0. Opportunities and Challenges of Multimodal Large Models in Personalized Medical Image Diagnosis
1. Introduction: The Evolving Landscape of AI in Medical Imaging
The integration of Artificial Intelligence (AI) into medical imaging represents a pivotal transformation in healthcare, fundamentally motivated by the need to enhance diagnostic accuracy, efficiency, and consistency across clinical practices . This revolution is particularly pronounced in radiology, a domain rich in data and signals, where AI's advanced pattern-detection capabilities can augment human expertise, thereby serving as a robust support tool for clinicians . The burgeoning volume of AI-focused research over the past decade underscores the critical importance for medical professionals, especially radiologists, to comprehensively understand AI's underlying principles and strategies for its safe and effective deployment .

Traditional unimodal AI approaches, predominantly employing convolutional neural networks (CNNs) for image analysis, have achieved substantial improvements in diagnosis by enhancing accuracy, speed, and consistency in the detection of various diseases . These CNNs, typically trained via supervised learning on radiologist-annotated datasets, process imaging data through successive layers to yield classifications with associated probabilities . While these models have demonstrated performance comparable to, and in some cases even superior to, human radiologists in narrowly defined tasks—such as identifying lung nodules or diagnosing pneumonia from chest radiographs—their inherent limitations include a constrained scope and a dependency on vast quantities of high-quality training and validation data .
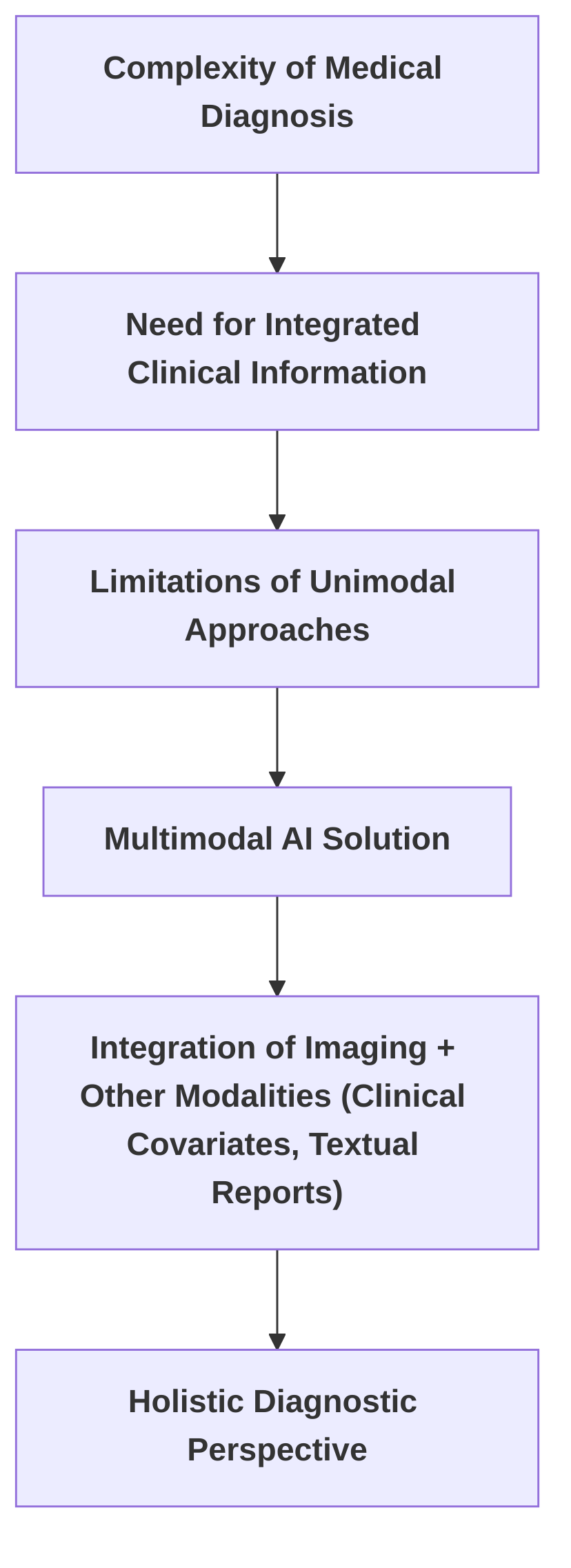
The escalating interest in multimodal AI directly addresses these limitations, acknowledging the intrinsic complexity of medical diagnoses, which frequently necessitate the integration of diverse clinical information beyond single imaging modalities . For instance, the nuanced interpretation of liver parenchymal alterations in conjunction with vascular abnormalities and secondary complications often proves challenging for conventional computer vision models, underscoring the demand for more comprehensive approaches . Multimodal AI aims to surmount these challenges by integrating imaging data with at least one additional modality, such as clinical covariates or textual reports, thereby providing a more holistic diagnostic perspective .
A comparative analysis of the broad motivations articulated in and reveals both convergent and divergent emphases. Both narrative reviews underscore the transformative potential of AI in medical practice. specifically traces the historical evolution of AI and its profound influence on radiology, highlighting the limited existing literature that effectively integrates both multimodal imaging and clinical covariates. This review's primary objective is to comprehensively examine multimodal AI in radiology by scrutinizing both imaging and clinical variables, assessing methodologies, and evaluating clinical translation to inform future research directions . In contrast, is driven by the rapid advancements in AI and Natural Language Processing (NLP), particularly the emergence of Large Language Models (LLMs) such as ChatGPT. This paper centers on how LLMs can streamline the traditionally time-intensive and error-prone manual interpretation processes in medical imaging, thereby significantly impacting healthcare quality and patient well-being . While both reviews advocate for more advanced AI applications, emphasizes the integration of diverse data types for superior diagnostic insights, whereas accentuates the potential of LLMs to enhance processing capabilities, interactivity, and data diversity in medical imaging due to their robust representational learning capabilities. Both implicitly acknowledge the limitations of existing machine learning methods, including data uniqueness, interpretability issues, and the high cost of acquiring high-quality labeled datasets .
Deep Learning (DL) represents a foundational advancement that critically underpins the progression towards multimodal AI and personalized medicine. DL has revolutionized numerous fields, including medicine, by offering powerful tools for pattern recognition and prediction, which are indispensable for the advancement of personalized medicine . The principles elucidated in —such as leveraging data-driven insights to analyze complex biological data, identify disease markers, and predict patient responses to treatments—establish the groundwork for more specialized advancements. DL's capability to process large and intricate datasets facilitates a deeper understanding and management of diseases at an individual level, thereby promoting more individualized care . This trajectory from the general impact of DL to the specific advancements of Multimodal Large Models (MLMs) in medical imaging diagnosis illustrates a natural evolution: as unimodal DL models approach their performance limits in complex diagnostic scenarios, the integration of diverse data modalities via MLMs becomes imperative for unlocking new frontiers in personalized and precision medicine. The global COVID-19 pandemic further highlighted the pressing need for rapid, accessible, and dependable diagnostic tools, demonstrating the capacity of deep learning and transfer learning with imaging data to provide automated "second readings" and assist clinicians in high-pressure environments . While promising, the expansive impact of AI in medical imaging also mandates vigilance against potential biases that could compromise patient outcomes, emphasizing the necessity for proactive identification and mitigation of AI bias .
1.1 Background and Motivation
The integration of Artificial Intelligence (AI) into medical imaging marks a transformative era in healthcare, driven by the imperative to enhance diagnostic accuracy, efficiency, and consistency . This revolution is particularly pronounced in radiology, a data-rich field where AI's pattern-detection capabilities can surpass human limitations for specific tasks, serving as a powerful support tool for clinicians . The rapid increase in AI-focused studies over the past decade underscores the critical need for medical professionals, especially radiologists, to comprehend AI's underlying principles and strategies for safe and effective implementation .
Traditional unimodal AI approaches, predominantly utilizing convolutional neural networks (CNNs) for image analysis, have significantly improved diagnosis by enhancing accuracy, speed, and consistency in detecting various diseases . CNNs, trained with supervised learning on radiologist-annotated data, process images through convolutional, pooling, and fully connected layers to output classifications with weighted probabilities . While these models have demonstrated performance comparable to, or even superior to, human radiologists in narrow tasks such as identifying lung nodules or diagnosing pneumonia from chest radiographs, their scope is often limited, requiring vast quantities of high-quality training and validation data .
The increasing interest in multimodal AI stems from the recognition of these limitations and the inherent complexity of medical diagnoses, which often involve integrating multi-dimensional clinical information beyond single imaging modalities . For instance, interpreting liver parenchymal changes alongside vascular abnormalities and secondary complications frequently confounds traditional computer vision models, necessitating a more comprehensive approach . Multimodal AI aims to overcome these challenges by incorporating imaging data with at least one other modality, such as clinical covariates or textual reports, thereby providing a more holistic view for diagnosis .
A comparison of the broad motivations presented in and reveals shared and distinct emphases. Both narrative reviews acknowledge the transformative potential of AI in medicine. specifically highlights the historical development of AI and its profound impact on radiology, emphasizing the scarcity of literature that effectively integrates both multimodal imaging and clinical covariates. The review aims to comprehensively explore multimodal AI in radiology by examining both imaging and clinical variables, assessing methodologies, and evaluating clinical translation to inform future directions . Conversely, is motivated by the rapid advancements in AI and Natural Language Processing (NLP), particularly the emergence of Large Language Models (LLMs) like ChatGPT. This paper focuses on how LLMs can streamline the traditionally time-intensive and error-prone manual interpretation processes in medical imaging, thereby substantially impacting healthcare quality and patient well-being . While both reviews advocate for more advanced AI applications, focuses on the integration of diverse data types for improved diagnostic insights, whereas emphasizes the potential of LLMs to enhance processing, interactivity, and data diversity in medical imaging due to their robust representational learning capabilities. Both implicitly acknowledge the limitations of existing machine learning methods, such as data uniqueness, interpretability issues, and the cost of acquiring high-quality labeled datasets .
Deep Learning (DL) serves as a fundamental advancement that underpins the progression towards multimodal AI and personalized medicine. DL has revolutionized numerous fields, including medicine, by providing powerful tools for pattern recognition and prediction, which are crucial for advancing personalized medicine . The principles discussed in —such as leveraging data-driven insights to analyze complex biological data, identify disease markers, and predict patient responses to treatments—lay the groundwork for more specialized advancements. DL's capacity to handle large and complex datasets enables a deeper understanding and management of diseases on a personal level, thus facilitating more individualized care . This progression from general DL impact to specific Multimodal Large Model (MLM) advancements in medical imaging diagnosis highlights a natural evolution: as unimodal DL models reach their performance ceiling in complex diagnostic scenarios, the integration of diverse data modalities via MLMs becomes essential for unlocking new horizons in personalized and precision medicine. The global COVID-19 pandemic further underscored the need for rapid, accessible, and reliable diagnostic tools, demonstrating the potential of deep learning and transfer learning with imaging data to provide automated "second readings" and assist clinicians in high-pressure scenarios . While promising, the broad impact of AI in medical imaging also necessitates vigilance against potential biases that could compromise patient outcomes, emphasizing the need for proactive identification and mitigation of AI bias .
1.2 Scope and Organization of the Survey
This survey, titled "Opportunities and Challenges of Multimodal Large Models in Personalized Medical Image Diagnosis," is structured to provide a comprehensive analysis of the evolving landscape of multimodal large models (MLLMs) within personalized medical imaging. The initial sections establish foundational concepts, including the historical progression of artificial intelligence (AI) in medical imaging and the emergence of deep learning (DL) as a transformative force . This groundwork is crucial for understanding the transition towards more complex, multimodal AI systems that integrate various data streams beyond singular imaging modalities.
Subsequent sections build upon this foundation by delving into the specifics of large language models (LLMs) and their role in medical image processing . This includes an exploration of their fundamental principles, such as the Transformer architecture and pre-training methodologies, and their advantages over previous models . The survey then progresses to examine the diverse applications of LLMs in radiology, encompassing aspects like prompt engineering and their potential to enhance transfer learning efficiency, integrate multimodal data, and improve clinical interactivity . Specific instances include the use of LLMs to augment radiomics features for classifying breast tumors, demonstrating how clinical knowledge can be integrated to improve diagnostic accuracy .
The core of the survey addresses the multifaceted opportunities and challenges presented by MLLMs in personalized medical image diagnosis. Opportunities are discussed through the lens of emerging frameworks such as graph neural networks (GNNs) and transformers, highlighting their potential for integrating imaging and clinical metadata . For instance, a parameter-efficient framework for fine-tuning MLLMs for tasks like medical visual question answering (Med-VQA) and medical report generation (MRG) showcases advancements in practical application . Furthermore, the survey covers the comprehensive evaluation frameworks for multimodal AI models, including data preprocessing, standardized model evaluation, and preference-based assessment, as demonstrated by the comparison of general-purpose and specialized vision models on abdominal CT images .
Concurrently, the survey critically examines significant challenges. These include inherent issues such as data scarcity, taxonomic inconsistencies, and biases within AI systems, which are highly pertinent to MLLMs despite their broader applicability in medical imaging . Specific challenges for LLMs in medical image processing, such as data privacy, model generalization, and effective clinician communication, are also addressed . The survey also touches upon broader ethical and regulatory considerations pertinent to the deployment of LLMs in clinical settings . By systematically exploring these opportunities and challenges, the survey aims to provide a logical and comprehensive understanding of the current state and future directions of MLLMs in personalized medical image diagnosis, informing future research and clinical translation.
2. Fundamentals of Multimodal Large Models in Medical Contexts

This section delves into the foundational aspects of Multimodal Large Models (MLMs) and Large Language Models (LLMs) within medical contexts, particularly focusing on their application in medical image diagnosis. It establishes clear definitions for both MLMs and LLMs, elucidating their distinctive capabilities and highlighting their complementary roles. The subsequent discussion systematically explores the prevalent architectural patterns and data fusion techniques observed in the literature, critically comparing and contrasting their suitability for personalization. Finally, the section showcases specific architectural innovations that advance the practical application of these models in clinical settings.
The field of medical diagnosis is undergoing a transformative shift with the advent of Multimodal Large Models (MLMs) and Large Language Models (LLMs). LLMs, primarily built upon the Transformer architecture, are distinguished by their ability to process and generate human language through extensive training on text corpora, capturing intricate statistical patterns and semantic representations . Their application in medical imaging extends to analyzing textual reports and extracting critical information, thereby augmenting image analysis with contextual data . In contrast, MLMs are broadly defined as systems designed to integrate and process diverse data types, such as medical images and clinical text, for comprehensive diagnostic tasks . These models enhance patient care by fusing imaging data with other modalities, like clinical metadata, to enable personalized and precise predictions . Their collective role in medical diagnosis involves synthesizing visual features from images with contextual information from reports to interpret complex medical scenarios effectively .
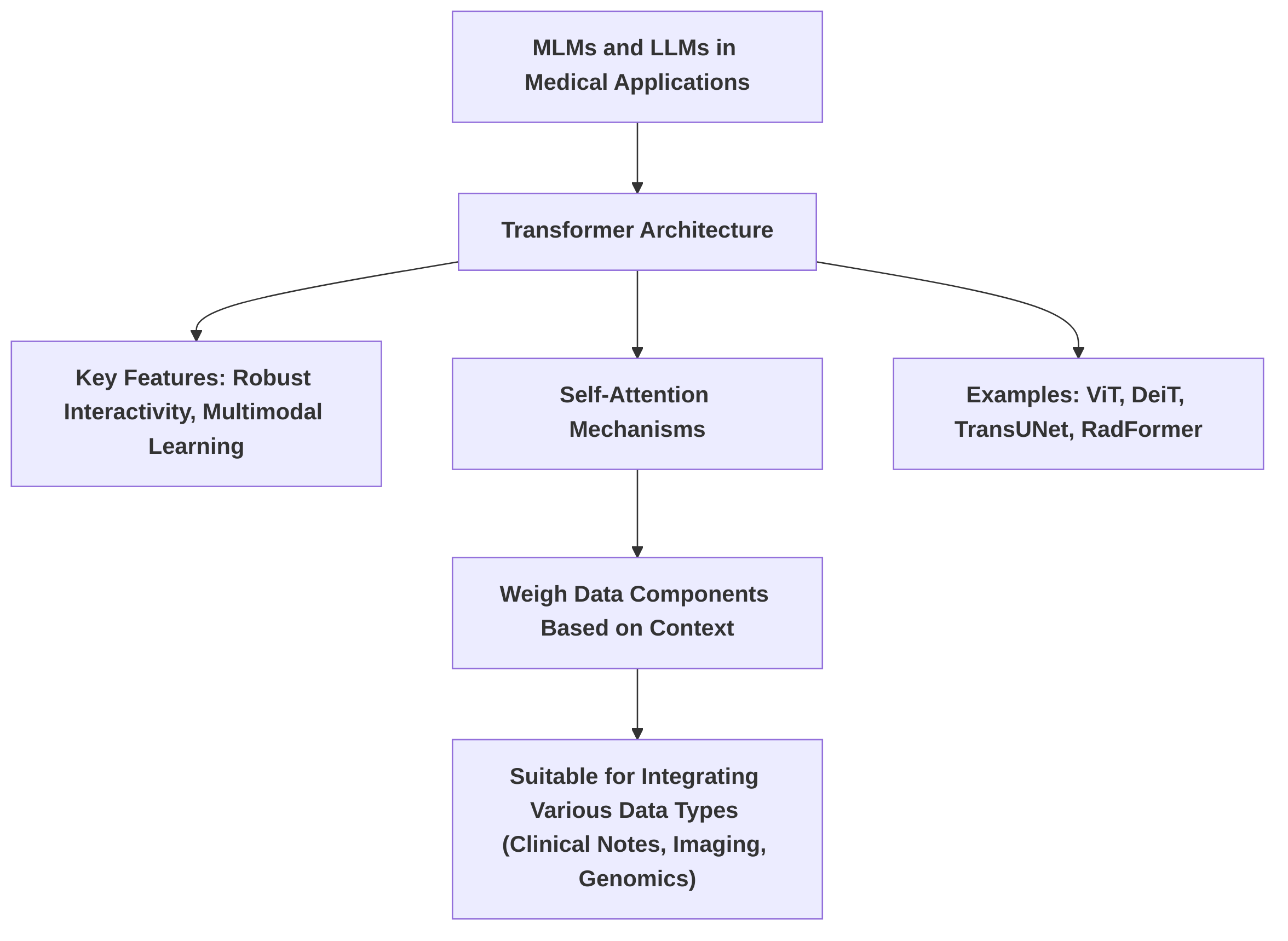
Common architectural patterns for both MLMs and LLMs in medical applications predominantly leverage the Transformer architecture, which has gained prominence in medical image processing due to its robust interactivity and multimodal learning capabilities . This architecture employs self-attention mechanisms to weigh data components based on context, making it highly suitable for integrating various data types, including clinical notes, imaging data, and genomic information . Examples include ViT, DeiT, TransUNet, and RadFormer . Data fusion techniques typically exploit these architectures to combine disparate data streams. An implicit fusion approach, for instance, involves using an LLM for text processing in conjunction with radiomic features extracted from mammograms, even if not explicitly detailed as an architectural component .
A comparison of architectural patterns and data fusion techniques in and reveals complementary approaches. emphasizes LLMs and their Transformer architecture, focusing on integrating image features with textual information through NLP techniques applied to medical reports. This represents a post-hoc fusion where textual insights enrich visual interpretations. Conversely, expands on multimodal AI, also highlighting Transformer-based models, but additionally introduces Graph Neural Networks (GNNs). GNNs excel at modeling non-Euclidean structures, explicitly representing complex relationships between modalities via graph structures, facilitating a more intrinsic fusion of data types like clinical notes, imaging, and genomic information for personalized predictions. While both Transformer and GNN approaches offer personalization capabilities through flexible attention mechanisms, the GNN approach described in appears inherently more amenable to personalization due to its capacity to explicitly model unique interdependencies within an individual patient's complex multimodal data.
Architectural innovations are further exemplified by models such as those discussed in . This work focuses on Multimodal Large Language Models (MLLMs adapted for medical multimodal problems as generative tasks. The emphasis on "Parameter-Efficient Fine-Tuning (PEFT)" signifies advancements in adapting large, pre-trained models to specialized medical imaging tasks without extensive re-training. PEFT methods, which involve introducing small, trainable parameters while keeping most pre-trained weights frozen, enable efficient adaptation and personalization to specific patient cases or medical conditions. These innovations are crucial for deploying MLMs in clinical settings where computational resources and data availability for full model training are often limited.
2.1 Defining Multimodal Large Models and Their Role in Medical Diagnosis
Multimodal Large Models (MLMs) and Large Language Models (LLMs) represent a significant evolution in artificial intelligence, particularly in the domain of medical imaging. LLMs are a subset of Natural Language Processing (NLP) models, predominantly built upon the Transformer architecture, trained on extensive text corpora to capture statistical patterns and semantic representations . Their core capability lies in comprehending, generating, and processing human language, which extends to analyzing medical reports and extracting crucial information using NLP techniques to augment image analysis . In contrast, MLMs are implicitly defined as systems capable of processing and integrating diverse data types, such as medical images and clinical text, for diagnostic tasks . Multimodal AI models enhance patient care by combining imaging data with at least one other modality, like clinical metadata, enabling personalized and precise predictions . The role of these models in medical diagnosis involves interpreting complex medical scenarios by synthesizing visual features from images with contextual information from reports .
Common architectural patterns observed in MLMs and LLMs for medical applications largely revolve around the Transformer architecture. This architecture, foundational to LLMs, is noted for its growing prominence in medical image processing due to its robust interactivity and multimodal learning capabilities . Transformer models are adept at handling sequential data and employ self-attention mechanisms that weigh data components based on context, making them suitable for integrating various data types such as clinical notes, imaging data, and genomic information . Examples of Transformer-based models applied in medical image analysis include ViT, DeiT, TransUNet, and RadFormer . Data fusion techniques, particularly in multimodal contexts, leverage these architectures to combine disparate data streams. For instance, the implicit use of an LLM for text processing combined with radiomic features extracted from mammograms exemplifies a fusion approach, even if not explicitly detailed as an architectural component .
Comparing the architectural patterns and data fusion techniques described in and reveals distinct but complementary approaches. primarily focuses on LLMs and their Transformer architecture, emphasizing their ability to integrate image features with textual information. This integration is achieved through NLP techniques applied to medical reports, thereby augmenting image analysis with clinical data for improved diagnostic accuracy. The paper highlights the versatility of LLMs in being fine-tuned for task-specific data or used as feature extractors, suggesting a post-hoc fusion where textual insights enrich visual interpretations. In contrast, presents a broader view of multimodal AI, also emphasizing Transformer-based models but additionally introducing Graph Neural Networks (GNNs). GNNs are highlighted for their capacity to model non-Euclidean structures in healthcare data, explicitly representing complex relationships between modalities through graph structures. This approach allows for a more integrated and intrinsic fusion of different data types, such as clinical notes, imaging data, and genomic information, leading to personalized and precise predictions. While both Transformer-based approaches can be amenable to personalization due to their flexible attention mechanisms, the GNN approach described in appears inherently more amenable to personalization. This is because GNNs can explicitly model the unique interdependencies and relationships within an individual patient's complex multimodal data, which is crucial for tailoring diagnoses and treatments.
Specific architectural innovations are exemplified by models like those discussed in . This paper describes Multimodal Large Language Models (MLLMs) as an evolutionary expansion of traditional LLMs, specifically adapted for medical multimodal problems as generative tasks. While the digest does not detail the specific architectural innovations, the focus on "Parameter-Efficient Fine-Tuning (PEFT)" suggests advancements in adapting large, pre-trained models to specialized medical imaging tasks without extensive re-training or modification of the entire model. This approach typically involves introducing small, trainable parameters while keeping the majority of the pre-trained weights frozen, allowing for efficient adaptation and personalization to specific patient cases or medical conditions. Such innovations are critical for deploying MLMs in clinical settings, where computational resources and data availability for full model training can be limiting.
2.2 Data Modalities and Integration Strategies
The integration of diverse data modalities is pivotal for advancing personalized medical image diagnosis, with various studies employing different data types and fusion strategies. Common medical data modalities observed across the reviewed literature include a dominant focus on medical imaging data, specifically X-ray, Ultrasound, CT scans, and mammography images . Beyond imaging, textual data, such as clinical notes, diagnostic reports, and medical records, are increasingly recognized as crucial for providing comprehensive diagnostic context . Some works also implicitly acknowledge the potential for integrating genomic data and laboratory results to further enrich diagnostic models .
Data integration strategies are broadly categorized into early, late, and hybrid fusion, each with distinct effectiveness and suitability depending on the specific application and data characteristics . Early fusion involves concatenating input data modalities before feature learning, often used when integrating imaging data with other modalities. Intermediate or joint fusion entails learning features independently from each modality and then combining them at an intermediate layer, while late fusion processes modalities independently until the final prediction stage. The choice of fusion technique is critical and depends on factors such as data source characteristics, model architecture, and the specific diagnostic application, with no universally optimal method identified .
In the context of COVID-19 detection, a study by utilizes X-ray, Ultrasound, and CT scans. The integration strategy in this paper is implicit, as each imaging modality is treated separately for classification tasks. While the paper does not explicitly detail a formal fusion strategy, the simultaneous use of these diverse imaging modalities effectively provides a richer set of diagnostic indicators, potentially mitigating the limitations of any single modality. This approach, though not a direct fusion, allows for comprehensive assessment by leveraging distinct visual cues from different imaging techniques. The pre-processing steps, including N-CLAHE for brightness and contrast standardization and data augmentation, are crucial for handling the significant variability in quality, size, and format across public datasets, thereby enhancing the diagnostic accuracy of models trained on these disparate sources .
Emerging trends indicate a growing emphasis on leveraging Large Language Models (LLMs) for multimodal data integration due to their inherent capabilities, especially through the Transformer architecture . LLMs can encode information from various modalities, including images, text, video, and audio, enabling joint processing and harnessing correlations between them. For instance, the ChatCAD system exemplifies how LLMs can enhance CAD networks by converting medical images into text content for LLM input, thereby combining natural language processing with image analysis for report generation and interactive dialogue . Similarly, in breast tumor classification, mammography images are integrated with radiomics features extracted from them, with an LLM fine-tuned to process these features, implicitly integrating them with learned clinical knowledge through prompt engineering . This illustrates a hybrid approach where image-derived quantitative data is fused with the linguistic processing power of LLMs. Another instance involves the concatenation of radiomic features with embedded textual features from diagnostic reports to form a multimodal input for classification tasks, underscoring the benefits of combining structured and unstructured data for improved diagnostic performance . The trend leans towards sophisticated integration methods that capitalize on the complementary nature of different data types, moving beyond traditional image-only analyses towards holistic patient assessments.
2.3 Mechanisms of Personalization in Multimodal Models
Personalized medicine, a core tenet of modern healthcare, seeks to tailor medical decisions and treatments to the individual patient, considering their unique characteristics, genetics, and lifestyle. Within the framework of multimodal artificial intelligence (AI), this vision is beginning to materialize through various mechanisms, though significant research gaps remain. The broader concept of deep learning opening new horizons in personalized medicine is highlighted by , which suggests that deep learning can analyze complex data to predict patient responses to treatments, leading to individualized care. However, this paper does not detail specific methods for achieving personalization within multimodal models .
Currently, direct mechanisms for personalization in multimodal models for medical image diagnosis are not extensively detailed across all reviewed literature. Many papers focus on the broader capabilities of large language models (LLMs) and multimodal AI in general medical image processing, such as integrating diverse data and enhancing clinical interactivity . For instance, while LLMs' ability to integrate patient-specific information like genetic data, medical history, and chief complaints is recognized as a pathway to more tailored diagnostics , the explicit mechanisms for personalization beyond general data integration are not thoroughly elaborated. Similarly, studies focusing on COVID-19 detection or general AI applications in diagnostic imaging prioritize broad applicability over individual patient tailoring .
One notable approach that contributes to personalization is Parameter-Efficient Fine-Tuning (PeFT) for Multimodal Large Language Models (MLLMs), as explored in . While the primary focus of this paper is on improving performance on generalized medical tasks through efficient fine-tuning, the adaptation of models to specific medical domains or datasets inherently moves towards personalization. PeFT methods, such as Low-Rank Adaptation (LoRA) or prefix-tuning, enable the adaptation of large pre-trained models to new, often smaller, datasets with minimal computational cost. This capability is crucial for personalization because it allows a foundational MLLM to be fine-tuned on data specific to a particular patient cohort, disease subtype, or even an individual patient, thereby enhancing its relevance and accuracy for that specific context. For example, by fine-tuning an MLLM on a dataset of images and clinical notes from patients with a rare disease, the model can learn to identify subtle patterns that might be missed by a general-purpose model, thus offering a more personalized diagnostic aid. This aligns with the vision of deep learning enabling more tailored diagnostic and treatment approaches, as outlined in .
Another indirect contribution to personalization can be observed in studies that enhance patient-specific representations. For instance, the enhancement of radiomics features using LLMs for classifying breast tumors indirectly contributes to personalization. Radiomics features are derived from medical images and are inherently patient-specific. By improving the classification accuracy through an enhanced feature set, the approach can lead to more personalized diagnostic outcomes, as the model's predictions are based on richer, more accurate individual patient data. The concept of "extensible learning" in this context suggests an adaptive capability, which is a step towards more personalized models. It is important to note that the findings from are not directly applicable to the personalization aspect, as their focus is on evaluating general diagnostic performance rather than tailoring diagnostics to individual patient characteristics.
Despite these advancements, significant research gaps persist in achieving deep personalization within multimodal AI for medical image diagnosis. A primary challenge lies in the current focus on general diagnostic improvements rather than explicit mechanisms for tailoring models to individual patient characteristics or incorporating comprehensive patient-reported outcomes. While approaches like PeFT offer a promising direction, their application for truly individual-level personalization requires further development.
Future research directions should focus on developing sophisticated methods for integrating longitudinal patient data, including sequential imaging studies, electronic health records (EHRs), genomic data, and patient-reported outcomes, to capture the dynamic progression of diseases and individual responses to treatments. This would allow multimodal models to not only provide a diagnosis at a single point in time but also to predict disease trajectories and recommend tailored treatments that evolve with the patient's condition. Furthermore, research is needed on creating adaptive learning frameworks that can continuously update and refine models based on new patient data, ensuring that diagnostic and treatment recommendations remain optimally personalized. Exploring federated learning or personalized federated learning paradigms could also enable patient-specific model adaptation while preserving data privacy, a crucial consideration in healthcare. Such advancements would propel multimodal AI beyond broad diagnostic tools towards truly personalized medical solutions.
3. Opportunities: Applications and Benefits in Personalized Medical Image Diagnosis

Multimodal Large Models (MLMs) represent a significant advancement in personalized medical image diagnosis, offering substantial opportunities for enhancing various facets of clinical practice and research. By integrating diverse data modalities—ranging from medical imaging (e.g., X-ray, CT, MRI, Ultrasound) to clinical metadata (e.g., patient history, laboratory results, genetic information)—MLMs enable a more comprehensive and precise understanding of a patient's condition, moving beyond the limitations of unimodal approaches .
This section systematically explores the opportunities presented by MLMs in personalized medical image diagnosis, structured into five key sub-sections. First, "Enhanced Diagnostic Accuracy and Precision" details how the integration of multimodal data leads to improved diagnostic outcomes, often surpassing unimodal models and human experts in specific tasks. It presents case studies and quantifies performance gains, highlighting the robustness achieved by compensating for individual modality limitations . Despite these advancements, a key research gap lies in demonstrating real-world clinical utility through prospective validation studies.
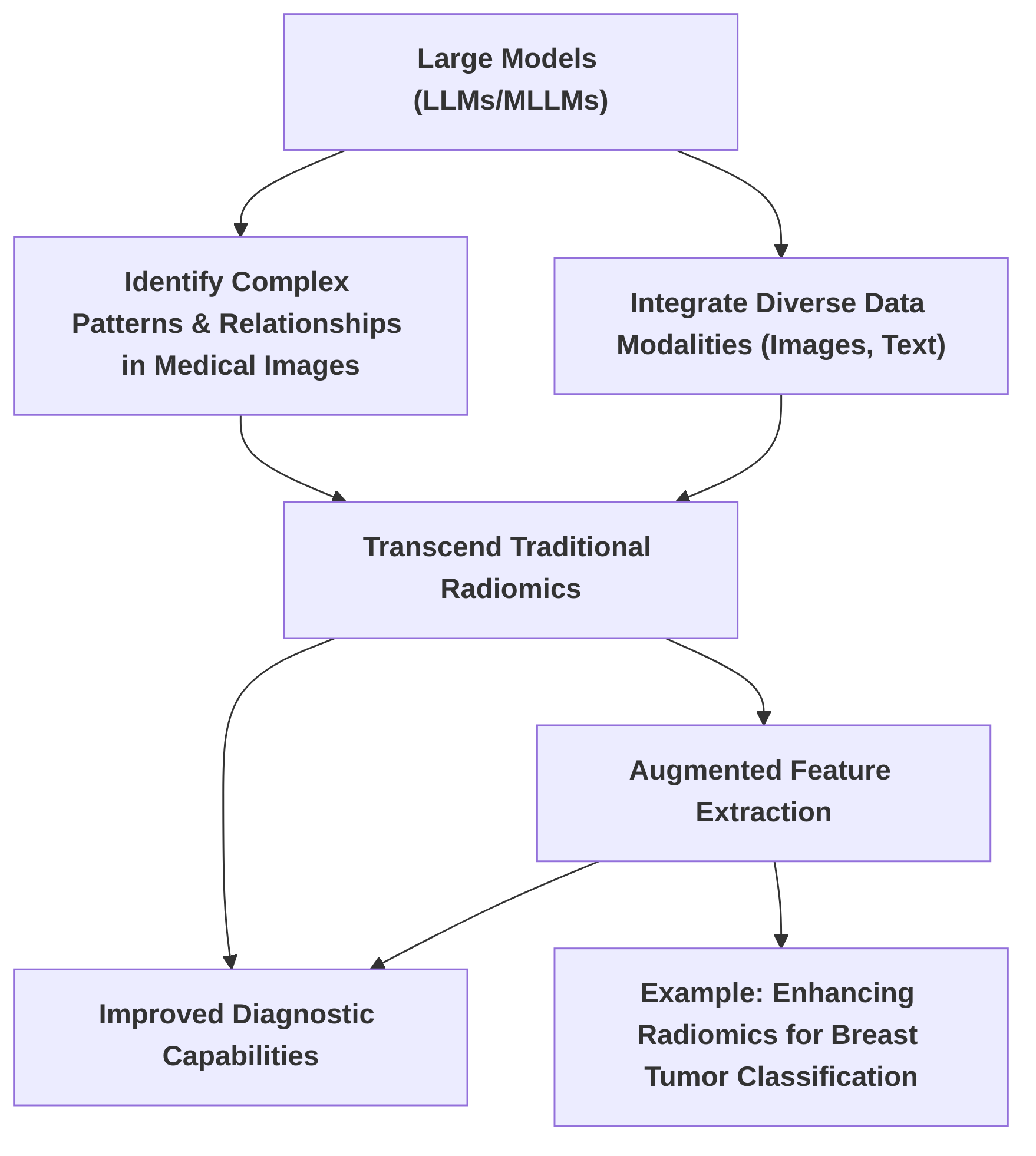
Second, "Advanced Feature Extraction and Radiomics Augmentation" discusses how large models transcend traditional radiomics by identifying complex patterns and relationships in medical images. It explores methods like "enhancing radiomics features via a large language model" for tasks such as breast tumor classification, analyzing commonalities in feature extraction, and identifying research gaps in feature interpretability . Future research should focus on developing more robust and clinically validated radiomics augmentation methods with enhanced interpretability.
Third, "Personalized Treatment Planning and Prognosis" examines how MLMs enable more personalized treatment strategies and accurate prognosis predictions through the integration of diverse patient information. It touches upon methodologies for risk stratification and outcome prediction, highlighting the potential of MLMs to integrate longitudinal imaging data for tracking disease progression . Research gaps exist in translating these predictive capabilities into actionable clinical recommendations, necessitating frameworks for MLM-based treatment personalization.
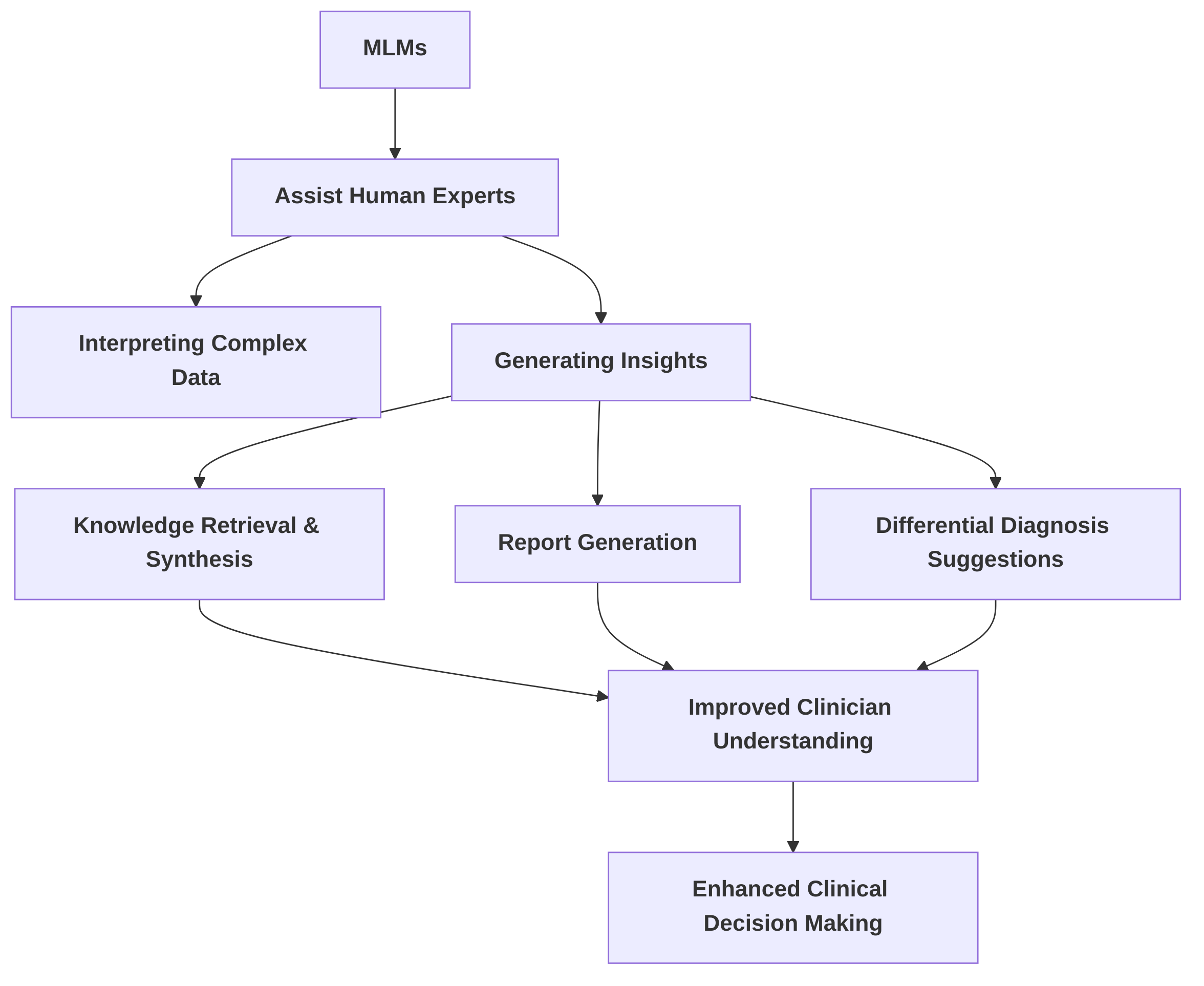
Fourth, "Enhanced Clinical Decision Support" explores the role of MLMs in assisting human experts in interpreting complex data and generating insights. It summarizes how these models facilitate knowledge retrieval, synthesis, report generation, and differential diagnosis suggestions . A significant challenge remains in seamlessly integrating these support systems into existing clinical workflows, underscoring the need for user-friendly interfaces and robust validation studies.
Finally, "
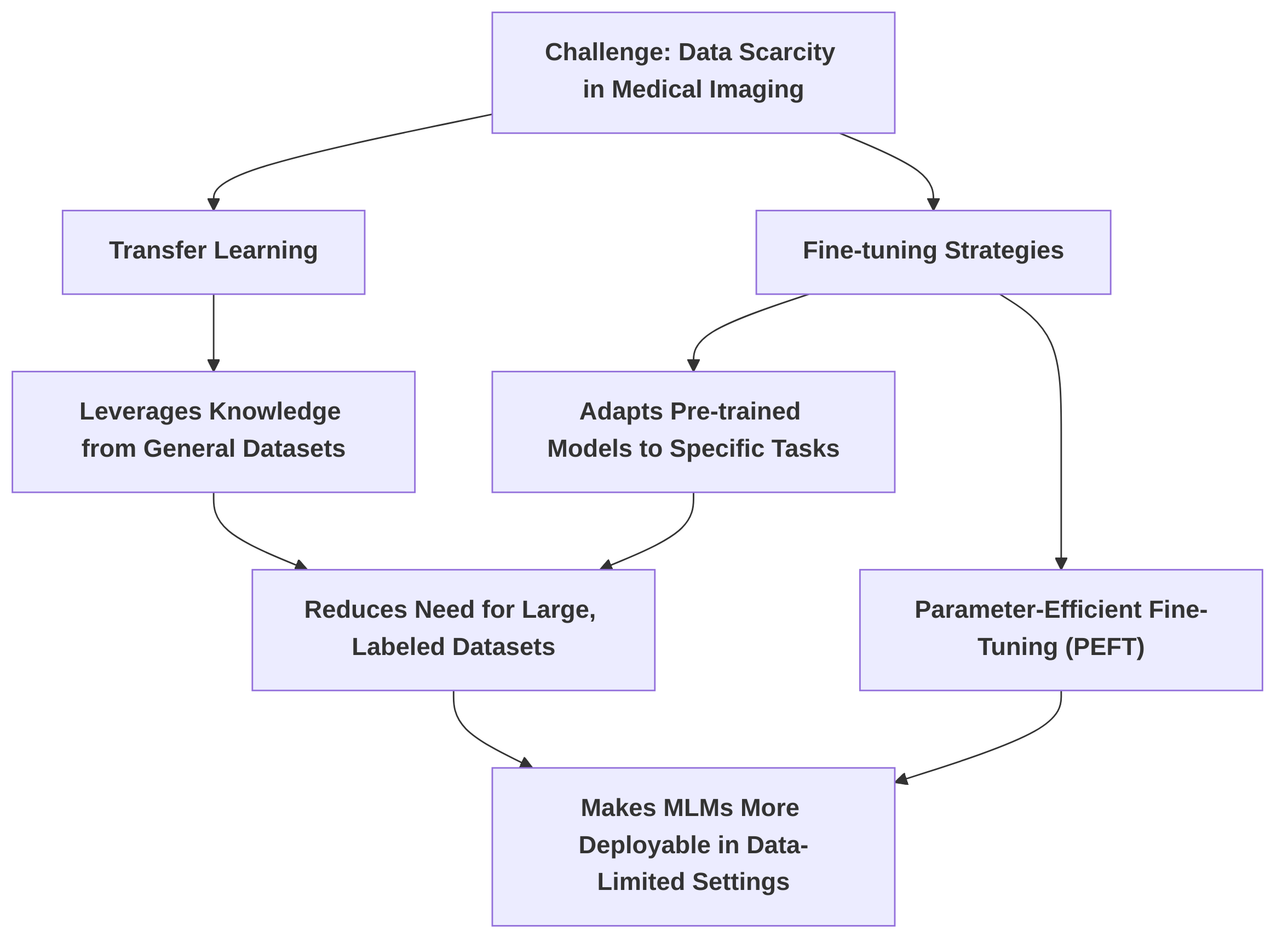
Overcoming Data Scarcity through Transfer Learning and Fine-tuning" addresses a critical challenge in medical imaging: data scarcity. This sub-section details how transfer learning and various fine-tuning strategies, including parameter-efficient methods like those proposed in , mitigate this issue, making MLMs more deployable in data-limited clinical settings . Future work should focus on optimizing fine-tuning strategies for diverse medical imaging tasks to enhance generalizability and efficiency.
Collectively, these opportunities underscore the transformative potential of MLMs in personalized medical image diagnosis. The analytical power of these models also holds promise for accelerating research and development (R&D) in medical research by identifying complex patterns and correlations across various data types. The success of general-purpose MLMs like Llama 3.2-90B in medical diagnostics suggests a promising direction towards leveraging larger, more versatile foundation models, potentially with further architectural innovations . However, translating these advancements into widespread clinical utility requires addressing persistent research gaps related to real-world validation, interpretability, seamless integration into workflows, and optimization of fine-tuning strategies for diverse medical tasks and specific R&D areas like drug discovery or clinical trial optimization.
3.1 Enhanced Diagnostic Accuracy and Precision
Multimodal Large Models (MLMs) have demonstrated a significant enhancement in diagnostic accuracy and precision by integrating diverse data modalities, often surpassing the capabilities of unimodal approaches and human experts in specific tasks . The fusion of medical images with clinical metadata, such as patient history, laboratory results, and genetic information, has been identified as a critical factor in achieving these performance gains .
Case studies illustrate the impact of multimodal integration. For instance, in the classification of benign and malignant breast tumors, an LLM-enhanced radiomics approach, combining textual information from diagnostic reports with mammography features, achieved a superior AUC of 0.92, outperforming radiomics-only (AUC of 0.86) and text-only (AUC of 0.79) methods . Similarly, transformer-based multimodal models have consistently outperformed unimodal approaches in various prediction tasks, including the diagnosis of Alzheimer's disease with high AUCs and improved predictions for heart failure and respiratory diseases . The integration of imaging and clinical data enhances diagnostic precision by providing a more comprehensive basis for clinical decision-making, allowing models to identify subtle patterns and correlations that might be missed by single-modality analysis .
Beyond specific disease classification, general-purpose MLMs have demonstrated remarkable superiority over human diagnoses. Evaluations have shown Llama 3.2-90B outperforming human performance in 85.27% of medical imaging tasks, with GPT-4 and GPT-4o exhibiting similar superiority rates of 83.08% and 81.72%, respectively . This advantage is particularly evident in complex scenarios such as abdominal CT interpretations, where MLMs can concurrently evaluate multiple anatomical structures and track disease progression, offering a more comprehensive diagnosis than human experts . This improvement is attributed to the models' ability to process vast quantities of data and discern intricate patterns that may be imperceptible to human diagnosticians.
Multimodal models also enhance diagnostic robustness by compensating for the limitations inherent in individual modalities . For instance, in COVID-19 detection, multimodal imaging data, incorporating X-ray, Ultrasound, and CT scans, yielded robust classification results, with Ultrasound notably achieving 100% sensitivity and positive predictive value for COVID-19 versus pneumonia classification . This complementarity ensures that even if one modality provides ambiguous or limited information, other modalities can provide corroborating or supplementary data, leading to a more reliable diagnosis. The common benefits cited for multimodal integration across studies include improved sensitivity and specificity, leading to more accurate disease detection and characterization .
Despite these significant advancements, research gaps persist in demonstrating the real-world clinical utility of these models. While many studies highlight improved accuracy, there remains a need for explicit statistical comparisons with baseline unimodal models and human diagnoses in prospective clinical settings to rigorously quantify the added value of multimodality . Future research should prioritize prospective validation studies with diverse patient populations and a wider spectrum of medical conditions to ensure the generalizability and robust application of multimodal AI models in varied clinical environments. This will also involve comparing performance across different image acquisition protocols and demographic groups to confirm reliability in real-world scenarios.
3.1.1 Superiority over Human Diagnosis in Specific Tasks
Multimodal large models (MLMs) have demonstrated significant advancements in diagnostic accuracy, occasionally surpassing human diagnostic capabilities in specific medical imaging tasks. A comprehensive evaluation of general-purpose MLMs revealed remarkable performance improvements over human diagnoses . For instance, Llama 3.2-90B exhibited superiority in 85.27% of evaluated cases, with only 1.39% rated as equivalent to human performance. Similarly, GPT-4 and GPT-4o demonstrated AI superiority in 83.08% and 81.72% of cases, respectively . These models' advantage is particularly pronounced in complex scenarios, such as abdominal CT interpretations, where they can simultaneously evaluate multiple anatomical structures, track disease progression, and integrate diverse clinical information for a more comprehensive diagnosis than human experts .
Beyond general-purpose MLMs, more specialized deep learning models, such as Convolutional Neural Networks (CNNs), have also shown superior diagnostic performance in narrowly defined tasks. For example, CNNs have outperformed radiologists in the diagnosis of pneumonia from chest radiographs. Their performance in lung nodule identification and coronary artery calcium quantification has been found to be comparable to human experts, indicating AI's potential to excel in specific, well-defined diagnostic areas .
The primary reasons for this observed superiority stem from AI's inherent capabilities in processing vast quantities of data and identifying subtle patterns that may be imperceptible or easily overlooked by human diagnosticians. The ability of MLMs to integrate diverse data modalities—such as medical images and clinical notes—enables a more holistic and nuanced diagnostic assessment. This data processing capacity allows AI to learn complex relationships and indicators of disease that might elude human perception, especially when dealing with high-dimensional data.
Despite these promising results, several research gaps remain regarding the generalizability of these findings. While AI models show significant superiority in specific tasks and complex scenarios, their performance across a wider spectrum of medical conditions and diverse patient populations requires further investigation. Many current studies, such as those focusing on COVID-19 detection or enhancing radiomics features, often do not include direct comparisons against human diagnoses, instead focusing on comparisons with other AI models or conventional methods . Furthermore, while LLMs like ChatGPT have demonstrated high proficiency in tasks like radiology board-style examinations or assessing the methodological quality of research, these do not directly translate to superior clinical diagnostic performance in specific medical imaging tasks . Therefore, future research needs to focus on rigorously testing the generalizability of multimodal AI models across varied pathologies, image acquisition protocols, and demographic groups to ensure their robust and reliable application in diverse clinical settings.
3.2 Advanced Feature Extraction and Radiomics Augmentation
Large models, particularly Large Language Models (LLMs) and Multimodal Large Models (MLLMs), are poised to significantly advance beyond traditional radiomics by identifying complex patterns and relationships in medical images, thereby enhancing diagnostic capabilities. While traditional radiomics extracts quantitative features from medical images, large models offer the potential for more sophisticated analysis through their ability to process and integrate diverse data modalities, including textual diagnostic reports and imaging data .
A notable approach in this domain is "enhancing radiomics features via a large language model," as demonstrated in the context of classifying benign and malignant breast tumors in mammography . In this methodology, an LLM processes textual diagnostic reports to generate embeddings, which are then fused with traditional radiomic features extracted from mammography images. This integration enriches the discriminative power of the features, leading to improved classification performance . The core principle involves leveraging the LLM's understanding of clinical knowledge, obtained through prompt engineering and fine-tuning, to augment selected radiomics features, enabling extensible learning across datasets by explicitly linking feature names with their values .
Commonalities in feature extraction techniques across large models include the utilization of advanced architectures like Transformers. The Transformer architecture, with its self-attention mechanisms, excels at deconstructing images into local features and apprehending interrelations among them. This capability enhances image recognition and analysis accuracy by effectively processing and integrating diverse data, including implicitly aiding in extracting richer features from medical data by combining imaging and clinical metadata . While many studies on deep learning in medical imaging, such as those focusing on general diagnostic impact or CNN classification capabilities, acknowledge feature extraction as a foundational step, they often do not explicitly detail how large models augment traditional radiomics beyond standard approaches . However, the inherent ability of general-purpose large multimodal models to process and integrate image and text data inherently enhances feature extraction and interpretation, offering a more comprehensive understanding of pathological findings compared to specialized vision models alone .
Despite these advancements, significant research gaps remain, particularly concerning the interpretability of these sophisticatedly extracted features. While large models demonstrate improved diagnostic performance, the mechanisms by which they synthesize information from various modalities and augment radiomics are often opaque. Future research should focus on developing more robust and clinically validated radiomics augmentation methods that prioritize interpretability. This includes creating transparent models that can explicitly articulate the clinical significance of the features they extract and the rationale behind their diagnostic decisions. Furthermore, validating these augmented radiomics methods across diverse patient populations and imaging modalities is crucial to ensure their generalizability and clinical utility, paving the way for their seamless integration into personalized medical image diagnosis workflows.
3.3 Personalized Treatment Planning and Prognosis
Multimodal Large Models (MLMs) hold significant promise for revolutionizing personalized medical care by integrating diverse patient information to enable more tailored treatment strategies and accurate prognosis predictions. The core strength of these models lies in their ability to synthesize information from various modalities, such as medical images, clinical records, genetic data, and patient histories, thereby providing a holistic view of a patient's condition. This integrated understanding is crucial for moving beyond population-level treatment guidelines towards individualized interventions.
While several papers acknowledge the potential of AI in predictive analytics for prognosis and treatment planning, specific methodologies for risk stratification and outcome prediction using multimodal large models are not extensively detailed across the reviewed literature. For instance, some studies broadly state that deep learning can facilitate more personalized diagnostic and treatment approaches and predict patient responses to treatments . Similarly, the integration of imaging and clinical data by multimodal AI models is suggested to lead to more personalized and precise predictions that can inform patient care, with examples like multimodal transformers used for survival prediction in intensive care or disease diagnosis by unifying information across modalities . Large Language Models (LLMs) are also noted for their potential to predict disease progression and support clinical decision-making , and to provide tailored medical counsel and treatment regimens by mimicking clinician diagnostic and therapeutic processes through multimodal data integration and contextual memory . However, the specific architectures or algorithmic frameworks that enable these granular predictions, such as detailed methods for risk stratification or the generation of precise, tailored therapeutic strategies based on integrated multimodal data, remain underexplored in the current digests. An isolated example mentions the improved prediction of overall survival in glioblastoma patients from MRI data using CNNs, but this is a limited illustration of AI's broader prognostic capabilities and does not specifically involve multimodal large models or comprehensive personalized treatment planning .
A promising future direction for MLMs in personalized medicine involves leveraging their capabilities to integrate longitudinal imaging data, such as multiple scans obtained over time, in conjunction with extensive clinical records. This approach is supported by the models' inherent ability to 'track disease progression', allowing for a more dynamic and accurate assessment of patient trajectories. By capturing the evolution of a disease and the patient's response to interventions, MLMs could provide highly refined prognostic insights and inform adaptive treatment planning. For instance, MLMs could analyze successive tumor volume changes from MRI scans, correlate them with specific drug regimens and genetic markers, and predict optimal future treatment modifications.
Despite these promising capabilities, significant research gaps exist in translating the predictive power of MLMs into actionable clinical recommendations. Current discussions often highlight the potential without detailing concrete frameworks or pipelines for how these sophisticated predictions can be seamlessly integrated into clinical workflows and directly inform physician decision-making for treatment personalization. Future work should therefore focus on developing robust methodologies that bridge this gap. This includes creating interpretable MLM outputs that clinicians can trust, designing user interfaces that facilitate the application of MLM-derived insights, and conducting rigorous clinical validation trials to demonstrate the efficacy and safety of MLM-guided personalized treatment strategies. Furthermore, research should explore ethical considerations and regulatory pathways for deploying such advanced predictive models in real-world clinical settings.
3.4 Enhanced Clinical Decision Support
Multimodal Large Models (MLMs) are increasingly recognized for their potential in enhancing clinical decision support by assisting human experts in interpreting complex medical data and generating actionable insights. Large Language Models (LLMs), a component of MLMs, can improve diagnostic accuracy, predict disease progression, and analyze extensive medical datasets, thus offering suggestions for potential diagnoses, differential diagnoses, and treatment options . This capability extends to integrating with existing radiology systems, providing preliminary assessments, and answering radiology-related queries . While some studies focus on the general diagnostic capabilities of AI, such as Convolutional Neural Networks (CNNs) providing probability outputs for conditions like pneumonia or pleural effusion, these implicitly function as a form of decision support . Similarly, advancements in Deep Learning (DL) have improved the accuracy, speed, and consistency of medical imaging diagnosis, offering more reliable information to clinicians .
LLMs also serve as powerful tools for knowledge retrieval and synthesis, crucial for clinicians to stay updated with the latest research and best practices . Their robust interactivity enables natural language dialogues, allowing doctors to query specific imaging data for closer examination . Furthermore, LLMs can provide natural language explanations and reasoning for diagnostic results, enhancing transparency and clinician understanding of the model's decision-making process . Systems like ChatCAD exemplify this, facilitating dialogue about disease, symptoms, diagnosis, and treatment, thereby empowering informed treatment choices . The MedSAM model is also noted for its potential in real-time explanations and addressing patient inquiries, further solidifying its role as an asset for clinical decision support .
Common functionalities of MLMs in decision support include report generation and differential diagnosis suggestions. Multimodal AI models, by integrating disparate forms of medical data such as clinical notes, imaging, and genomic information, can provide personalized predictions and recommendations . This integration allows them to assist in interpreting medical images and suggesting differential diagnoses . For instance, fine-tuned MLMs have demonstrated potential in Med-VQA (Medical Visual Question Answering) and Medical Report Generation (MRG), which indicates their utility as advanced clinical decision support tools by aiding in image interpretation and report creation . The improved classification accuracy for breast tumors using a multimodal approach, though not explicitly framed as a comprehensive decision support system, provides more robust diagnostic information derived from mammography, serving as a component within such a system . Similarly, models providing classification results for COVID-19 detection can serve as a "second pair of eyes" for medical professionals, assisting in diagnosis and criticality assessment . Some general-purpose multimodal models have even demonstrated diagnostic assessments that surpass human performance by integrating complex information from CT images and reports, thereby assisting clinicians in making more accurate diagnoses .
Despite these advancements, research gaps persist in the seamless integration of these support systems into existing clinical workflows. Many current studies do not explicitly detail how MLMs function as comprehensive clinical decision support systems, specifically concerning generating detailed reports or suggesting differential diagnoses based on complex medical images . While LLMs are being evaluated for their ability to assess research quality , their direct application in clinical diagnosis decision support still requires more specific demonstration. Future work should therefore focus on developing user-friendly interfaces that facilitate intuitive interaction with these complex models and rigorously validating their impact on clinical outcomes through large-scale, prospective studies.
3.5 Overcoming Data Scarcity through Transfer Learning and Fine-tuning
Data scarcity remains a pervasive challenge in medical imaging, where acquiring large, expertly annotated datasets is often resource-intensive and time-consuming. Transfer learning and fine-tuning emerge as critical strategies to mitigate this limitation, enabling the adaptation of pre-trained models to specialized medical domains with limited labeled data .
Transfer learning leverages knowledge gained from training on vast, generalized datasets (e.g., ImageNet) and applies it to specific medical tasks. For instance, in the context of COVID-19 detection from multimodal imaging data, pre-trained Convolutional Neural Networks (CNNs) with ImageNet weights, such as VGG19, demonstrated reasonable performance despite limited COVID-19 datasets. The effectiveness of VGG19, attributed to its better trainability on scarce datasets compared to more complex models, underscores the utility of transfer learning in challenging, data-constrained scenarios . Similarly, pre-training and subsequent fine-tuning strategies employed by Large Language Models (LLMs) facilitate transfer learning, which not only expedites model training but also substantially reduces annotation costs, a crucial factor when expert annotation is scarce . Studies have indicated that combining transfer learning with self-training can achieve performance comparable to models trained on significantly larger quantities of labeled data . The development of MedSAM, a fine-tuned version of the Segment Anything Model (SAM) specifically for medical image segmentation, exemplifies the potential of fine-tuning LLMs in medical imaging, demonstrating improved performance over the default SAM through a simple fine-tuning method .
While full fine-tuning, which updates all model parameters, can yield high performance, it demands substantial computational resources and large datasets. In contrast, parameter-efficient fine-tuning (PeFT) methods offer a compelling alternative. For example, the "parameter efficient framework for fine-tuning MLLMs" directly addresses the challenge of adapting large, pre-trained models to specialized medical domains with limited labeled data. This framework's emphasis on efficiency translates to better resource utilization, making model deployment feasible with less data. One such PeFT technique, Low-Rank Adaptation (LoRA), has been utilized to fine-tune LLMs for tasks such as classifying benign and malignant breast tumors in mammography. This approach effectively adapts pre-trained LLMs to specific tasks by training significantly fewer parameters, thereby enabling robust performance in data-limited scenarios . The ability of these models to reuse common features between training and unseen datasets, facilitated by explicit linking of feature names and values, further highlights their extensible learning capabilities, allowing adaptation to new datasets without exhaustive retraining .
The practical implications of these techniques for deploying Multimodal Large Models (MLMs) in clinical settings with varying data availability are significant. By reducing the reliance on massive, domain-specific datasets, transfer learning and PeFT democratize the application of advanced AI in healthcare. This allows for faster deployment of diagnostic tools in areas where data collection is challenging or patient populations are small. For instance, the ability of UniverSeg to achieve task generalization without additional training by learning task-agnostic models further enhances the utility of these approaches .
Despite these advancements, several research gaps remain in the optimization of fine-tuning strategies for diverse medical imaging tasks. A key area for future research involves developing more generalized and efficient fine-tuning methods that can adapt to a wider array of medical imaging modalities and diagnostic objectives without extensive re-engineering. This includes investigating adaptive fine-tuning approaches that dynamically adjust parameters based on the specific characteristics and volume of the target medical dataset. Further research is also needed to systematically compare the trade-offs between various PeFT methods (e.g., LoRA, prompt tuning, adapter-based methods) across different medical imaging tasks and model architectures, to establish best practices and guidelines for optimal deployment in real-world clinical scenarios.
3.6 Research and Development Acceleration
The analytical power of multimodal large models (MLMs) presents a significant opportunity to accelerate research and development (R&D) in personalized medical imaging and broader medical research by identifying complex patterns and correlations across diverse data types. Deep learning's capacity to analyze intricate datasets can enhance the understanding of diseases and potentially expedite discovery processes . Specific applications include improving diagnostic accuracy through the integration of imaging features with textual information, as demonstrated by the use of Large Language Models (LLMs) in classifying breast tumors . Such integration represents a foundational step towards developing more potent tools for feature extraction and interpretation, thereby accelerating the development of AI models for diagnosis .
MLMs can also streamline various research tasks. LLMs, for instance, facilitate the identification of high-quality research papers, detection of subtle correlations within data, and generation of critical insights . They can automate routine tasks such as text generation, summarization, and correction, leading to substantial time savings in research workflows. In radiology, these models can assist in the development of machine learning models and support code debugging for medical image analysis . Furthermore, LLMs improve transfer learning efficiency, enable better integration of multimodal data, and enhance clinical interactivity, contributing to cost-efficiency in healthcare . The development of models like MedSAM and UniverSeg, which aim to create universal tools for segmenting various medical objects, signifies a thrust towards accelerating research in image processing and advancing medical artificial general intelligence .
The success of general-purpose MLMs, such as Llama 3.2-90B, in comprehensive evaluations of multimodal AI models for medical imaging diagnosis , points towards a future where larger, more versatile foundation models are leveraged for medical diagnostics. This direction is further supported by the introduction of efficient fine-tuning methods for MLMs, which make these powerful models more accessible and adaptable for specific medical imaging research questions, including Visual Question Answering (VQA) and report generation . The development of an efficient evaluation framework for multimodal AI models further accelerates research by enabling rapid and systematic benchmarking, thereby identifying promising avenues for future development . Additionally, cutting-edge approaches like transformers and Graph Neural Networks (GNNs) can integrate diverse data types—including clinical notes, imaging, and genomics—to enhance patient care through personalized predictions, thereby accelerating research by facilitating more sophisticated analyses .
Despite these advancements, research gaps persist in the direct application of MLMs to specific R&D areas like drug discovery and clinical trial optimization. While some studies broadly acknowledge deep learning's potential to accelerate discovery , they often lack specific examples of how MLMs accelerate personalized medical imaging R&D, such as identifying novel biomarkers or streamlining clinical trial participant selection . Current literature largely focuses on diagnostic applications and image processing improvements rather than the direct impact on broader R&D initiatives . For instance, while LLMs can enhance the reliability of published research through quality assessment , this is an indirect contribution to R&D acceleration. Future research should focus on developing explicit frameworks and methodologies for leveraging MLMs to identify new disease insights, accelerate drug discovery pipelines by predicting molecular interactions or drug efficacy, and optimize clinical trial design through more precise patient stratification and outcome prediction. This requires bridging the gap between current diagnostic applications and the broader R&D landscape, potentially through architectural innovations that enhance the interpretability and predictive power of MLMs in these complex domains.
4. Challenges: Limitations and Obstacles in Implementation
The successful deployment of multimodal large models (MLMs) in personalized medical image diagnosis is hindered by several significant challenges, encompassing data availability and quality, model complexity and interpretability, inherent biases and ethical considerations, substantial computational resource requirements, and complex regulatory and clinical integration hurdles. This section delves into these limitations, highlighting current obstacles and identifying critical research gaps and future directions to foster the practical and equitable adoption of MLMs in healthcare.
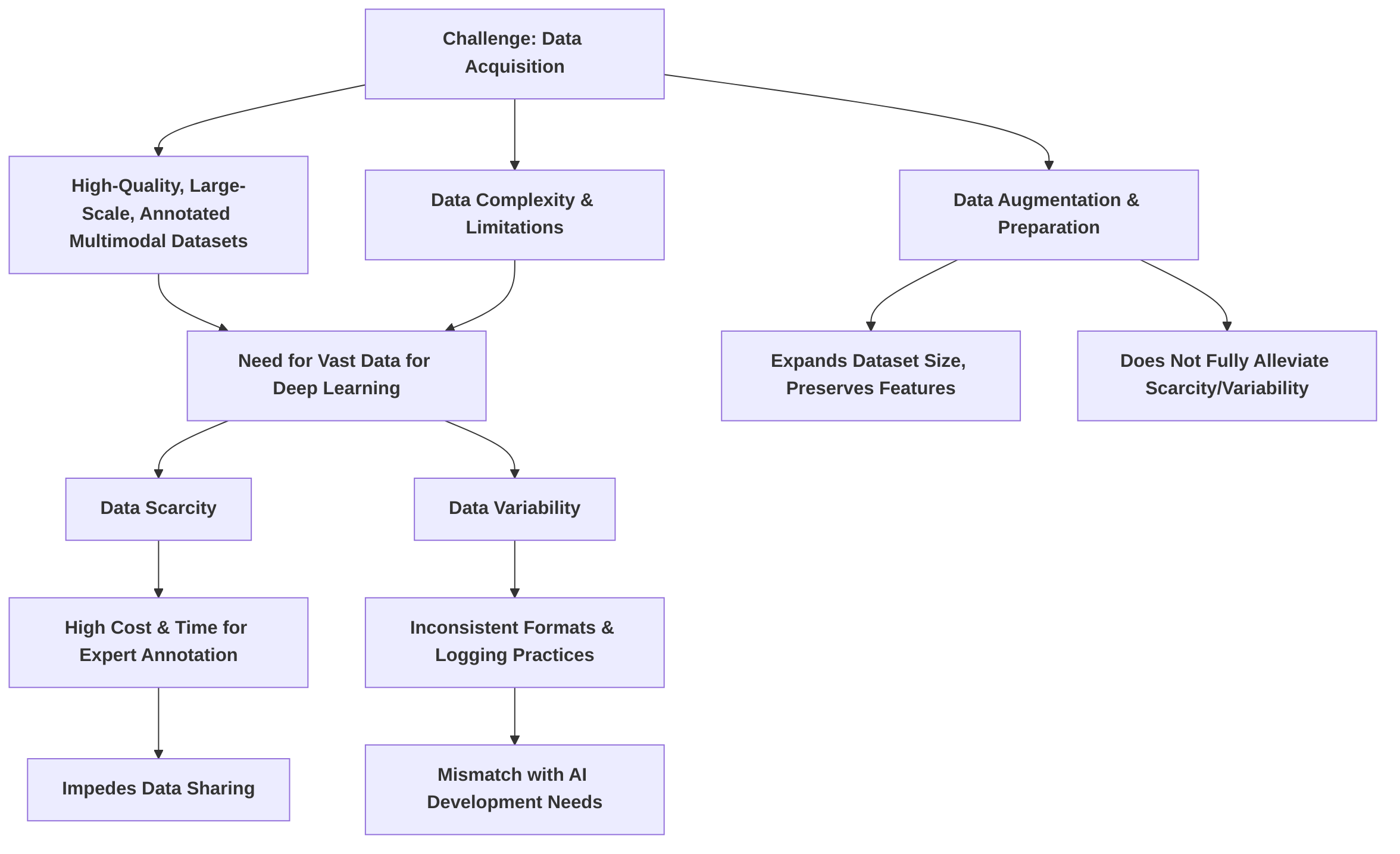
A foundational challenge is the acquisition of high-quality, large-scale, and meticulously annotated multimodal datasets. Medical data is inherently complex and often limited in quantity, contrasting sharply with the vast datasets typically required for training deep learning models . The process of data augmentation and preparation, while crucial for expanding dataset sizes and preserving diagnostic features, as demonstrated by the ability to augment 500 cases to 3,000 , does not fully alleviate the issues of underlying data scarcity and variability . Furthermore, technical difficulties arise in fusing heterogeneous data from disparate modalities and sources, due to inconsistent storage formats and varying logging practices across institutions, leading to a mismatch between current healthcare data management and AI development needs . Data scarcity is perpetuated by the high cost and time associated with expert annotation, compounded by inter-reader variability and equipment differences, leading to significant impediments in data sharing . Future research must focus on developing scalable annotation pipelines, advanced data augmentation techniques, and leveraging unsupervised or self-supervised learning to reduce reliance on extensive manual annotations.
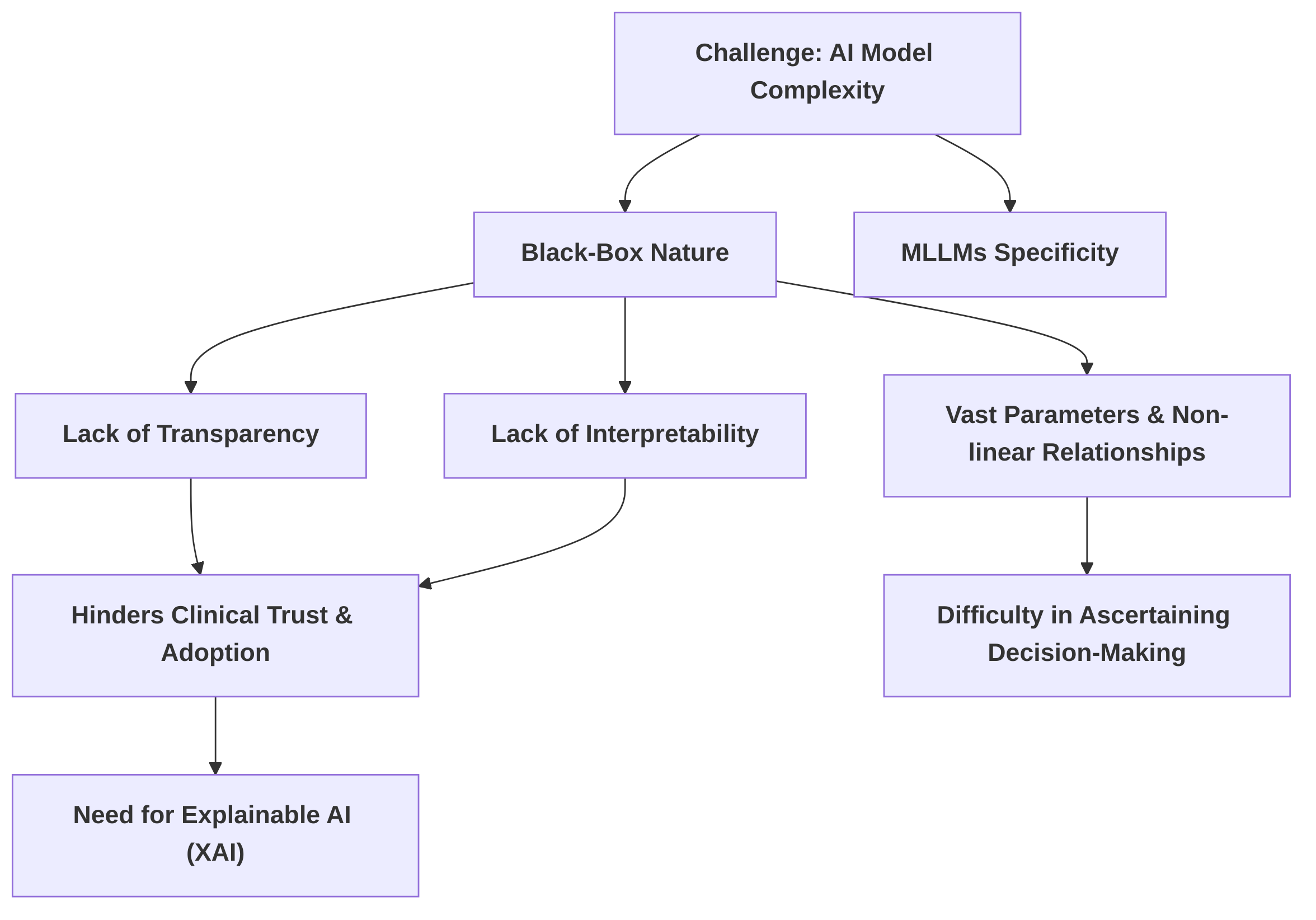
Another critical challenge pertains to the inherent complexity and "black-box" nature of contemporary AI models, particularly MLLMs, which impedes their transparency and interpretability . This lack of interpretability, where the intricate decision-making processes remain opaque, directly hinders clinical trust and adoption . The problem stems from the vast number of parameters and intricate non-linear relationships within these models , where increased predictive power often comes at the expense of interpretability . The critical need for Explainable AI (XAI) in medical diagnosis is widely recognized, with interpretability highlighted as a significant research gap for LLMs in clinical applications given their impact on patient safety . Future research should focus on robust, clinically relevant XAI methods for multimodal medical data, integrating insights from cognitive psychology and human-computer interaction to bridge the gap between complex AI decisions and human clinical reasoning.

Furthermore, the pervasive issue of bias in AI medical imaging systems carries significant implications for personalized diagnosis, potentially leading to inequitable healthcare outcomes. Sources of bias are multifaceted, originating from study design, datasets, modeling, and deployment phases, encompassing issues such as demographic imbalance, variations in image acquisition, and annotation bias . Homogeneous training data, often biased towards specific demographics or geographic regions, risks generating biased decisions and reduced generalizability . Despite the growing recognition of these issues, many studies in the field, such as , often overlook bias, fairness, and broader ethical considerations, representing a significant research gap for MLMs. The ethical landscape extends to patient privacy, model accountability, and equitable access to care, necessitating stringent data governance and transparent systems for risk management . Future research must prioritize the development of robust bias auditing frameworks and fairness-aware training algorithms, alongside standardized methods for detecting and mitigating bias in multimodal medical data.
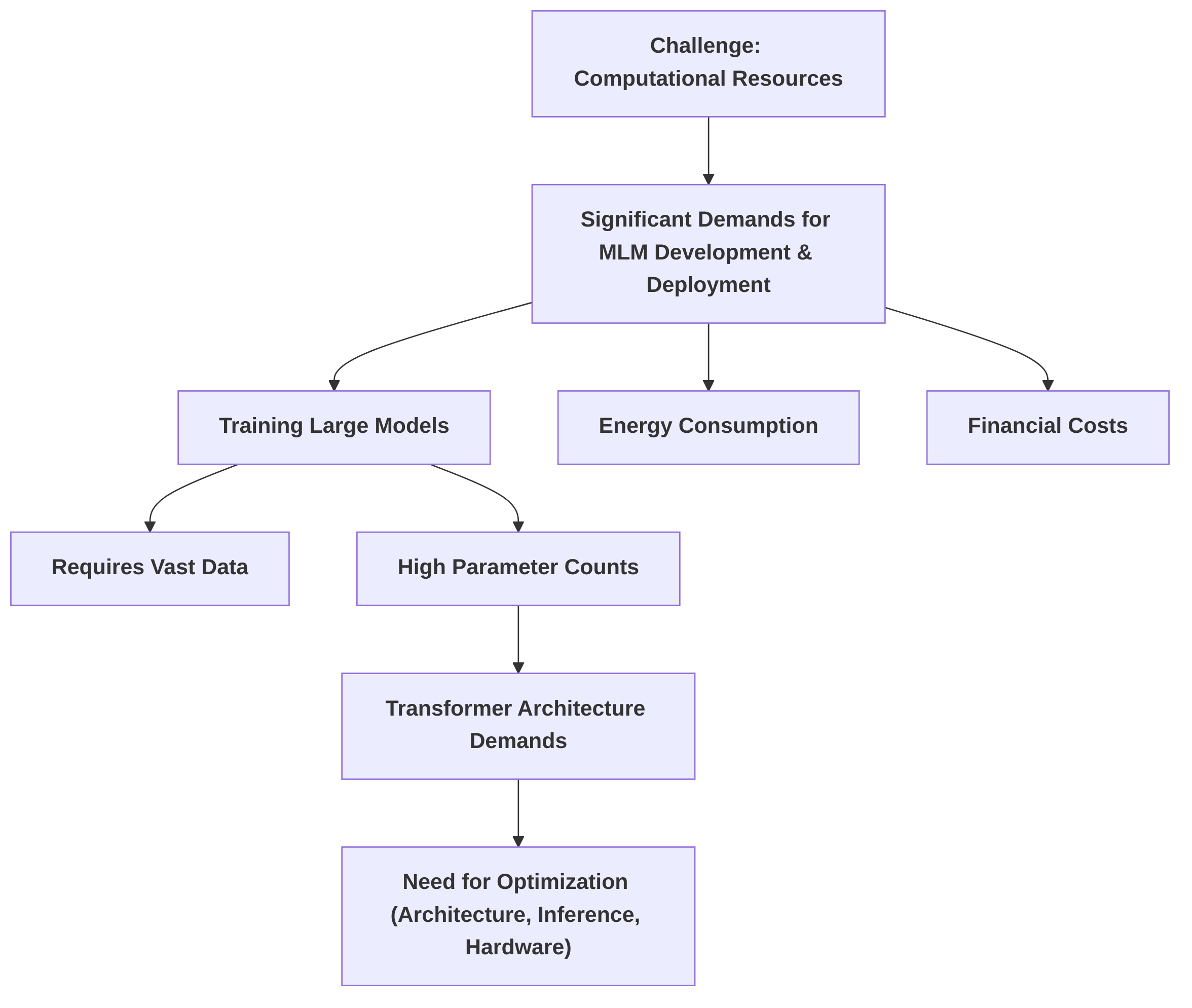
The development and deployment of MLMs also demand significant computational resources . The energy consumption and financial costs associated with training large models can be substantial . To mitigate these challenges, parameter-efficient fine-tuning (PEFT) techniques have emerged as a promising solution, significantly reducing computational costs compared to full model fine-tuning . Techniques like LoRA and the broader application of transfer learning contribute to more economical model development and deployment. However, a comprehensive comparison of trade-offs across different PEFT methods remains an area for further investigation. Research gaps exist in optimizing computational efficiency for resource-constrained environments, necessitating the development of more efficient model architectures and advanced distributed training strategies.
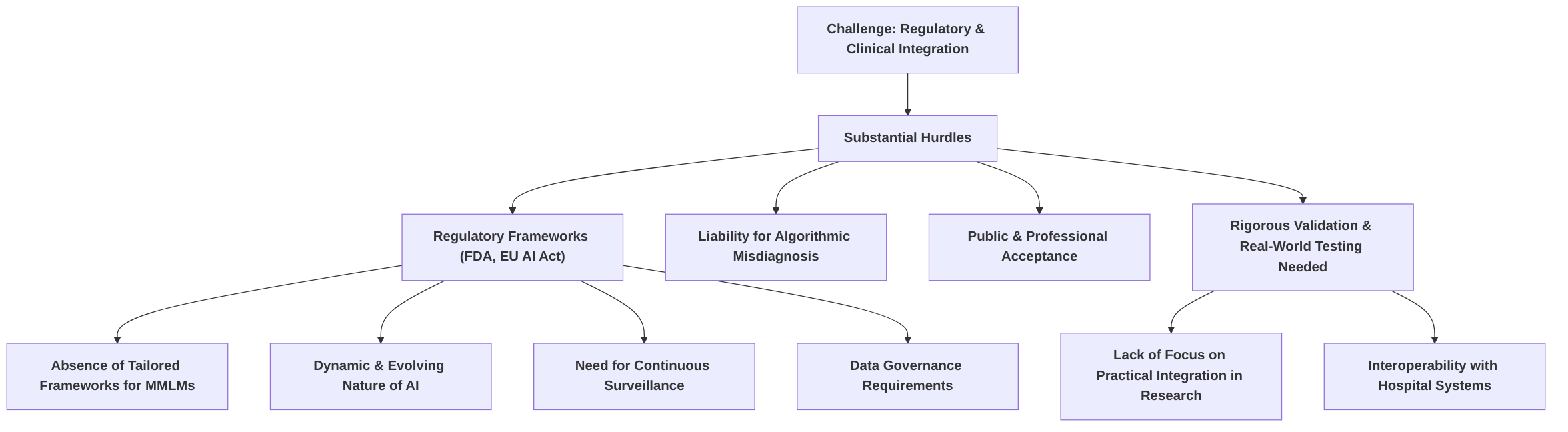
Finally, the regulatory and clinical integration of MMLMs faces substantial hurdles. While regulatory bodies like the FDA have approved some AI-based medical devices , fundamental questions persist regarding liability for algorithmic misdiagnosis and public acceptance. The absence of comprehensive and adaptable regulatory frameworks specifically for the dynamic nature of MMLMs complicates approval processes, demanding continuous surveillance and strict data governance for high-risk systems . Rigorous validation and real-world testing are critical for ensuring safe and effective clinical adoption , yet many current research efforts prioritize technical performance over practical integration or regulatory considerations . Future research must address these gaps by establishing clear regulatory pathways, developing standardized validation protocols, exploring regulatory sandboxes for iterative testing, and focusing on user-friendly interfaces and seamless integration into existing hospital information systems to ensure MLMs complement human expertise .
4.1 Data Availability, Quality, and Annotation
A significant hurdle in the development of multimodal large models for personalized medical image diagnosis is the acquisition of high-quality, large-scale, and well-annotated multimodal datasets. The inherent complexity of medical data, combined with the stringent requirements for AI model training, exacerbates this challenge. Deep learning algorithms, particularly those with a high number of parameters, necessitate vast amounts of data for effective training, often in the order of millions of samples, which contrasts sharply with medical datasets typically numbering in the hundreds to tens of thousands .
The complexities of data augmentation and preparation are critical for effective model training. While techniques such as de-identification, anomaly handling (e.g., image artifacts, text inconsistencies), and controlled spatial, intensity, and text augmentations can expand dataset sizes and preserve diagnostic features, as demonstrated by the expansion of an initial 500 cases to 3,000 in one study , these methods do not fully address the underlying challenges of acquiring diverse, high-quality multimodal medical data. For instance, in the context of COVID-19 detection, publicly available datasets were noted to be small and of highly variable quality, necessitating minimal data curation to avoid non-expert bias and the application of preprocessing pipelines like N-CLAHE to mitigate issues related to brightness, contrast, and noise .
Technical difficulties in fusing data from different modalities and sources further compound the problem. The heterogeneity and variable quality of multimodal medical datasets pose substantial challenges, leading to a mismatch between existing healthcare data storage practices and the specific requirements for AI development . Data is frequently stored in formats unsuitable for AI research, such as scanned PDFs, and logging methods vary considerably among physicians. This inconsistency makes effective data curation arduous and increases the risk of models being overtrained on limited, "AI-friendly" datasets, which can introduce database bias where models learn from specific settings, time periods, and patient populations, potentially leading to biased decisions in different clinical environments .
Data scarcity persists due to several factors. High-quality annotated datasets are a significant investment and a crucial resource . The need for expert consensus in annotation is paramount, yet inter-reader variability can introduce annotation bias stemming from subjective human labeling. Moreover, reference standard bias can affect label accuracy and reliability, while preprocessing techniques might inadvertently emphasize certain features, leading to further bias . The high cost and time involved in expert annotation, coupled with inherent differences in equipment between hospitals, make managing large-scale hospital imaging data particularly challenging. The relatively low adoption rate of Picture Archiving and Communication Systems (PACS), around 50-60%, indicates significant impediments to effective data sharing across institutions, further exacerbating data scarcity and contributing to the high cost of storing and operating hospital data .
Research gaps are evident in developing scalable and efficient data annotation pipelines. Current practices are often labor-intensive and expensive, necessitating innovative solutions. Future research should focus on advanced data augmentation techniques that are more sophisticated than simple transformations, ensuring the generated data maintains clinical relevance and diversity. Furthermore, a critical area for future investigation is the exploration of unsupervised or self-supervised learning methods. These approaches hold promise for significantly reducing reliance on extensive, manually annotated datasets by leveraging the vast amounts of unlabeled medical data available, thereby mitigating the current data scarcity and annotation challenges. This necessitates an industry-wide shift in how medical data is collected, stored, and managed to align with the demands of AI development .
4.2 Model Complexity, Interpretability, and Explainability
The inherent complexity of contemporary artificial intelligence (AI) models, particularly multimodal large models (MLLMs), presents a significant challenge to their clinical adoption: a lack of transparency and interpretability . This "black-box" nature, where the internal decision-making processes are opaque, directly hinders trust and inhibits integration into clinical workflows . The problem stems from the fundamental architecture of these models, characterized by vast numbers of parameters and intricate non-linear relationships, making it difficult to ascertain the precise features a neural network utilizes for classification or to explain how parameters attain their trained values . While simpler models, such as VGG16/19, may exhibit greater trainability and consistency with limited datasets, more complex architectures often sacrifice interpretability for enhanced predictive power .
The critical need for Explainable Artificial Intelligence (XAI) in medical diagnosis is increasingly recognized. Several studies highlight interpretability as a paramount requirement for LLMs in clinical applications, given their direct impact on patient safety . Despite this, the opacity of these models remains a significant research gap . The inherent complexity of LLMs, as demonstrated by their use in tasks like enhancing radiomics features for tumor classification, does not inherently come with detailed explanations of their diagnostic outputs .
The underlying reasons for this "black-box" nature are multi-faceted. The backpropagation mechanism, a cornerstone of deep learning, optimizes model parameters without providing explicit insight into the causal relationships between input features and output predictions . Furthermore, the sheer scale of MLLMs, encompassing billions of parameters, creates an intricate web of interdependencies that defy human comprehension. This complexity can also make bias detection cumbersome, as the internal workings are not readily accessible for scrutiny . The potential for AI outputs to be "confidently wrong" underscores the critical need for true interpretability to avoid misleading clinicians .
Research efforts in XAI aim to make AI more transparent. Proposed techniques to improve interpretability include attention and gradient visualization, adversarial testing, and natural language explanations . These methods are crucial for detecting weaknesses and providing more precise results. However, challenges persist in developing robust and clinically relevant XAI methods specifically for multimodal medical data. Future research should focus on integrating techniques from cognitive psychology and human-computer interaction to enhance the explainability and trust in these models. This interdisciplinary approach could lead to more intuitive and understandable explanations, bridging the gap between complex AI decisions and human clinical reasoning, thereby fostering greater clinical acceptance and improved patient outcomes.
4.3 Bias, Fairness, and Ethical Considerations in Personalized Diagnosis
The pervasive issue of bias in artificial intelligence (AI) medical imaging systems poses significant implications for personalized diagnosis, potentially leading to inequitable healthcare outcomes. Addressing these biases necessitates a comprehensive understanding of their fundamental issues, detection, avoidance, and mitigation strategies . The broader ethical landscape surrounding the deployment of these models in healthcare further complicates their integration . It is noteworthy that current research, such as that presented in , often overlooks bias, fairness, and ethical considerations, highlighting a critical research gap for multimodal large models (MLMs).
Bias in AI medical imaging systems stems from various sources within multimodal medical data, impacting fairness and equitable access to care. Key sources include demographic bias (e.g., gender, age, ethnicity), representation bias, sampling bias, aggregation bias, omitted variable bias, measurement bias, and propagation bias . For instance, reliance on specific, often curated, datasets like MIMIC can lead to models that are overfitted to particular settings, time periods, and patient populations, risking biased decisions and reduced generalizability . Such homogenous training data can cause AI algorithms to unequally weigh certain diagnoses based on socioeconomic status, race, or gender . Furthermore, the origin of training data, often predominantly from Western countries and in English, can lead to reduced representation of other regions and societal components, introducing novel sources of bias, especially in Large Language Models (LLMs) . The lack of diversity within development teams can further exacerbate these biases .
To address these biases, several mitigation strategies have been proposed. Robust data privacy measures, careful data selection and preprocessing, continuous monitoring and auditing of model outputs, and the employment of diverse and representative datasets are crucial for mitigating bias and ensuring fair medical decisions . Specifically, the explicit discussion of dataset bias emphasizes the need for guidelines to assess and mitigate bias, acknowledging that few analytical frameworks have been proposed or standardized in the field . While some papers identify bias, there remains a scarcity of concrete analytical frameworks to measure and address it, and few clinical papers systematically assess bias in specific AI models . For example, while the pre-processing steps in studies like aimed to reduce sampling bias from image quality variations, the broader framework for bias assessment and mitigation remains undeveloped.
Beyond bias, the ethical landscape of AI in diagnostic imaging is multifaceted. Key ethical considerations include patient privacy, accountability, and equitable access to care. Medical imaging data often contains sensitive personal health information, necessitating stringent handling to protect patient privacy and rights, often through data de-identification . Determining responsibility for AI-assisted medical care, especially when errors or misdiagnoses occur, is a pressing challenge, highlighting the need for transparent systems for model accountability and risk management . The World Health Organization's (WHO) principles for AI in healthcare emphasize human well-being, safety, inclusivity, and equity, alongside the necessity for informed consent and robust data governance . Radiologists must view AI tools as support systems, remaining mindful of their potential to exacerbate existing biases .
Despite the growing recognition of these issues, significant research gaps persist in developing standardized methods for detecting and mitigating bias in multimodal medical data. Current literature, as evidenced by papers like , primarily focuses on technical methodologies and performance improvements, often sidestepping detailed discussions on bias detection, mitigation strategies, or ethical implications. Future research must prioritize the development of robust bias auditing frameworks and fairness-aware training algorithms for multimodal large models. This will involve creating standardized metrics for quantifying bias, developing techniques for active bias mitigation during model training, and establishing clear guidelines for ethical deployment and accountability in personalized medical image diagnosis.
4.4 Computational Resources and Fine-tuning Efficiency
The development and deployment of multimodal large models (MLMs) in medical image diagnosis necessitate significant computational resources, primarily due to their extensive data requirements and high number of parameters . Training large language models (LLMs), which often form the textual backbone of MLMs, can incur substantial energy consumption and financial costs, potentially reaching thousands of US dollars per training instance, comparable to the energy expenditure of a transatlantic flight . Furthermore, the Transformer architecture, foundational to many LLMs and MLMs, intrinsically demands considerable computing resources and time for training, and operational speed for real-time capabilities often necessitates optimization of model architecture, efficient inference algorithms, and hardware acceleration techniques .
To address these formidable computational challenges and enhance accessibility, parameter-efficient fine-tuning (PEFT) techniques have emerged as a promising solution. A core contribution in this area is the development of parameter-efficient frameworks specifically for fine-tuning MLMs, aiming to reduce the computational cost significantly compared to full model fine-tuning . This efficiency is critical for making these advanced models more practical for diverse medical applications, especially in environments with limited computational infrastructure. For instance, techniques like LoRA (Low-Rank Adaptation) have been employed to achieve parameter efficiency during fine-tuning, requiring fewer computational resources than training the entire model from scratch . Similarly, transfer learning has been leveraged to accelerate training processes and mitigate issues stemming from limited data availability, thereby making model deployment feasible on more modest hardware configurations . Efficient transfer learning, facilitated by pre-training and fine-tuning, further contributes to more economical and efficient system development.
While PEFT methods offer substantial benefits in reducing computational demands, a comprehensive comparison of the trade-offs between different techniques—considering computational cost, performance metrics, and the number of trainable parameters—remains an area requiring further in-depth investigation. Existing literature broadly acknowledges the need for efficiency but often lacks detailed quantitative comparisons of various PEFT approaches in specific medical imaging contexts.
Despite advancements, significant research gaps persist in optimizing computational efficiency for training and deploying MLMs, particularly in resource-constrained environments. Future research should focus on developing more inherently efficient model architectures that can achieve high performance with fewer parameters and reduced computational overhead. Additionally, exploring advanced distributed training strategies could further alleviate the computational burden, enabling the utilization of MLMs even with limited local resources. Such advancements are crucial for democratizing access to cutting-edge AI in personalized medical image diagnosis.
4.5 Regulatory and Clinical Integration Hurdles
The integration of Multimodal Large Models (MMLMs) into personalized medical image diagnosis encounters substantial regulatory and clinical integration hurdles, despite the demonstrated potential of artificial intelligence (AI) in diagnostic imaging . While the U.S. Food and Drug Administration (FDA) has approved commercial AI-based medical devices and algorithms, suggesting a pathway for regulatory endorsement, significant questions persist regarding liability for algorithmic misdiagnosis and the broader acceptance of machine-driven diagnoses among both the public and medical professionals .
A primary challenge lies in the absence of comprehensive regulatory frameworks tailored specifically for the complexities of MMLMs. The dynamic and evolving nature of AI technologies, particularly those exhibiting characteristics of large language models (LLMs) used in medical imaging, complicates the establishment of clear and adaptable regulatory pathways . Such models, often unpredictable and complex, necessitate continuous surveillance, posing unique challenges for the regulatory approval process . The European Union's AI Act, for instance, attempts to address this by mandating rigorous data governance and bias mitigation for high-risk AI systems in healthcare, highlighting the global recognition of this challenge . However, a tension exists between stringent stipulations and the imperative for innovation, creating potential delays and complexity in the regulatory landscape .
Another significant hurdle involves the rigorous validation and real-world testing required to ensure safe and effective clinical adoption. While some studies underscore the importance of robust evaluation and the necessity for rigorous validation and real-world evidence for LLM integration into clinical workflows , many current research efforts primarily focus on technical performance on benchmark datasets or experimental validation of new approaches without addressing the practical challenges of clinical integration or regulatory approval . The absence of consensus on optimal fusion techniques and clear guidelines for multimodal AI also indicates significant standardization hurdles . Furthermore, the need for post-market surveillance and continuous monitoring for bias in real-world clinical settings is crucial to maintain safety and efficacy post-deployment .
The clinical integration of MMLMs necessitates future research into practical implementation strategies. This includes the development of user-friendly interfaces for clinicians and seamless integration into existing hospital information systems. While some papers acknowledge the potential of multimodal AI for clinical translation, they often defer the detailed discussion of practical integration strategies, focusing more on the technical aspects and data challenges . There is a recognized need for MMLMs to complement, rather than replace, human expertise, emphasizing the critical role of user interface design and workflow integration that supports collaborative decision-making .
Research gaps are evident in establishing clear and adaptable regulatory pathways for MMLMs. Future research should prioritize developing standardized validation protocols, potentially through multicenter validation efforts, to ensure the generalizability and reliability of MMLMs across diverse clinical settings . The exploration of regulatory sandboxes for iterative testing and approval could also facilitate more rapid and safe deployment of innovative MMLM solutions, enabling regulators and developers to collaboratively refine pathways in a controlled environment. Furthermore, addressing the underlying challenges of interpretability and hardware infrastructure is essential for the practical and ethical deployment of MMLMs .
5. Evaluation and Validation of Multimodal Models
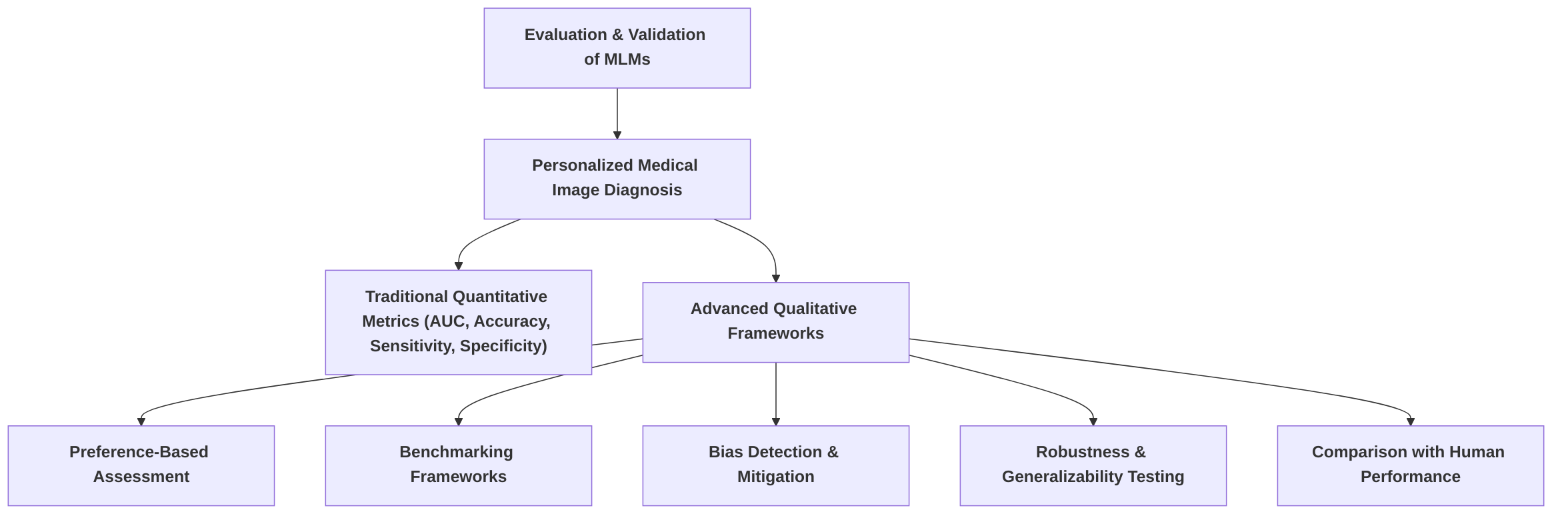
The evaluation and validation of Multimodal Large Models (MLMs) in personalized medical image diagnosis necessitate a multifaceted approach, integrating both traditional quantitative metrics and advanced qualitative frameworks. This section synthesizes common evaluation methodologies, critically analyzes the emergence of preference-based assessment, proposes a robust benchmarking framework, highlights crucial research gaps, and discusses the challenges of clinical validation and regulatory hurdles.
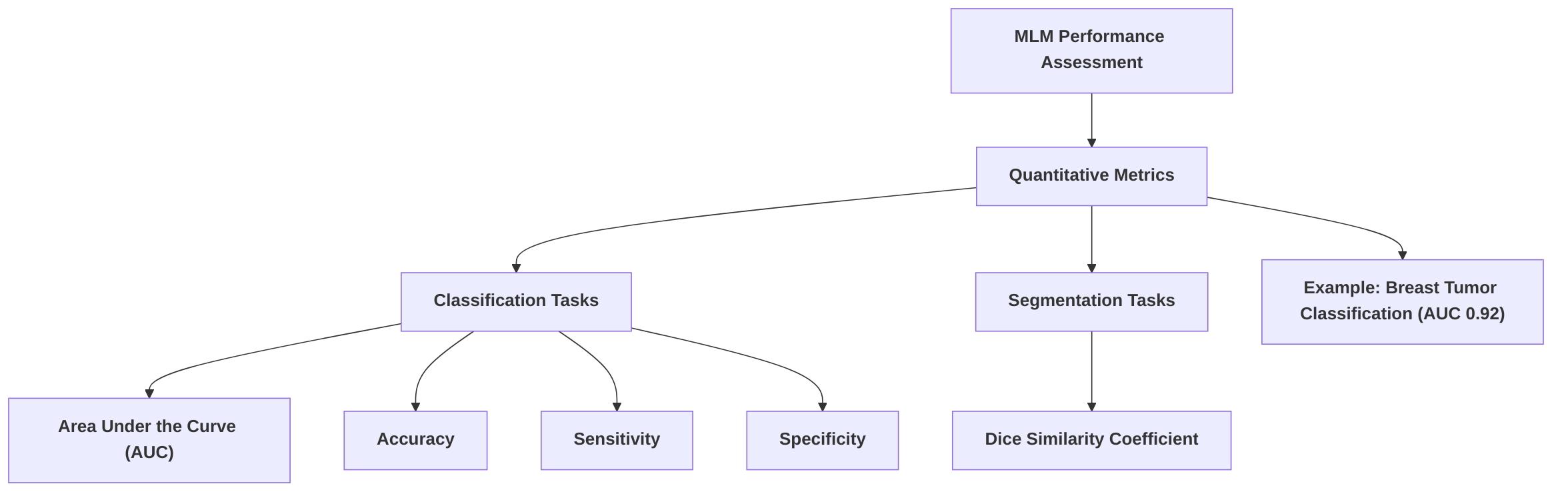
Performance assessment of MLMs commonly relies on quantitative metrics such as Area Under the Curve (AUC), accuracy, sensitivity, and specificity for classification tasks, as demonstrated in studies on breast tumor classification where multimodal approaches achieved AUCs of 0.92 . Accuracy metrics, like 0.671 on VinDr-Mammo and 0.839 on INbreast datasets, further indicate model effectiveness and generalizability . For tasks like COVID-19 detection, precision, recall, and F1 scores are utilized across various imaging modalities , while segmentation tasks frequently employ the Dice similarity coefficient, as seen with models like MedSAM . While these metrics provide foundational insights, a critical gap exists in systematically comparing multimodal models against unimodal baselines to unequivocally demonstrate the added value of multimodal integration .
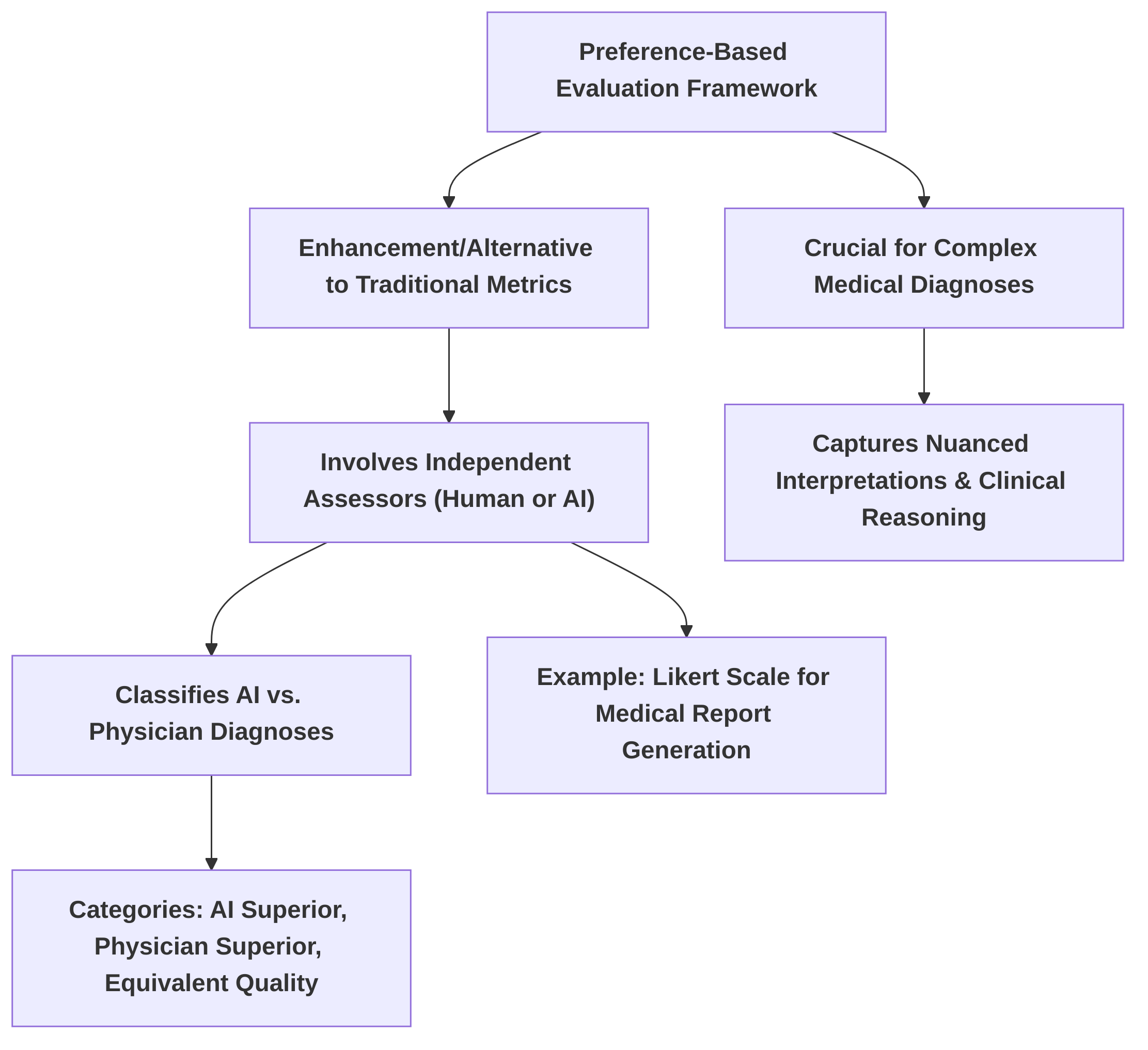
The preference-based evaluation framework marks a significant advancement, offering a crucial alternative or enhancement to traditional metrics for complex medical diagnoses . Unlike scalar metrics, this framework, utilizing independent assessors or AI models like Claude 3.5 Sonnet, classifies AI-generated diagnoses against physician-authored reports into categories such as "AI superior," "physician superior," or "equivalent quality" . This approach is critical because medical diagnosis involves nuanced interpretations, contextual understanding, and clinical reasoning that cannot be fully captured by simple quantitative scores. For Medical Report Generation (MRG) tasks, a 5-point Likert scale annotated by human experts and GPT-4 provides a more granular assessment of diagnostic quality, emphasizing semantic similarity over mere factual correctness . This qualitative dimension ensures evaluations reflect real-world clinical demands where diagnostic accuracy is intertwined with clinical appropriateness and physician trust.
A robust benchmarking framework for MLMs should encompass several key components, drawing from comprehensive evaluation strategies . This framework must integrate quantitative metrics, qualitative and preference-based evaluations with expert human and AI assessor feedback , systematic bias detection and mitigation strategies utilizing tools like PROBAST and QUADAS-2 , robustness and generalizability testing across diverse datasets , and direct benchmarking against human performance, as seen in evaluations of LLMs against radiologists in quality assessment tasks . Research gaps persist in developing task-specific and clinically relevant evaluation metrics that directly correlate with patient outcomes and clinical workflow efficiency. Future research must prioritize establishing standardized, diverse, and expertly annotated benchmark datasets and evaluation protocols to ensure reproducibility and comparability across studies.

A significant gap remains between research prototypes and clinically deployable solutions. Clinical validation necessitates rigorous, often multicenter, prospective trials to assess generalizability and robustness in diverse real-world scenarios . Current literature often focuses on technical development using retrospective data, overlooking the critical steps for clinical integration . Regulatory hurdles pose substantial barriers, with MLMs increasingly subject to medical device regulations . Frameworks like the European Union's AI Act emphasize rigorous testing and continuous monitoring to mitigate harms and biases . Unresolved issues of liability and public acceptance further complicate adoption . Research gaps lie in the lack of detailed discussions on regulatory approval processes and the imperative for real-world evidence . Future research must conduct prospective clinical trials and develop evidence-based guidelines for regulatory bodies to facilitate integration into personalized medical image diagnosis.
Comparative analyses with human radiologists and traditional diagnostic approaches reveal nuanced performance. Early AI models, like Convolutional Neural Networks (CNNs), demonstrated comparable or superior performance to radiologists in specific tasks, such as pneumonia diagnosis from chest radiographs . More recent evaluations involving LLMs indicate their near-passing performance on radiology board-style examinations . A study comparing LLMs (ChatGPT and NotebookLM) with a human radiologist in assessing methodological quality of radiomics research demonstrated significant agreement, highlighting MLMs' consistent evaluation capacity . In direct diagnostic performance, general-purpose MLMs like Llama 3.2-90B showed significant superiority in complex abdominal CT interpretation, outperforming human diagnoses in 85.27% of cases . However, many studies still lack explicit comparisons with human experts, often focusing on technical capabilities and data integration rather than head-to-head performance evaluations . Research gaps persist in comprehensive comparative analyses across diverse medical imaging tasks, with future work needing to rigorously validate MLM performance against established clinical standards and expert consensus. This requires more explicit, robust comparisons across a wider range of medical imaging modalities and diagnostic scenarios, accounting for clinical variability and real-world applicability.
5.1 Performance Metrics and Benchmarking
Evaluation of Multimodal Large Models (MLMs) in personalized medical image diagnosis commonly employs a range of quantitative metrics to assess performance. These often include Area Under the Curve (AUC), accuracy, sensitivity, and specificity, particularly in classification tasks such as distinguishing benign from malignant breast tumors . For instance, one study reported AUCs of 0.92 for multimodal approaches, significantly outperforming unimodal radiomics (0.86) and text-based classification (0.79) in breast tumor classification . Accuracy metrics, such as 0.671 on VinDr-Mammo and 0.839 on INbreast datasets, are also frequently cited to demonstrate model effectiveness and extensible learning capabilities . Other common metrics in classification tasks include precision, recall, and F1 score, which are used to evaluate models on tasks like COVID-19 detection across various imaging modalities . For segmentation tasks, the Dice similarity coefficient is a prevalent metric, as seen in evaluations of models like MedSAM . While these traditional metrics provide quantitative insights into model performance, the field often lacks a critical comparison against baseline unimodal models or clear evidence demonstrating the added value of multimodal integration .
The emergence of preference-based evaluation frameworks marks a significant advancement, offering a qualitative alternative or enhancement to traditional metrics, particularly for complex medical diagnoses . Unlike simple accuracy or F1 scores, a preference-based system, as described in one study, employs an independent assessor (e.g., Claude 3.5 Sonnet) to classify the quality of AI-generated diagnoses relative to physician-authored diagnoses into categories such as "AI superior," "physician superior," or "equivalent quality" . This approach is crucial because medical diagnosis often involves nuanced interpretations, contextual understanding, and clinical reasoning that cannot be fully captured by scalar metrics. For instance, in Medical Report Generation (MRG) tasks, a proposed metric leveraging a 5-point Likert scale, annotated by human experts and GPT-4, offers a more granular assessment of diagnostic quality by considering semantic similarity beyond simple factual correctness . The preference-based framework moves beyond quantitative performance to assess clinical utility and diagnostic relevance, addressing the need for evaluations that reflect real-world clinical demands where the "correctness" of a diagnosis can be subjective and multifactorial. This is particularly vital in personalized medicine, where diagnostic accuracy is intertwined with clinical appropriateness and physician trust.
For robust benchmarking of MLMs, a comprehensive evaluation strategy is essential. Drawing from the insights in , a proposed framework should encompass:
- Quantitative Metrics with Context: Continue using traditional metrics (AUC, accuracy, sensitivity, specificity, Dice similarity) but always provide comparisons against strong unimodal baselines to justify multimodal integration .
- Qualitative and Preference-Based Evaluation: Integrate expert human and AI assessor feedback (e.g., Likert scales, "AI superior" classifications) to evaluate diagnostic quality, clinical utility, and semantic accuracy, especially for complex report generation or diagnostic reasoning tasks .
- Bias Detection and Mitigation: Implement systematic checks for dataset, model development, and deployment biases through comprehensive data analysis, code reviews, testing on unseen data, explainability analysis, and user feedback, utilizing tools like PROBAST and QUADAS-2 for risk assessment .
- Robustness and Generalizability Testing: Evaluate model performance across diverse and unseen datasets to ensure generalizability and assess how well models adapt to new clinical scenarios .
- Benchmarking against Human Performance: Wherever feasible, compare MLM performance directly against human expert performance, as seen in attempts to benchmark LLMs against radiologists in quality assessment tasks .
Despite advancements, significant research gaps exist in the development of task-specific and clinically relevant evaluation metrics for MLMs. Many current evaluations rely on generic computer vision or natural language processing metrics that may not fully capture the nuances of medical diagnosis. There is a pressing need for metrics that directly correlate with patient outcomes, clinical workflow efficiency, and physician trust. Future research should prioritize establishing standardized benchmark datasets that are diverse, representative, and rigorously annotated by multiple medical experts. Alongside these datasets, standardized evaluation protocols are necessary to ensure reproducibility and comparability across different MLM studies. This includes developing clear guidelines for multimodal data fusion evaluation, defining success criteria that reflect clinical impact, and fostering collaborative efforts to create publicly available, ethically sourced medical imaging and corresponding textual datasets to accelerate unbiased and robust MLM development.
5.2 Clinical Validation and Regulatory Aspects
Despite rapid advancements in Multimodal Large Models (MLMs) for medical image diagnosis, a significant gap persists between research prototypes and clinically deployable solutions. The translation of research findings into widespread clinical practice necessitates rigorous clinical validation and navigation of complex regulatory landscapes.
A primary challenge lies in the generalizability and robustness of models developed on retrospective datasets to diverse real-world clinical scenarios . While several papers implicitly acknowledge the need for rigorous evaluation before widespread application, specific details on clinical validation processes, such as the necessity for multicenter trials and the collection of real-world evidence for deployment, are often not explicitly discussed in much of the current literature . Many studies focus primarily on technical aspects of model development and performance evaluation using retrospective data or public benchmark datasets, overlooking the critical steps required for clinical integration .
Regulatory hurdles represent another substantial barrier to adoption. The FDA's approval of commercial AI-based medical devices and algorithms marks an initial step, yet comprehensive regulatory frameworks for complex MLMs, particularly those with continuous learning capabilities, remain nascent . Large Language Models (LLMs) and MLMs used in healthcare are increasingly likely to be regulated as medical devices, which entails stringent requirements for validation, clinical trials, and clear regulatory pathways . The European Union's AI Act, for instance, offers a framework for high-risk AI in healthcare, emphasizing the importance of rigorous testing, validation, and ongoing monitoring to mitigate harms and biases . Key ethical and regulatory questions, such as public and physician acceptance of machine diagnoses and the unresolved issue of liability for algorithm misdiagnoses, further complicate implementation . Challenges in data sharing, often due to patient privacy concerns, also impede the development of robust and generalizable AI tools .
Research gaps in the translation of findings into clinical practice are evident. Current research often lacks detailed discussions on specific regulatory challenges, approval processes, or the imperative for real-world evidence crucial for clinical deployment . Future research must prioritize conducting prospective clinical trials to generate robust evidence of MLMs' efficacy and safety in diverse patient populations. Furthermore, developing evidence-based guidelines for regulatory bodies is essential to establish clear pathways for the approval and integration of these transformative technologies into personalized medical image diagnosis.
5.3 Comparison with Human Experts and Traditional Methods
The comparative performance of Multimodal Large Models (MLMs) against human radiologists and traditional diagnostic approaches reveals a complex landscape, showcasing areas of potential superiority alongside identified research gaps. Early investigations into the capabilities of AI, specifically Convolutional Neural Networks (CNNs), demonstrated performance comparable to human radiologists in tasks such as lung nodule identification and coronary artery calcium quantification. Notably, CNNs exhibited enhanced diagnostic performance over radiologists in the diagnosis of pneumonia from chest radiographs . While these findings indicate the promise of AI in specific diagnostic contexts, the general assertion of improved accuracy, speed, and consistency by deep learning models often lacks specific comparative metrics against human expertise or traditional methods .
More recent evaluations involving Large Language Models (LLMs) and MLMs have provided more direct comparisons. For instance, LLMs like ChatGPT have been noted to approach the performance of radiologists in knowledge-based assessments, as evidenced by their ability to "almost pass a radiology board-style examination" . Beyond knowledge assessment, a study directly evaluated the methodological quality of radiomics research, comparing LLMs (ChatGPT and NotebookLM) with a human radiologist. This research highlighted LLMs' significant agreement with human experts in identifying methodological flaws and adhering to quality standards, implicitly critiquing the potentially subjective nature of manual review through demonstration of LLMs' consistent evaluation capacity . This illustrates LLMs' utility in research evaluation, though not directly in clinical diagnosis.
In the realm of direct diagnostic performance, a comprehensive evaluation explicitly compared multimodal AI models (including Llama 3.2-90B, GPT-4, GPT-4o, BLIP2, and Llava) against human diagnoses in complex abdominal CT interpretation tasks. This study reported significant superiority of general-purpose MLMs, with Llama 3.2-90B demonstrating superior performance in 85.27% of cases compared to human diagnoses . Such findings implicitly critique human expert performance by highlighting instances of AI's diagnostic advantage, particularly in intricate scenarios.
Conversely, some studies involving MLMs and traditional methods do not offer explicit comparisons with human experts. For example, some multimodal AI models are compared against traditional radiomics analysis and text-based report analysis rather than human radiologists, showing superiority over conventional radiomics features, especially in extensible learning across datasets . Similarly, while AI-assisted software for X-ray interpretation can autonomously detect abnormalities and aid physicians, direct comparative data of LLMs against human experts in this context are often not detailed .
Several research gaps persist in comprehensive comparative analyses across diverse medical imaging tasks. Many papers do not present instances where multimodal AI models are compared against human experts or traditional diagnostic methods, nor do they document findings regarding their comparative strengths and weaknesses . The focus of much current research tends to be on technical capabilities and data integration rather than direct head-to-head performance evaluations with clinical experts. While AI has the potential to mitigate cognitive biases in human interpretation, the discussion often centers on AI's inherent biases rather than a direct performance comparison . Future work must prioritize rigorously validating MLM performance against established clinical standards and expert consensus. This requires more studies conducting explicit, robust comparisons across a wider range of medical imaging modalities and diagnostic scenarios, moving beyond specific tasks to comprehensive, integrated diagnostic pipelines. Furthermore, the challenges of consistently curating multimodal AI work across institutions and the trade-offs between smaller, higher-accuracy multimodal samples and increased bias risk necessitate further research into robust evaluation methodologies that account for clinical variability and real-world applicability.
6. Future Directions and Research Gaps
The rapid evolution of Multimodal Large Models (MLMs) in personalized medical image diagnosis presents both promising avenues for advancement and critical research gaps that must be addressed to ensure their safe, effective, and widespread clinical integration. Future efforts should focus on innovative model designs, robust data handling, enhanced interpretability, and the establishment of comprehensive ethical and regulatory frameworks. This section outlines key directions and priorities for propelling MLMs from research prototypes to indispensable clinical tools.
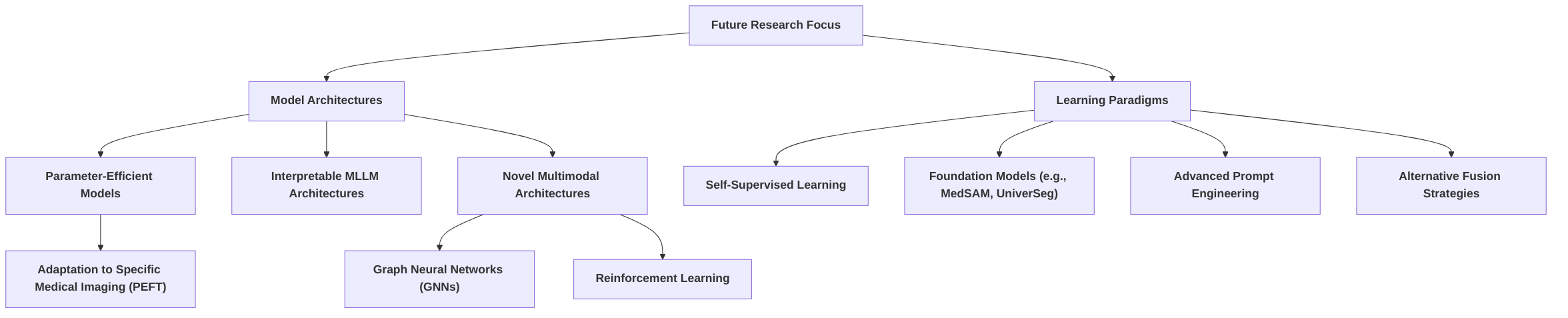
A primary focus for future research lies in advancing model architectures and learning paradigms. This includes overcoming current architectural limitations by developing more parameter-efficient models and inherently interpretable MMLM architectures . Projecting forward, the development of novel multimodal architectures and learning paradigms is crucial, potentially incorporating techniques from other fields such as graph neural networks or reinforcement learning to improve performance and efficiency . Continued exploration of self-supervised learning and foundation models, particularly those tailored for medical data like MedSAM and UniverSeg, will enable the creation of more adaptable and generalizable models . Furthermore, research into different LLM architectures, sophisticated prompt engineering techniques, and alternative fusion strategies for enhancing radiomics features remains vital for improving diagnostic capabilities and model adaptability .
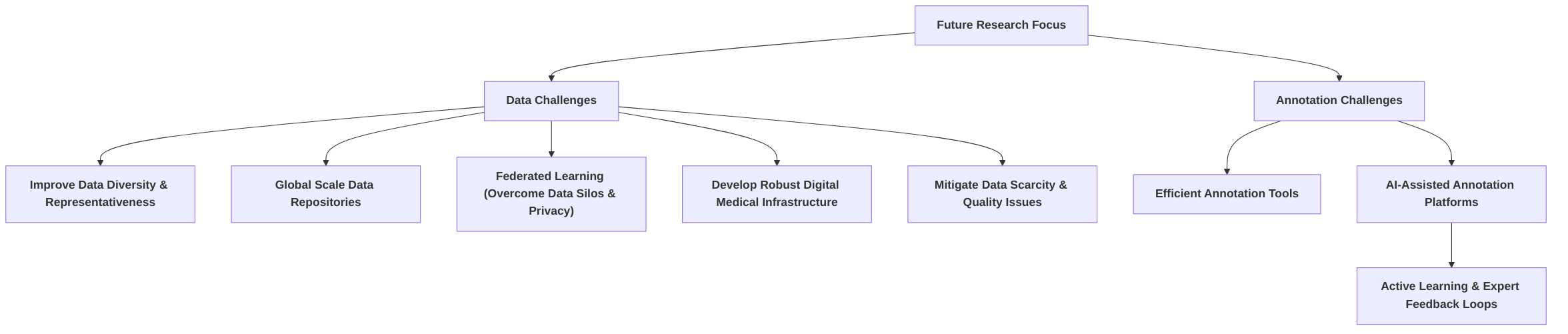
Addressing persistent data and annotation challenges is another critical area. Strategies for overcoming data-related hurdles include improving data diversity and representativeness on a global scale to compile larger, more inclusive data repositories from diverse demographic groups and geographic regions . Federated learning emerges as a promising strategy to overcome data silos and privacy concerns, allowing for the development of more generalizable and robust multimodal models by leveraging distributed datasets without direct sharing . Future research should also investigate more automated or efficient annotation methods, such as AI-assisted annotation platforms that integrate active learning and expert feedback loops, to address ongoing data quality and annotation challenges and reduce the laborious nature of manual annotation .

Enhancing interpretability and trust is paramount for clinical adoption. Future research priorities include developing and evaluating methods for explaining the diagnostic reasoning of MLMs in medical imaging, such as attention mechanism visualization or generating natural language explanations, to increase clinician trust and facilitate understanding of model decisions . Beyond interpretability, rigorous auditing of bias and fairness across demographic groups in high-performing MLMs, and testing their robustness against adversarial attacks or distribution shifts in real-world clinical data, are essential to ensure equitable and reliable performance . The inherent "black box" nature of many deep learning models necessitates continued focus on Explainable AI (XAI) to build clinician confidence and aid debugging processes .
Establishing comprehensive ethical guidelines and regulatory frameworks that can keep pace with the rapid advancements in AI is critical for patient safety and societal benefit. This necessitates a roadmap that supports continuous human oversight throughout the AI lifecycle in radiology . Interdisciplinary collaboration between AI researchers, clinicians, ethicists, and policymakers is crucial for developing responsible AI solutions for healthcare, addressing multifaceted ethical considerations, including data privacy protection, algorithmic bias, and model accountability . Given the observed AI superiority , future research should prioritize developing clear guidelines for the responsible deployment of highly performing MLMs and project work on dynamic regulatory sandboxes for iterative testing and validation in real-world settings.
Successful real-world implementation and clinical integration of MLMs depend on user-friendly interfaces and interoperability with existing hospital information systems and electronic health records (EHRs) . Key strategies to bridge the gap between academic research and clinical implementation include interdisciplinary collaboration, real-world validation through multicenter studies, and user-centric design that redefines clinician roles towards more interactive, patient-focused duties . Future research should focus on practical implementation strategies, developing adaptive learning systems that integrate feedback from clinical use to continuously improve performance and usability, and advancing digital medical infrastructure for seamless integration .
Finally, establishing unified metrics and benchmarks is essential for evaluating multimodal AI models in medical imaging, ensuring rigorous and consistent assessment of model performance and clinical utility . The development of comprehensive evaluation frameworks, including preference-based comparisons, is a significant step towards standardized benchmarking . Research gaps exist in the widespread adoption of standardized evaluation frameworks, necessitating future work on creating collaborative platforms for benchmark development and validation, and incorporating physician perspectives to lead to more robust and comparable standards of evaluation for multimodal AI in medical imaging . The lack of consistent taxonomy and evaluation methodologies across the field continues to hinder the generalization of conclusions and the comparison of different multimodal papers against baseline unimodal models .
6.1 Advancements in Model Architectures and Learning Paradigms
Future advancements in Multimodal Large Models (MLMs) for personalized medical image diagnosis necessitate innovations in model architectures and learning paradigms. The Transformer architecture, foundational to Large Language Models (LLMs), has shown increasing prominence in medical imaging due to its ability to capture global dependencies and process multimodal data effectively . However, continuous research is vital to overcome current architectural limitations.
A promising research avenue involves developing more parameter-efficient models. For instance, a parameter-efficient fine-tuning framework has been proposed and validated, demonstrating an advancement in adapting Multimodal Large Language Models (MLLMs) for medical imaging . Further exploration into alternative parameter-efficient techniques or foundation models specifically designed for various medical modalities is warranted. Additionally, addressing the inherent interpretability of MMLM architectures is crucial for their clinical adoption . This aligns with the broader emphasis on explainable AI (XAI) methods to understand model decisions and identify potential biases .
The development of novel multimodal architectures and learning paradigms is also critical. General-purpose multimodal architectures may prove more effective for complex medical diagnoses compared to specialized vision models, suggesting a need to investigate the specific architectural components and training strategies that contribute to this advantage . Techniques from other fields, such as Graph Neural Networks (GNNs), are identified as cutting-edge methodologies for multimodal AI, advocating for a focus on these emerging architectures .
Furthermore, the trend towards self-supervised learning and foundation models, already evident in unimodal AI, presents a significant direction for multimodal AI in medical imaging . Models like MedSAM and UniverSeg exemplify LLM-inspired advancements in medical image segmentation, highlighting the potential for developing adaptable and generalizable models . The success of the Segment Anything Model (SAM) implies the concept of foundation models tailored specifically for medical data, and future work can leverage their effectiveness through fine-tuning for specific tasks . The development of models that achieve task generalization without additional training, such as UniverSeg, also indicates progress in learning paradigms .
While current research has explored integrating LLMs with radiomics, future work could investigate different LLM architectures, more sophisticated prompt engineering techniques, and alternative fusion strategies to enhance feature representation and diagnostic capabilities . The concept of "extensible learning" is also a promising direction for improving model adaptability . Unlike simpler models like VGG19 that are suitable for limited datasets, deeper networks offer improved performance with more data, suggesting a continued need for architectural innovation that scales effectively with increasing data volumes .
6.2 Addressing Data and Annotation Challenges
A persistent challenge in developing robust multimodal large models for personalized medical image diagnosis is the scarcity of high-quality, comprehensive datasets, which are often small, proprietary, and costly to acquire and annotate . This reliance on limited curated datasets risks developing AI tools biased towards specific locations, periods, and patient populations, hindering generalizability and equitable AI deployment . To mitigate these issues, future efforts must focus on strategies that overcome data-related hurdles, including the improvement of data diversity and the implementation of efficient annotation tools.
Addressing data scarcity and quality requires a multi-faceted approach. One critical direction involves initiatives to improve diversity and representativeness in datasets, potentially on a global scale, to compile larger and more inclusive data repositories from diverse demographic groups and geographic regions . This necessitates an industry-wide shift in how medical data is collected and stored, moving towards AI-friendly formats and aligning data formats with those logged by physicians to curate comprehensive training databases . Furthermore, systems must be dynamic, constantly updated with new data, and capable of adapting over time through fine-tuning to ensure equitable, bias-free AI .
While specific solutions like synthetic data generation or federated learning are not extensively detailed in all reviewed digests, the broader need for robust digital medical infrastructure and enterprise-level medical imaging services is emphasized. Such infrastructure can bridge the gap between disparate medical imaging modalities, facilitate data storage, operation, and sharing, and ultimately aid in acquiring high-quality datasets . Federated learning, though not explicitly mentioned as a solution in the provided digests, offers a promising strategy to overcome data silos and privacy concerns. By leveraging distributed datasets from multiple institutions without direct data sharing, federated learning enables the development of more generalizable and robust multimodal models.
Data augmentation is a commonly employed technique to address data challenges, with methods such as the N-CLAHE pre-processing pipeline improving image quality and reducing sampling bias, as demonstrated in COVID-19 detection studies . Future research could also explore advanced augmentation techniques or methods for efficient data curation . Parameter-efficient fine-tuning (PEFT) can also indirectly mitigate data limitations by enabling models to adapt to smaller, domain-specific datasets .
Beyond data quantity and diversity, efficient annotation methods are crucial. The laborious and expensive nature of manual annotation for large datasets highlights the urgent need for automation . Future research should investigate more automated or efficient annotation methods to address ongoing data quality and annotation challenges. For instance, Large Language Models (LLMs) could potentially assist in the data annotation process for medical images or directly contribute to feature extraction from raw image data in a more end-to-end fashion, thereby mitigating data and annotation challenges . Furthermore, pre-training and fine-tuning strategies of LLMs are suggested to reduce data annotation costs and improve performance with limited data . Projecting forward, the development of AI-assisted annotation platforms that integrate active learning and expert feedback loops will be essential to improve both annotation efficiency and quality. Such platforms could significantly reduce the burden of manual annotation, accelerate data curation, and ensure the continuous improvement of dataset quality for multimodal medical AI.
6.3 Enhancing Interpretability and Trust
A critical future research priority for Multimodal Large Models (MLMs) in personalized medical image diagnosis is the development of more transparent and trustworthy AI models, ensuring that clinicians can fully comprehend and rely on their outputs. The inherent "black box" nature of many deep learning models, including LLMs, presents a significant challenge to their adoption in clinical settings . To address this, specific research efforts must focus on enhancing the interpretability of MLMs.
Future work should prioritize developing and evaluating methods that explain the diagnostic reasoning of MLMs in medical imaging. Techniques such as attention mechanism visualization and the generation of natural language explanations are crucial for increasing clinician trust . For instance, making the decision-making processes transparent and interpretable is paramount for building confidence in these models . Moreover, in the context of radiomics enhancement, future research should aim to make the LLM's contribution more interpretable, enabling clinicians to understand how specific features are augmented and why particular predictions are made, thereby fostering trust and facilitating clinical adoption . Companies are already engaged in developing tools to improve the interpretability and transparency of LLMs in medical contexts, recognizing that a clear understanding of model functionality, structure, capabilities, and limitations can significantly boost user trust and simplify debugging processes . Explainable Artificial Intelligence (XAI) is an active research area dedicated to making neural networks more transparent and is vital for identifying features that drive decisions and detecting biases or confounders for subsequent mitigation .
Beyond interpretability, future research must rigorously audit MLMs for bias and fairness across diverse demographic groups. Given the high-stakes nature of medical diagnosis, ensuring equitable performance and avoiding discriminatory outcomes is imperative. Additionally, the robustness of these high-performing MLMs must be thoroughly tested against adversarial attacks or distribution shifts commonly encountered in real-world clinical data. This includes adversarial testing as a means to improve interpretability and build trust . While some existing works identify the "black box" nature as a challenge, they do not always detail specific future directions for interpretability in multimodal contexts . This highlights a critical gap where focused research is still needed to achieve robust, fair, and transparent MLMs for personalized medical image diagnosis .
6.4 Ethical Guidelines and Regulatory Frameworks
Establishing comprehensive ethical and regulatory frameworks is paramount to ensuring patient safety and societal benefit as artificial intelligence (AI) rapidly advances in personalized medical image diagnosis. A roadmap for such frameworks must account for the dynamic nature of AI development and deployment. Several studies underscore the critical need for robust regulatory oversight and accountability mechanisms. For instance, the European Union's AI Act and the U.S. Food and Redaction Administration's (FDA) action plans serve as foundational steps towards ensuring AI medical imaging systems adhere to stringent bias and trustworthiness standards, without impeding innovation .
A recurring theme in the literature is the imperative for interdisciplinary collaboration among AI researchers, clinicians, ethicists, and policymakers to develop responsible AI solutions for healthcare. This collaboration is crucial for addressing multifaceted ethical considerations, including data privacy protection, algorithmic bias, and model accountability . Specifically, transparent systems for model responsibility and risk management are essential to safeguard patient rights and ensure that technological applications comply with legal and ethical principles . Recommendations for achieving this include implementing robust data privacy measures, meticulous data selection, and preprocessing to mitigate bias, rigorous model evaluation across diverse demographic groups, and guaranteeing model accountability through interpretable decision-making processes .
Given the observed superiority of AI models in comprehensive evaluations of medical imaging diagnosis , future research must prioritize developing clear guidelines for the responsible deployment of highly performing multimodal large models (MLMs) in healthcare. This involves acknowledging that ethical issues may be use-case specific, necessitating continuous human oversight throughout the lifecycle of AI in radiology . Furthermore, the regulatory landscape will likely categorize LLMs in healthcare as medical devices, thereby emphasizing the need for adaptable regulatory frameworks that can evolve with technological advancements .
Projecting future work, the development of dynamic regulatory sandboxes is essential. These sandboxes would facilitate iterative testing and validation of AI models in real-world settings, allowing for flexible adaptation of regulations as new insights emerge from practical applications. While some papers acknowledge ethical dilemmas and security concerns such as data leakage and biased data , and questions regarding liability for algorithm misdiagnoses and public acceptance , there is a clear gap in providing specific recommendations or future directions for robust ethical guidelines and adaptable regulatory frameworks. This gap highlights the urgent need for dedicated research and policy efforts in this area to ensure the safe, effective, and equitable integration of AI into personalized medical image diagnosis.
6.5 Real-World Implementation and Clinical Integration
The successful deployment and integration of multimodal large models (MLMs) into clinical practice necessitate a systematic approach that addresses technical, operational, and ethical considerations. A foundational step involves the development of user-friendly interfaces and ensuring interoperability with existing hospital information systems and electronic health records (EHRs) . While some research acknowledges the promising potential of Large Language Models (LLMs) in clinical settings and their implications for clinical practice, explicit strategies for seamless integration into existing workflows or healthcare systems are often underexplored . For instance, papers such as do not delve into real-world implementation or integration challenges, instead focusing on performance benchmarks or other aspects of AI development.
Bridging the gap between academic research and clinical implementation requires several key strategies. Interdisciplinary collaboration is paramount, involving not only AI developers but also clinicians, medical informaticians, and regulatory experts. This collaboration is crucial for defining data formats, metadata, and protocols necessary for seamlessly merging information from diverse sources . Real-world validation is equally critical, necessitating multicenter studies to translate research findings into general clinical practices . Many studies, while showcasing potential, acknowledge the need for future work to validate findings in larger, more diverse clinical datasets and to address regulatory requirements for AI-based diagnostic tools . User-centric design is also essential, ensuring that AI tools are understood and effectively integrated into existing workflows, potentially redefining radiologist duties towards more interactive, patient-focused roles .
Future research should prioritize practical implementation strategies, focusing on the development of user interfaces tailored for clinicians and seamless integration into existing hospital information systems. This requires overcoming challenges related to hardware infrastructure, real-time performance, and interpretability . Furthermore, advancing digital medical infrastructure and enterprise-level imaging services are crucial for practical application . Projecting forward, a significant area for future research is the development of adaptive learning systems that can integrate feedback from clinical use to continuously improve performance and usability. This includes continuous monitoring of models in real-world clinical settings to address biases that may arise over time and conducting independent audits by experts or organizations to ensure the integrity of AI medical imaging systems, all while adhering to ethical guidelines and standards .
6.6 Benchmarking and Standardized Evaluation Frameworks
The rigorous evaluation of multimodal AI models, particularly in medical imaging, necessitates the establishment of unified metrics and standardized evaluation frameworks. This is crucial for ensuring consistent assessment of model performance and clinical utility . While some studies provide performance comparisons on specific datasets using common metrics like precision, recall, and F1 , many current evaluations lack the standardization needed for reliable generalization across different research efforts .
A significant step towards addressing this gap is the development of comprehensive evaluation frameworks that span various aspects, from data augmentation strategies to preference-based comparisons . For instance, a novel evaluation framework that incorporates preference-based assessment has been proposed and utilized, contributing to the development of standardized evaluation methodologies for multimodal AI models in medical settings . This approach is particularly valuable for assessing the reliability and fairness of models. Furthermore, new evaluation metrics for tasks like Medical Report Generation (MRG) are being proposed, aiming to develop more robust and semantically relevant benchmarks for generative models in medical imaging, especially where traditional lexical metrics may be insufficient .
Despite the acknowledged importance of rigorous evaluation for model performance and effectiveness , a pervasive research gap exists in the widespread adoption of standardized evaluation frameworks. Many existing works, while evaluating LLMs on various tasks or providing performance metrics, do not explicitly emphasize or contribute to the development of such overarching frameworks for multimodal AI models in clinical settings . This leads to a lack of consistent taxonomy, evaluation metrics, and methodology across the field, hindering the generalization of conclusions and the comparison of different multimodal papers against baseline unimodal models . The challenge of limited diversity in benchmark datasets and difficulties in data sharing further underscore the need for better benchmarks and evaluation frameworks .
Future research should focus on expanding preference-based evaluation frameworks to encompass a wider range of modalities and seamlessly integrating them into clinical workflows. There is also a critical need for creating collaborative platforms for benchmark development and validation, which would facilitate shared resources, methodologies, and best practices. This collaborative approach, combined with the advocacy for incorporating physician perspectives, demonstrating clear clinical utility, and thoroughly evaluating baseline models with appropriate statistics, will lead to a more robust and comparable standard of evaluation for multimodal AI in medical imaging .
7. Conclusion
Multimodal Large Models (MLMs) represent a significant paradigm shift in personalized medical image diagnosis, presenting a dual nature as both a powerful tool and a source of considerable challenges. The survey highlights that deep learning, particularly Convolutional Neural Networks (CNNs), has already transformed medical imaging by enhancing accuracy, speed, and consistency in disease detection, demonstrating comparable or superior performance to radiologists in specific narrow detection tasks . This transformation extends to personalized medicine, where deep learning facilitates the analysis of complex biological data for tailored diagnostic and treatment strategies .
The advent of Large Language Models (LLMs), especially those leveraging the Transformer architecture, has further propelled advancements in medical image processing. LLMs enhance transfer learning efficiency, integrate multimodal data, improve clinical interactivity, and optimize cost-efficiency in healthcare . They offer promising applications such as streamlining interpretation, aiding diagnosis, and personalizing treatment, ultimately reshaping the healthcare landscape . For instance, fine-tuned MLLMs have demonstrated significant outperformance over general multimodal models in specific medical imaging tasks like Med-VQA and MRG, underscoring the effectiveness of parameter-efficient fine-tuning . Furthermore, integrating LLM-processed textual information with radiomic features from mammography has shown improved classification of benign and malignant breast tumors, highlighting the diagnostic accuracy benefits of a multimodal approach . General-purpose multimodal large models can even exhibit superior diagnostic performance compared to specialized vision models and human experts in complex tasks like abdominal CT scans .
Despite these profound opportunities, significant challenges persist. The "black box" nature of many AI algorithms and limitations in data (cost, scale, annotation) remain prominent concerns, although these are considered surmountable . More critically, the sensitivity of AI in medical imaging to biases is a crucial hurdle for real-world integration, necessitating prioritization of bias addressing throughout the AI lifecycle . Challenges also include inconsistent taxonomy of "multimodal" AI, data scarcity, and quality issues, coupled with the need for more generalizable foundational models . Technical challenges related to model interpretability, hardware infrastructure, and real-time performance also need to be addressed for widespread adoption . Ethical considerations, including the potential for "hallucinations" and the stochastic nature of LLMs, necessitate robust regulations, ethical guidelines, and ensuring patient privacy and data security . Caution is also urged in developing clinical diagnostic models with current data, especially for novel diseases, given the significant consequences of misdiagnosis .
Looking forward, MLMs are poised to revolutionize patient care and enhance radiologists' capabilities. The future of precision medicine in radiology and beyond will be characterized by the pervasive integration of AI, leading to more efficient diagnosis and better patient care . This integration is expected to shift radiologist duties towards a more interactive and patient-focused paradigm, with radiologists who utilize AI likely superseding those who do not . To fully realize this potential, future research must focus on optimizing model performance, improving data quality and curation practices, enhancing interpretability, and developing robust ethical frameworks . This will require a multidisciplinary approach, continuous education for physicians and AI developers, and a concerted effort to align data formats for AI training with physician logging practices to curate comprehensive, bias-mitigated databases . The transformative potential of MLMs in medical imaging diagnosis is undeniable, promising a future of increasingly personalized, accurate, and efficient healthcare.
References
The role of large language models in medical image processing: a narrative review - PubMed https://pubmed.ncbi.nlm.nih.gov/38223123/
Artificial Intelligence in Diagnostic Imaging—Challenges and Opportunities https://arrsinpractice.org/artificial-intelligence-diagnostic-imaging-radiology/
Large language models in radiology: fundamentals, applications, ethical considerations, risks, and future directions https://dirjournal.org/articles/large-language-models-in-radiology-fundamentals-applications-ethical-considerations-risks-and-future-directions/dir.2023.232417
The role of large language models in medical image processing: a narrative review - PMC https://pmc.ncbi.nlm.nih.gov/articles/PMC10784029/
The future of multimodal artificial intelligence models for integrating imaging and clinical metadata: a narrative review - Diagnostic and Interventional Radiology https://dirjournal.org/articles/the-future-of-multimodal-artificial-intelligence-models-for-integrating-imaging-and-clinical-metadata-a-narrative-review/dir.2024.242631
Bias in artificial intelligence for medical imaging: fundamentals, detection, avoidance, mitigation, challenges, ethics, and prospects - Diagnostic and Interventional Radiology https://dirjournal.org/articles/bias-in-artificial-intelligence-for-medical-imaging-fundamentals-detection-avoidance-mitigation-challenges-ethics-and-prospects/dir.2024.242854
Redefining Radiology: A Review of Artificial Intelligence Integration in Medical Imaging https://pubmed.ncbi.nlm.nih.gov/37685300/
Deep learning opens new horizons in personalized medicine - PMC https://pmc.ncbi.nlm.nih.gov/articles/PMC6439426/
COVID-19 Detection Through Transfer Learning Using Multimodal Imaging Data - PMC https://pmc.ncbi.nlm.nih.gov/articles/PMC8668160/
AI in Healthcare: Transforming Diagnosis with Deep Learning in Medical Imaging https://journals.bilpubgroup.com/index.php/rwas/article/view/9774
Enhancing radiomics features via a large language model for classifying benign and malignant breast tumors in mammography - PubMed https://pubmed.ncbi.nlm.nih.gov/40203779/
[2401.02797] PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging - arXiv https://arxiv.org/abs/2401.02797
Comprehensive Evaluation of Multimodal AI Models in Medical Imaging Diagnosis: From Data Augmentation to Preference-Based Comparison - arXiv https://arxiv.org/html/2412.05536v1
Large language models in methodological quality evaluation of radiomics research based on METRICS: ChatGPT vs NotebookLM vs radiologist - PubMed https://pubmed.ncbi.nlm.nih.gov/39938163/