agents first-class citizens in CI/CD pipelines . Research should focus on maturing these models and frameworks, potentially exploring hybrid approaches that combine LLM generation with human oversight for validation, thereby enhancing both autonomy and reliability .
Another critical area for future research is the development of more resilient and reliable autonomous testing agents . This involves exploring advanced LLM architectures, refining prompt engineering techniques, and developing more sophisticated mechanisms for state understanding and assertion verification within web applications to improve performance and consistency beyond current levels . Analogous challenges in fields such as robotics and autonomous driving, where robustness and reliability are paramount, offer valuable insights for designing more fault-tolerant autonomous testing agents. Similarly, methodologies from formal methods could be adapted to provide rigorous guarantees for agent behavior.
Moreover, the advancement of multi-agent systems and collaborative AI agents presents a promising research direction. The vision is for multiple specialized AI agents to collaborate on complex applications, sharing insights across different testing aspects like UI, performance, and security, thereby improving the overall testing process and efficiency . This collaborative paradigm extends to human-AI collaboration, where AI agents handle repetitive tasks, allowing human testers to focus on exploratory testing, risk assessment, and complex scenarios requiring human intuition . Further research should also investigate how AI can assist exploratory testing by suggesting scenarios based on application complexity, past issues, and uncovered areas, moving towards personalized testing strategies based on usage patterns and user feedback to enhance user experience .
To overcome current bottlenecks in autonomous testing, interdisciplinary solutions are essential. The field of formal methods, for instance, offers techniques for specifying and verifying system properties, which could be adapted to define and validate the behavior of autonomous testing agents. Successes in software testing history, such as advancements in metamorphic testing or property-based testing, can be synthesized and adapted for autonomous agent frameworks. For example, applying metamorphic relations could help autonomous agents generate diverse and effective test cases without requiring a test oracle for every execution, thereby addressing the oracle problem. Similarly, integrating property-based testing principles could enable agents to generate inputs and verify properties against specifications, improving test completeness and reducing false positives.
Finally, a significant unresolved issue is the lack of Explainable AI (XAI) in autonomous testing, which limits transparency and trust in AI-driven test decisions . Future research should prioritize developing XAI techniques to provide clear justifications for agent actions and predictions. This directly links to the challenge of building trust in autonomous systems (as identified in Section 5.2), where understanding why an agent made a particular decision is crucial for adoption and debugging. Furthermore, the ethical considerations of fully autonomous agents in critical software systems warrant dedicated research to ensure responsible development and deployment. The continuous exploration of new tools and frameworks for building AI agents will be vital in driving innovation and efficiency in this rapidly evolving field .
7. Conclusion
Autonomous agent frameworks have fundamentally revolutionized software testing automation, offering significant contributions across various facets of the testing lifecycle. These frameworks enhance test case generation, provide self-healing capabilities for test scripts, and improve defect tracking, collectively making software testing more intelligent, efficient, and proactive than traditional manual methods . The adoption of AI agents has led to substantial reductions in manual effort, accelerated release cycles, and improved overall software quality, thereby fostering continuous testing and early defect detection . Tools such as Functionize's intelligent test agent exemplify these advancements by leveraging Natural Language Processing (NLP) for test creation and offering self-healing functionalities that drastically reduce maintenance time . Similarly, testRigor and ACCELQ's Autopilot demonstrate how generative AI and NLP can optimize testing processes, increase test coverage, and expedite defect detection using plain English, positioning AI agents as indispensable for future software reliability and user satisfaction .
Despite these transformative contributions, the field of autonomous agents in software testing faces key challenges and presents significant opportunities for future research and development. While autonomous web agents (AWAs) like pinATA show promise for natural language test case execution and script maintenance reduction, current implementations still exhibit limitations in achieving robust and reliable performance that could fully replace or significantly augment traditional methods . This highlights the need for further advancements to overcome existing effectiveness barriers and enhance their capabilities. The fusion of Large Language Models (LLMs), autonomous agents, Retrieval-Augmented Generation (RAG), and Multi-Agent Collaboration Patterns (MCP) is currently transforming test automation by reducing manual effort, enhancing adaptability, and scaling intelligent test creation across diverse platforms . However, the field is still in its nascent stages, necessitating hybrid approaches for effective validation and adoption, especially as AI-powered agents become integral parts of Continuous Integration/Continuous Delivery (CI/CD) pipelines . Future opportunities lie in developing more sophisticated AI agents that can work collaboratively to make exploratory and personalized testing more effective, further accelerating releases and improving quality while minimizing manual effort . The vision for the future includes LLM-based AI agents automating the entire Software Development Life Cycle (SDLC) through AI-driven chat interfaces, thereby enhancing efficiency, transparency, and collaboration, and ultimately redefining software engineering paradigms .
In conclusion, the current state of autonomous agents in software testing automation is one of rapid evolution and significant promise. These agents are not merely tools but collaborators that relieve human testers of repetitive workloads, allowing them to focus on creative, high-value tasks, thereby fundamentally transforming software quality assurance . The trend points towards increasingly sophisticated and intelligent AI agents that will drive automation, improve overall software quality, and accelerate delivery speed, making them integral to all enterprises' software development processes . While challenges remain, particularly in achieving complete autonomy and robustness, the continuous advancements in AI technology, coupled with the development of robust frameworks like SmythOS , indicate a future where autonomous agents will become central to achieving unprecedented speed, scale, and quality in software creation. Organizations that embrace these advancements and partner with AI experts are poised to gain a competitive edge, streamline testing, and ensure higher quality software products in a dynamic market .
References
How Agent-Based AI Is Reshaping Software Testing | Virtuoso QA https://www.virtuosoqa.com/post/agent-based-ai-reshaping-software-testing
What is Agent-based Testing - Startup House https://startup-house.com/glossary/what-is-agent-based-testing
Technical Tuesday: How AI agents are transforming software testing - UiPath https://www.uipath.com/blog/product-and-updates/how-ai-agents-transforming-software-testing-technical-tuesday
Autonomous Agents in Software Development : A Vision Paper - JYX: JYU https://jyx.jyu.fi/jyx/Record/jyx\_123456789\_99459/Description?sid=87858860
AI Agents in Software Testing - testRigor AI-Based Automated Testing Tool https://testrigor.com/ai-agents-in-software-testing/
AI Agents for Automation Testing: Revolutionizing Software QA - Codoid https://codoid.com/ai-testing/ai-agents-for-automation-testing-revolutionizing-software-qa/
[2504.01495] Are Autonomous Web Agents Good Testers? - arXiv https://arxiv.org/abs/2504.01495
AI Agents in Software Testing - GeeksforGeeks https://www.geeksforgeeks.org/software-testing/ai-agent-in-software-testing/
AI Agents in Software Testing: Automation & Efficiency - Rapid Innovation https://www.rapidinnovation.io/post/ai-agents-in-software-testing
How LLMs and AI Agents Are Transforming Test Automation | by Saurabh Srivastava https://medium.com/@saurabh71289/how-llms-and-ai-agents-are-transforming-test-automation-7d0903e0d8c2
Automated software testing using Functionize's intelligent test agent https://www.functionize.com/page/automated-software-testing-using-functionizes-intelligent-test-agent
Agentic AI for Software Testing | Benefits and its Trends - XenonStack https://www.xenonstack.com/blog/agentic-software-testing
AI Agents in Testing: Smarter Automation Beyond Chatbots & Assistants - ACCELQ https://www.accelq.com/blog/ai/
Autonomous Agent Frameworks - SmythOS https://smythos.com/developers/agent-development/autonomous-agent-frameworks/
Top 10 Tools & Frameworks for Building AI Agents in 2025 - Quash https://quashbugs.com/blog/top-tools-frameworks-building-ai-agents