0. Reinforcement Learning-Based Navigation Algorithms for Unmanned Surface Vehicle Swarms: A Review
1. Introduction
Unmanned Surface Vehicle (USV) swarm technology represents a significant advancement in autonomous marine operations, offering enhanced capabilities beyond those of single USVs for tasks such as environmental monitoring, search and rescue, surveillance, and vessel protection . The inherent complexity of dynamic marine environments and the challenges associated with coordinating multiple autonomous agents necessitate sophisticated navigation solutions. Reinforcement Learning (RL), particularly Multi-Agent Reinforcement Learning (MARL), has emerged as a promising paradigm to address these challenges, including decentralized decision-making, coordination, communication constraints, and environmental uncertainties . RL-based navigation fills a critical niche by enabling USV swarms to develop adaptive and robust strategies for path planning, collision avoidance, and coordinated task completion, even in the absence of explicit programming for every possible scenario .
Despite the growing body of research on RL for USV swarms, a primary research gap exists in consolidating and critically analyzing the specific applications, methodologies, and limitations of RL-based navigation within this domain. Previous surveys may have broadly touched upon USV navigation or RL applications, but they often lack a focused, comprehensive review specifically on the integration of RL for autonomous navigation in USV swarms, emphasizing the nuanced challenges and solutions in a multi-agent context. For instance, while some papers discuss general DRL applications in path planning, they may not delve into the specific intricacies of swarm coordination or the role of human feedback . This review differentiates itself by providing a dedicated and detailed examination of RL-based navigation algorithms for USV swarms, moving beyond mere technological descriptions to offer an in-depth analysis of methodologies, performance, and emergent properties.
The unique contribution of this review lies in its structured synthesis of diverse RL approaches applied to USV swarm navigation, particularly focusing on the challenges of decentralized control, inter-agent communication, and adaptability to dynamic environments. We critically assess methods like Multi-Agent Deep Deterministic Policy Gradient (MA-DDPG) for real-time target tracking and coordination, and Reinforcement Learning with Human Feedback (RLHF) for aligning swarm behavior with user preferences, which addresses the difficulty of encoding expert intuition into traditional reward functions . Furthermore, we explore the complexities of collision avoidance mechanisms, which are crucial for safe and efficient swarm operation .

The scope of this survey encompasses various RL algorithms adapted for multi-agent systems, their application in specific navigation tasks (e.g., path planning, collision avoidance, target tracking), and the underlying mechanisms for achieving coordination and communication within USV swarms. Our objectives are to: (1) provide a systematic categorization of RL-based navigation approaches; (2) analyze the strengths and weaknesses of current methodologies; (3) identify key challenges and limitations, such as the scalability of MARL for large swarms, the sim-to-real gap, and the computational demands of training complex models; and (4) propose future research directions. Special attention is given to the future trajectory of RL in USV swarms, including potential advancements in adaptive learning, explainable AI, and robust performance in extreme conditions. Crucially, this review also initiates a discussion on the ethical implications and societal impacts of widespread USV swarm deployment, acknowledging the need for responsible development and deployment of such autonomous technologies, an aspect often less explicitly discussed in technical papers .
2. Background on Unmanned Surface Vehicles (USVs) and Swarm Intelligence
Unmanned Surface Vehicles (USVs) have emerged as highly capable autonomous marine platforms, adept at observing their surroundings and executing goal-oriented missions . Their evolution has led to a wide range of applications, including environmental surveying, maritime security, and logistics . The transition from single-agent USV systems to swarm deployments marks a significant advancement, offering numerous advantages. USV swarms can complete missions more rapidly and effectively than individual USVs , achieve increased operational coverage, enhance robustness against single-point failures, and facilitate parallel task execution . This collective capability makes them highly versatile for complex maritime operations such as search and rescue, surveillance, and vessel protection .
However, the deployment of USV swarms introduces significant complexities that necessitate advanced control paradigms. Key challenges include navigation, collision avoidance, and coordinated control within a dynamic and often unpredictable marine environment . Foundational control challenges, such as communication limitations, computational complexity, and sensor noise, are inherent to USV swarm operations . These challenges are exacerbated by environmental variability, demanding robust and adaptive control strategies.
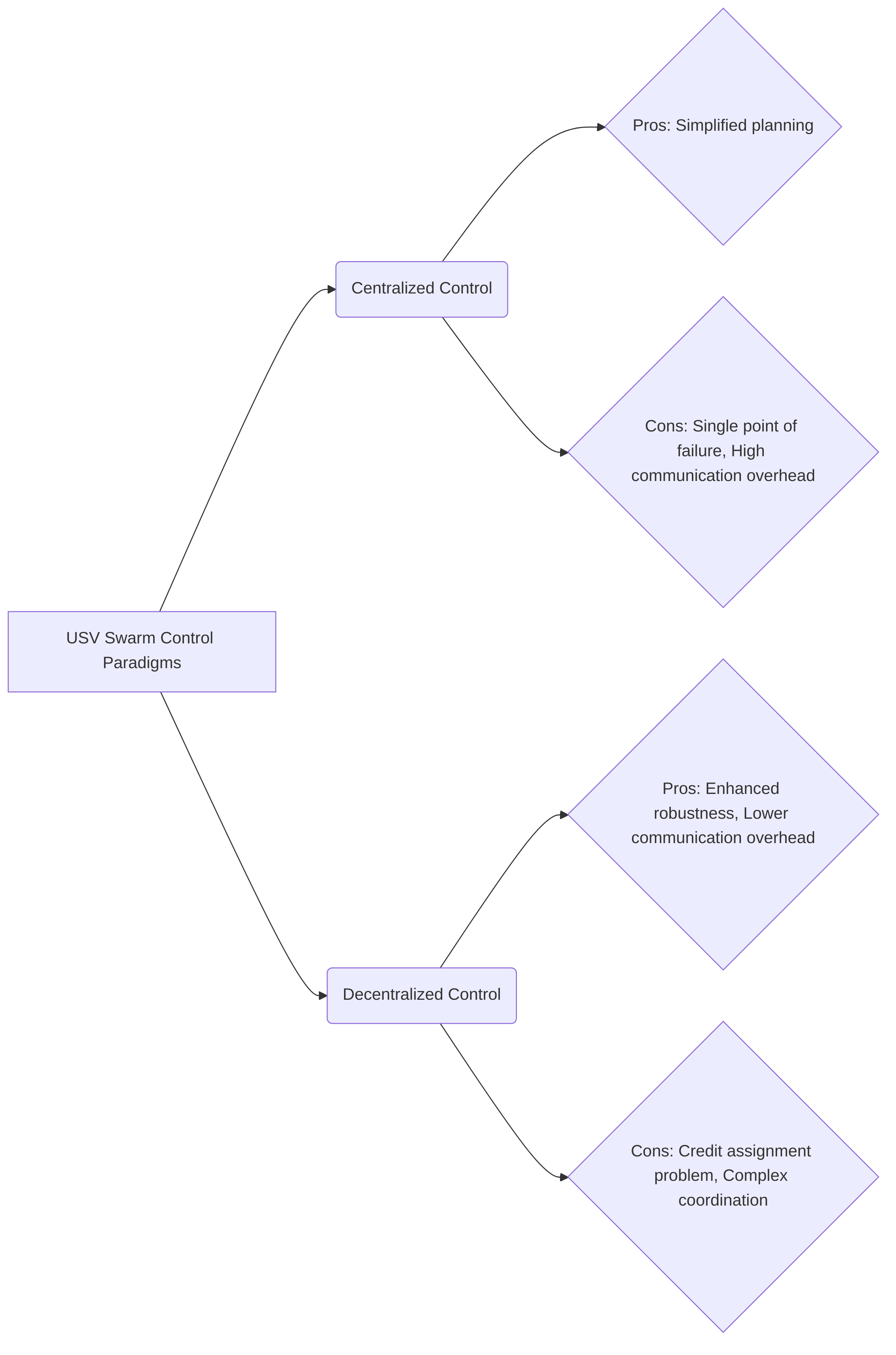
Different swarm paradigms, notably centralized versus decentralized control, offer varying suitability for USV operations. In a centralized control paradigm, a single entity coordinates all agents, simplifying overall planning but introducing a single point of failure and high communication overhead. Conversely, decentralized control distributes decision-making among individual agents, enhancing robustness to communication loss and single-node failures . However, decentralized approaches, particularly when integrated with Multi-Agent Reinforcement Learning (MARL), can amplify the credit assignment problem, making it challenging to attribute collective rewards to individual agent actions, as highlighted by the need for post-deployment refinement in MARL-based USV swarm systems .
Reinforcement Learning (RL) and Deep Reinforcement Learning (DRL) are increasingly explored to mitigate these control challenges, especially in path planning and collision avoidance for USV swarms . RL's adaptive learning capabilities make it well-suited for dynamic environments and complex coordination tasks. However, the application of RL can also exacerbate certain issues. For instance, the computational intensity of training complex MARL policies can be prohibitive, especially for large swarms or in real-time deployment scenarios. Furthermore, the reliance on accurate environmental observations for learning, as noted in the USV's ability to "observe their surroundings and taking actions toward a goal" , means sensor noise can significantly degrade performance, requiring robust state estimation techniques.
The foundational control challenges vary significantly across different swarm mission types. For instance, search and rescue missions prioritize rapid deployment and robust communication, whereas environmental surveying might demand precise path following and data collection, often with less emphasis on high-speed maneuvers. Maritime security operations, on the other hand, require highly reliable collision avoidance and coordinated surveillance, often in adversarial environments. The choice of control paradigm and the specific RL application must therefore be tailored to the mission's unique requirements and inherent complexities.
While the primary focus of current research is on the technical aspects of USV swarm control, the ethical and societal implications of these advanced technologies warrant early consideration. The increased autonomy and potential for complex decision-making in USV swarms raise questions regarding accountability in the event of accidents or unintended consequences. For example, the "disconnect between developer assumptions and end-user requirements" in MARL policies highlights the need for human oversight and interpretability, especially in critical applications. Furthermore, the dual-use nature of USV swarm technology, applicable in both civilian and military contexts, necessitates careful consideration of its potential misuse. These ethical considerations, while briefly introduced here, will be explored in greater depth in Section 6.1, which will delve into future research directions and societal impact.
3. Fundamentals of Reinforcement Learning for Navigation
Reinforcement Learning (RL) provides a powerful framework for agents to learn optimal behaviors through interactions with an environment, modeled fundamentally as a Markov Decision Process (MDP) . In the context of navigation, this involves an agent (e.g., a USV) observing its state (e.g., position, velocity, obstacle proximity), performing an action (e.g., changing heading or speed), and receiving a reward signal that guides it towards desired outcomes like collision avoidance or target tracking . Deep Reinforcement Learning (DRL) extends RL by employing deep neural networks to approximate value functions or policies, enabling handling of complex, high-dimensional state and action spaces inherent in realistic navigation scenarios .
While many foundational RL algorithms like Q-learning, SARSA, DQN, PPO, and Actor-Critic methods are not explicitly detailed in the provided digests , their application in USV navigation implicitly relies on these core principles. For instance, the use of a deep neural network for policy approximation in collision avoidance implies a DRL approach, where the network learns to map observed states to optimal actions .

The transition from single-agent RL to Multi-Agent Reinforcement Learning (MARL) is necessitated by the dynamics of Unmanned Surface Vehicle (USV) swarms. In a swarm, multiple USVs interact with each other and the environment, leading to a complex, dynamic system where individual decisions impact collective behavior and overall mission success . MARL allows for the decentralized control of agents, where each USV makes decisions based on its own observations and objectives, fostering superior performance and stability in collective tasks like real-time target tracking or cooperative search . Agent interactions in USV swarms involve aspects such as collision avoidance, formation keeping, and collaborative target tracking, often relying on collective readings and shared reward mechanisms to facilitate coordination .
The suitability of MARL algorithms for the dynamic and uncertain nature of marine environments is a critical consideration. Marine environments present challenges such as partial observability (due to limited sensor range or occlusions), delayed rewards (e.g., for long-term navigation goals), and sensor drift (leading to noisy or inaccurate observations). While the digests do not explicitly detail how each fundamental RL algorithm's mathematical formulation addresses these specific marine uncertainties, the selection of algorithms often reflects these needs. For example, policy-based methods like Proximal Policy Optimization (PPO) or Actor-Critic approaches, due to their direct optimization of policy, can be more robust to noisy observations or partial observability compared to value-based methods like Q-learning or DQN that rely on accurate value function estimation.
The Multi-Agent Deep Deterministic Policy Gradient (MA-DDPG) approach, an extension of DDPG, is specifically proposed for coordinating multiple USVs in real-time target tracking, emphasizing decentralized control and decision-making based on individual observations and objectives . This decentralized approach can intrinsically handle partial observability by allowing agents to operate with their limited local information. Furthermore, while the mathematical formulations of how non-stationarity and credit assignment are addressed are not extensively presented in the provided literature , the very nature of MARL research in USV swarms is geared towards resolving these issues. Non-stationarity arises because each agent's optimal policy changes as other agents learn and adapt, while credit assignment involves determining how individual agent actions contribute to the collective reward. Techniques such as centralized training with decentralized execution (CTDE) or novel reward shaping mechanisms (as implicitly addressed in preference-based policy fine-tuning ) are often employed to mitigate these challenges. The discussion in Chapter 4 will further elaborate on specific algorithms and methodologies that explicitly tackle these MARL challenges, building upon the foundational concepts presented here and using evidence from the cited papers to illustrate their effectiveness.
4. Reinforcement Learning-Based Navigation Algorithms for USV Swarms
This chapter provides a comprehensive overview of Reinforcement Learning (RL) and Deep Reinforcement Learning (DRL) algorithms specifically developed for the autonomous navigation of Unmanned Surface Vehicle (USV) swarms. The discussion categorizes these algorithms based on their primary functionalities: path planning, collision avoidance, and swarm coordination, while also exploring the integration of human preferences for policy refinement. Each category delves into prominent approaches, their technical underpinnings, the specific challenges they address, and a critical analysis of their performance, suitability for varying swarm sizes, and robustness under diverse environmental conditions.
The development of RL-based navigation strategies for USV swarms is underpinned by a theoretical framework that considers both algorithmic innovation and methodologies for enhancing performance and aligning with desired behaviors. Path planning strategies, as highlighted by , primarily leverage DRL to optimize objectives such as shortest path, energy efficiency, and coverage. These methods are designed to overcome challenges like local optima and facilitate real-time replanning in dynamic marine environments. In contrast, other research, such as that focusing on human implicit preference-based policy fine-tuning or general swarm control , does not explicitly detail path generation mechanisms, but rather assumes an underlying path or objective.
Collision avoidance mechanisms, integral to USV swarm safety, predominantly employ DRL algorithms. These methods rely on precise state representations, encompassing individual and relative kinematic information, and meticulously designed reward functions that heavily penalize collisions while incentivizing safe navigation . A significant trade-off exists between maximizing safety and maintaining mission efficiency; overly conservative strategies can lead to increased path lengths and computational costs. While some studies acknowledge collision avoidance as a crucial evaluation criterion , the challenge lies in balancing safety with the need for efficient and agile swarm operations. This limitation in balancing safety and efficiency contributes to the broader challenge of real-time adaptability under dynamic environmental conditions.
Swarm coordination and control approaches, facilitated by RL, enable cooperative behaviors, task allocation, and dynamic formation maintenance . The choice between decentralized and centralized control architectures is critical, influencing communication overhead, robustness, and scalability. Decentralized approaches, such as those used for target tracking and collision avoidance, offer enhanced performance and stability by minimizing communication overhead and improving robustness against single-point failures . However, they may not explicitly address complex task allocation or dynamic formation maintenance, and rely on implicit communication mechanisms. In contrast, centralized systems, while potentially offering global optimization, face scalability issues. The integration of human preferences, particularly through agent-level feedback, has shown promise in addressing credit-assignment problems in Multi-Agent Reinforcement Learning (MARL), enhancing cooperative behaviors and task allocation by aligning learned policies with human intent .
The integration of human preferences into RL frameworks is crucial for policy refinement. The Agent-Level Feedback system categorizes feedback into intra-agent, inter-agent, and inter-team types, allowing for precise policy refinement and better credit assignment. This system, validated by a Large Language Model (LLM) evaluator, uses a reward model trained with a Bradley-Terry model to capture pairwise agent preferences, addressing the credit-assignment challenge and promoting fairness and performance consistency . The fine-tuning process integrates this learned reward model with the original reward function through a weighted sum, optimized using Independent Proximal Policy Optimization (IPPO), as formalized by: J(\theta) = E\_\pi \left This equation highlights the trade-off between maximizing task performance and satisfying human preferences. An excessive emphasis on human preferences (high ) can inadvertently degrade core task performance, underscoring the need for careful balancing during implementation. This specific trade-off is a critical challenge in bridging the gap between theoretical optimality and practical deployability, aligning with the broader challenges of human-robot interaction and interpretability.
A comparative analysis of these RL navigation algorithms reveals a landscape where performance, theoretical underpinnings, and practical implementations vary significantly. While a comprehensive review discusses the strengths and weaknesses of various DRL methods for path planning and collision avoidance, explicitly identifying their suitability across different swarm sizes and environmental conditions , direct quantitative comparisons between diverse RL navigation paradigms are often lacking in individual papers. For example, the MA-DDPG approach for coordination focuses on its efficacy in isolation , similar to dedicated collision avoidance methods .

The suitability of an algorithm depends on the task's complexity, environmental dynamics, swarm size, available computational resources, and human interaction requirements. Algorithms like MA-DDPG are better suited for complex cooperative tasks, while simpler DRL approaches may suffice for basic navigation with obstacle avoidance . Algorithms must also demonstrate robustness to environmental disturbances (e.g., currents, waves) and perform effectively under varying communication quality (e.g., intermittent connectivity), which poses a significant challenge related to communication constraints. The trade-off between sample efficiency and policy performance is crucial: policy-based methods are suitable for continuous control but may be sample inefficient, while value-based methods struggle with scalability. The integration of human preferences can enhance practical viability but necessitates careful balancing to prevent performance degradation. The identified limitations, such as poor performance under intermittent communication, directly contribute to the broader challenges discussed in Chapter 6, particularly "Communication Constraints." This underscores the need for future research to conduct more explicit and standardized comparative studies to establish clearer benchmarks for practical deployment.
4.1 Path Planning Strategies
Path planning for Unmanned Surface Vehicle (USV) swarms is a critical aspect of autonomous navigation, with Deep Reinforcement Learning (DRL) emerging as a prominent methodology to address the inherent complexities of dynamic marine environments. A comprehensive review by elucidates various DRL approaches tailored for USV swarm path planning, aiming for diverse objectives such as achieving the shortest path, optimizing energy efficiency, and ensuring comprehensive coverage. This review highlights how specific DRL architectures and their corresponding reward designs are employed for both individual USV pathfinding and the broader optimization of global swarm trajectories. These methodologies present various algorithms and their applications in intricate navigation scenarios, demonstrating adaptability to dynamic environments and contributing to overcoming challenges such as local optima and real-time replanning .
In contrast, other research efforts, while related to USV swarm control, do not explicitly focus on detailed path planning strategies or the generation of paths. For instance, a study on human implicit preference-based policy fine-tuning for multi-agent reinforcement learning in USV swarms does not delve into the specifics of how RL is utilized for path generation, nor does it discuss particular RL architectures or reward designs for pathfinding or global trajectory optimization . Similarly, research on the control and coordination of USV swarms using DRL in ROS primarily concentrates on task completion, localization, and tracking. While coordination is a stated objective, the paper lacks specific details on how RL facilitates path generation, nor does it address objectives such as shortest path or energy efficiency, or global swarm trajectory optimization . Furthermore, a patent application concerning a DRL-based intelligent collision avoidance method for USV swarms prioritizes collision avoidance, assuming that a general path or objective is already established rather than focusing on the initial path planning itself .
Therefore, while the field of USV swarm navigation is broad, the current body of literature demonstrates a clear distinction between dedicated path planning research and other aspects of swarm control. The DRL-centric approaches for path planning, as detailed by , offer promising avenues for addressing the efficiency, optimality, and adaptability required for complex and dynamic maritime operations.
4.2 Collision Avoidance Mechanisms
Collision avoidance is a critical aspect of ensuring the safe and reliable operation of Unmanned Surface Vehicle (USV) swarms, particularly given the dynamic and often unpredictable nature of maritime environments. Deep Reinforcement Learning (DRL) algorithms have emerged as a prominent approach for addressing this challenge, offering adaptive and intelligent solutions for preventing collisions among USVs and with static or dynamic obstacles .
A core characteristic of DRL-based collision avoidance methods is their reliance on carefully constructed state representations and reward functions. State representations typically encompass the USV's own kinematic information, such as its position, velocity, and heading, along with the relative kinematic information of neighboring USVs and obstacles . The efficacy of these methods in terms of safety is largely driven by the reward functions, which are designed to heavily penalize collisions and incentivize maintaining safe distances and successful navigation. For instance, negative rewards are explicitly assigned for collision events, while positive rewards encourage behaviors that lead to collision-free paths or successful task completion . This framework allows USVs to learn decentralized policies for intelligent collision avoidance, enhancing overall swarm safety .
However, the effective integration of collision avoidance mechanisms with higher-level navigation goals presents a critical trade-off between safety and mission efficiency. While DRL approaches prioritize collision prevention through penalizing risky behaviors, the computational cost associated with learning complex collision avoidance policies can be substantial. The constant processing of environmental states, especially in dynamic swarm scenarios with numerous agents, demands significant computational resources. Furthermore, overly conservative collision avoidance strategies, while maximizing safety, may lead to increased path lengths or detours, thereby reducing mission efficiency and maneuverability. This tension highlights the need for a balanced approach where the learned policies can dynamically adjust their aggressiveness based on mission priorities and real-time environmental conditions. For instance, in scenarios requiring rapid deployment or time-sensitive objectives, a slightly less conservative but still safe approach might be preferred. Conversely, in congested or unpredictable waters, a highly cautious avoidance strategy would be paramount.
Some studies acknowledge collision avoidance as a crucial feedback criterion for evaluating USV swarm policies, ensuring that agents prevent risky path crossings . While specific DRL algorithms or detailed state representations for collision avoidance are not always explicitly detailed in these contexts, the very inclusion of collision avoidance as an evaluation metric underscores its fundamental role in overall navigation strategies. This implies that effective collision avoidance mechanisms must be intrinsically linked with the swarm's overarching navigation objectives, ensuring that safe maneuvers do not unduly compromise mission completion. The decentralized nature of many DRL-based collision avoidance methods allows each USV to make independent decisions based on local information, contributing to a robust overall swarm behavior without requiring a centralized control unit, thereby promoting scalability and adaptability in complex environments.
4.3 Swarm Coordination and Control Approaches
Reinforcement Learning (RL) has emerged as a pivotal mechanism for achieving scalable and robust coordination in Unmanned Surface Vehicle (USV) swarms, primarily by enabling agents to learn cooperative behaviors, facilitate task allocation, and maintain dynamic formations . A critical aspect of swarm coordination lies in the choice between decentralized and centralized control architectures, each presenting distinct implications for communication overhead, robustness, and scalability.
Decentralized control architectures, where each USV independently learns and makes decisions based on its local observations, are frequently emphasized for their potential to enhance performance and stability, particularly in real-time target tracking scenarios . This approach minimizes communication overhead as agents do not rely on a central command unit, thus improving robustness against single-point failures. For instance, in decentralized collision avoidance, each USV learns an individual policy to safely navigate within the swarm, contributing to overall coordination without explicit central orchestration . Communication and coordination in such systems are often facilitated through implicit mechanisms like collective readings and shared reward signals, rather than extensive, explicit communication protocols . However, these decentralized systems may not extensively detail specific communication strategies beyond implicit observation of neighbors, nor do they often address broader coordination aspects such as complex task allocation or dynamic formation maintenance . Deep Reinforcement Learning (DRL) frameworks, in particular, enable decentralized decision-making for coordinated actions, thereby enhancing overall swarm performance and robustness through intelligent coordination .
In contrast, centralized control architectures, while potentially offering more precise global optimization and easier policy design for complex tasks, face significant scalability challenges due to increased communication overhead and computational demands as swarm size grows. They are also more susceptible to single-point failures. The trade-off between centralized and decentralized control architectures often comes down to the balance between global optimality and system robustness/scalability. Decentralized systems, by design, often exhibit better fault tolerance and scalability, making them suitable for large swarms operating in dynamic and uncertain environments.
Furthermore, the integration of human preferences significantly impacts the learnability and applicability of Multi-Agent Reinforcement Learning (MARL) policies in complex USV swarm scenarios . Traditional team-level feedback often struggles with credit-assignment problems in MARL. To address this, an "Agent-Level Feedback" system has been proposed, classifying feedback into intra-agent, inter-agent, and intra-team types . This fine-grained feedback allows for more precise policy refinement and better credit assignment, thereby improving cooperative behaviors and task allocation by aligning learned policies with human preferences . For instance, in task allocation, this system can enforce distance-based one-to-one matching between pursuers and evaders as a feedback criterion, directly influencing the swarm's performance and fairness . This approach helps resolve credit-assignment challenges and maintain fairness and performance consistency in multi-agent systems, even though it may not detail specific methods for decentralized decision-making or communication strategies .
4.4 Human Preference Integration for Policy Refinement
Integrating human preferences into Reinforcement Learning (RL) frameworks for Unmanned Surface Vehicle (USV) swarms presents a promising avenue for refining learned policies and enhancing overall system performance. While several studies on USV swarm navigation focus on autonomous methods, the direct incorporation of human feedback, particularly within a Reinforcement Learning from Human Feedback (RLHF) paradigm, is an evolving area .
A notable approach in this domain is the Agent-Level Feedback system designed for Multi-Agent Reinforcement Learning (MARL) policy fine-tuning in USV swarms . This system categorizes feedback into three distinct types to address the complex interactions within a swarm. Intra-agent feedback pertains to individual USV behaviors, such as adhering to operational boundaries. Inter-agent feedback focuses on interactions between individual USVs, including collision avoidance and maintaining desired formations. Finally, inter-team feedback addresses broader coordination aspects, such as task allocation among groups of USVs .
The effectiveness of such a system is validated through the use of a Large Language Model (LLM) evaluator. This LLM-based validation mechanism tests the approach across various feedback scenarios, including region constraints, collision avoidance, and task allocation, ensuring the integrated preferences lead to desirable swarm behaviors . A critical component of this methodology is the reward model, which is trained using a Bradley-Terry model to capture pairwise agent preferences. This model is designed to assign higher rewards to agents exhibiting diligent behavior and lower rewards to those demonstrating less desirable or "lazy" actions. This reward shaping technique directly addresses the credit-assignment challenge inherent in MARL by providing nuanced feedback that reflects human judgment .
The fine-tuning process integrates this learned reward model with the original reward function. This integration is achieved through a weighted sum, where a weight determines the influence of the preference-based reward. The optimization is performed using Independent Proximal Policy Optimization (IPPO), an algorithm well-suited for decentralized MARL settings. The objective function for this fine-tuning process is formally expressed as: J(\theta) = E\_\pi \left Here, represents the original environmental reward, and denotes the learned preference reward from the Bradley-Terry model. This formulation aims to enhance fairness and performance consistency across the swarm by systematically incorporating human insights into the learning process .
While the integration of LLMs for evaluation is demonstrated to be effective for validating the approach, the specifics of how LLMs are employed beyond validation, particularly in generating or interpreting human feedback for direct reward model training, remain an area for further elucidation. The explicit details regarding the mechanisms of reward model training and its integration with original rewards are provided for the specific Agent-Level Feedback system, showcasing a concrete methodology for leveraging human preferences for policy refinement in USV swarms . This highlights a significant step towards enabling USV swarms to learn behaviors that are not only efficient but also aligned with complex human objectives and ethical considerations.
4.5 Comparative Analysis of RL Navigation Algorithms
Building upon the foundational discussions in preceding sections regarding various reinforcement learning (RL) and deep reinforcement learning (DRL) approaches for unmanned surface vehicle (USV) swarm navigation, this section provides a comparative analysis of these algorithms. The goal is to delineate their performance metrics, theoretical underpinnings, and practical implementations, thereby highlighting associated trade-offs and offering insights for algorithm selection in specific USV swarm navigation tasks.
A comprehensive review of DRL navigation algorithms applied to USV swarms underscores their varied applicability and inherent challenges . This review synthesizes the strengths and weaknesses of different DRL methods in addressing core aspects of USV swarm navigation, such as sophisticated path planning and robust collision avoidance. It implicitly evaluates their suitability across diverse swarm sizes and environmental conditions, identifying the specific challenges each algorithm aims to mitigate . For instance, while some algorithms might excel in static environments with predictable obstacles, their performance could degrade significantly in dynamic, uncertain, or high-density swarm scenarios. The fundamental trade-off often lies between an algorithm's computational complexity and its adaptability to real-world complexities.
While specific algorithms like Multi-Agent Deep Deterministic Policy Gradient (MA-DDPG) have been proposed and implemented for USV swarm coordination, the literature often focuses on demonstrating the efficacy of these particular methods rather than providing direct comparative analyses of various RL navigation algorithms . Similarly, dedicated collision avoidance methods based on RL are evaluated for their effectiveness in isolation, without an explicit comparison against alternative RL navigation paradigms . This trend indicates a prevalent focus on problem-specific algorithmic development, making a direct, quantitative comparison across diverse algorithms challenging based solely on individual paper claims.
However, insights into performance and practical implications can be inferred from studies that incorporate human feedback or demonstrate robust policy fine-tuning. For example, methods that incorporate human implicit preference-based policy fine-tuning offer a unique lens through which to evaluate algorithmic adaptability and user satisfaction. Such approaches compare agent-level feedback mechanisms against team-level feedback for reward model learning. Empirical evidence suggests that agent-level feedback consistently outperforms team-level feedback, particularly in complex scenarios demanding precise agent-specific credit assignment. This is supported by higher preference prediction accuracy across criteria such as "Crossing" and "Assignment" . Furthermore, fine-tuning policies based on human preferences has been shown to consistently elevate preference satisfaction while either maintaining or marginally improving task performance. Ablation studies reveal a critical trade-off: an excessive prioritization of human preference (via varying the weight ) can, in fact, detrimentally affect core task performance, highlighting the need for careful balancing in practical implementations. The robustness of these methods against inconsistent feedback further adds to their practical viability .
The theoretical underpinnings vary significantly, ranging from value-based methods (e.g., Q-learning variants) to policy-based methods (e.g., DDPG, PPO), and hybrid actor-critic architectures. Value-based methods often excel in discrete action spaces and convergence guarantees in simpler environments, but struggle with scalability in complex, continuous state-action spaces typical of USV swarm navigation. Policy-based methods, in contrast, directly optimize the policy, making them more suitable for continuous control and large-scale problems, though they can suffer from sample inefficiency and convergence instability. Actor-critic methods combine the strengths of both, offering a balance between stability and efficiency.
In selecting the most suitable algorithm for specific USV swarm navigation tasks, several factors must be considered:
- Complexity of Task: For intricate tasks like cooperative manipulation or formation control, algorithms capable of decentralized learning and coordination, such as MA-DDPG, may be more appropriate . For simpler tasks like point-to-point navigation with obstacle avoidance, less complex DRL approaches might suffice.
- Environmental Dynamics: Highly dynamic and uncertain environments necessitate algorithms with strong generalization capabilities and robustness to noise, potentially favoring policy-based or model-free approaches that can learn directly from interaction rather than relying on an explicit environmental model.
- Swarm Size: Scalability is a significant concern. Algorithms that leverage centralized training with decentralized execution (CTDE) or decentralized learning with communication protocols are crucial for larger swarms to mitigate the curse of dimensionality.
- Computational Resources: The computational burden of training and inference varies greatly. More complex DRL models often demand substantial computational power, which might be a constraint for real-time onboard deployment.
- Human Interaction Requirements: If human oversight or preference integration is critical, algorithms that support fine-tuning with human feedback, such as those employing preference prediction models, become highly relevant . This allows for adaptable mission execution that aligns with operator intent, even if it entails a slight trade-off with peak task performance.
In conclusion, while various RL and DRL algorithms demonstrate promise for USV swarm navigation, a direct comparative landscape remains largely implicit in current literature. The selection of an optimal algorithm hinges on a careful evaluation of the specific task's demands, environmental conditions, available computational resources, and the desired level of human interaction, balancing performance, robustness, and interpretability. Future research should aim for more explicit, standardized comparative studies to provide clearer benchmarks for practical deployment.
5. Simulation Tools and Methodologies for RL in USV Swarm Navigation
Simulation platforms are indispensable tools for training and validating Reinforcement Learning (RL) algorithms tailored for Unmanned Surface Vehicle (USV) swarms, offering a controlled, cost-effective, and safe environment for iterative development and testing. These platforms mitigate the prohibitive expenses and logistical complexities associated with real-world deployments, enabling researchers to explore a vast parameter space and gather extensive data crucial for training robust RL policies. A key advantage of simulations is their capacity to generate diverse training scenarios and annotate data, which is often scarce in real-world marine robotics machine learning research .

While many studies acknowledge the use of simulation environments for testing and validation , specific details regarding their features and capabilities are often limited . For instance, some studies utilize general maritime simulation environments, setting specific parameters like USV speeds, detection ranges, and episode lengths for tasks such as pursuit-evasion games, with randomized agent initialization for varied scenarios . The Robot Operating System (ROS) integrated with Gazebo is another mentioned platform for system implementation . However, comprehensive discussions on their advanced features, such as detailed sensor simulation, physics modeling, thruster dynamics, or integration with specific machine learning frameworks like OpenAI Gym, are frequently absent in the literature .
In contrast, specialized platforms like Stonefish are designed with features directly addressing the complexities of marine robotics, making them particularly advantageous for RL research. Stonefish, an open-source platform, offers advanced sensor simulation, including event-based, thermal, and optical flow cameras, crucial for realistic perception in challenging marine conditions . Its modular architecture allows for advanced thruster modeling and robust hydrodynamics, integrating Bullet Physics with buoyancy and material interaction enhancements to simulate environmental currents and pressures accurately . Furthermore, it provides semi-automatic annotation tools for generating labeled datasets for deep learning and improved communication technologies for testing protocols, alongside compatibility with OpenAI Gym for streamlined RL applications . These capabilities are vital for achieving realistic simulations, which are paramount for transferring learned policies to real-world scenarios.
Common evaluation metrics mentioned in the literature for RL-based USV swarm navigation include success rate and path length . Some studies also employ automated evaluation scripts, potentially leveraging tools like ChatGPT for systematic processing of episode logs and assigning feedback labels based on predefined behavioral criteria, ensuring consistent and reproducible evaluation . A framework for standardized testing should expand upon these metrics, incorporating measures of robustness, adaptability, and resilience against unforeseen environmental variations.
The "sim-to-real" gap represents a fundamental challenge in applying RL algorithms developed in simulation to real-world USV swarm operations. Discrepancies between simulated and real-world physics, sensor noise, environmental dynamics, and inter-agent communication can significantly degrade the performance of learned policies. While many papers acknowledge the use of simulations, explicit discussions on sim-to-real challenges and mitigation strategies like domain randomization and domain adaptation are less common .
However, the features of advanced simulation tools inherently support these strategies. Domain randomization, for instance, involves varying parameters such as USV speeds, detection ranges, and initial positions during training to expose the RL agent to a wide array of conditions, making the learned policy more robust to real-world variations . Simulators with highly customizable physics engines and advanced thruster modeling, like Stonefish, can facilitate this by allowing precise control over physical parameters to mimic diverse real-world scenarios . The ability to simulate various environmental currents and pressures also supports training policies that are less sensitive to specific water conditions .
Domain adaptation techniques, which aim to bridge the gap between source (simulation) and target (real-world) domains, can leverage realistic sensor models and communication simulations provided by platforms such as Stonefish . By simulating noise, occlusions, and other sensor imperfections, and modeling the complexities of acoustic and visual light communication systems, the learned policies can better handle real-world data and communication constraints . This parallels strategies used in other multi-agent robotic systems, where realistic sensor data and dynamic environmental modeling are crucial for effective sim-to-real transfer.
The effectiveness of these strategies in the context of USV swarm dynamics is directly tied to the fidelity of the simulation. Swarm tasks involving precise coordination, collision avoidance in dynamic environments, and long-range navigation are particularly susceptible to sim-to-real gaps if the simulation does not accurately capture hydrodynamics, inter-vehicle interference, and complex wave-current interactions. The absence of detailed discussions on these specific features in many reviewed papers suggests a current gap in adequately addressing these complexities for USV swarm tasks.
To address these challenges, a standardized testing framework should be established. This framework should not only evaluate success rates and path lengths but also focus on evaluating robustness against specific environmental uncertainties that are difficult to perfectly simulate. This includes metrics for performance degradation under varying sea states, current profiles, wind conditions, and communication latencies or packet loss. Such a framework would provide a clearer understanding of the generalization capabilities of RL policies and highlight areas where simulation fidelity needs further improvement. The insights derived from evaluating diverse simulation methodologies are crucial for future advancements in sim-to-real transfer for USV swarm navigation, informing Chapter 6's broader discussion on solutions for bridging these gaps.
6. Challenges and Future Directions
The current landscape of reinforcement learning-based navigation algorithms for Unmanned Surface Vehicle (USV) swarms, while advancing significantly in areas such as path planning and collision avoidance, faces several fundamental challenges that impede their widespread deployment and practical applicability . A critical assessment of the state-of-the-art reveals common deficiencies across existing research, necessitating targeted and interdisciplinary solutions.

A prevalent issue is sample inefficiency, where current Deep Reinforcement Learning (DRL) algorithms demand extensive interactions with the environment to learn effective policies . This issue is exacerbated in complex multi-agent scenarios due to the exponential growth of the state-action space. To mitigate this, future research should explore integrated frameworks that combine curriculum learning with adaptive simulation environments. These environments could dynamically adjust complexity based on agent performance, progressively introducing more challenging scenarios as the swarm's capabilities improve. Additionally, techniques such as meta-learning from successful multi-agent coordination strategies in other domains (e.g., robotics, traffic control) or leveraging transfer learning from simulations of simpler USV coordination tasks to more complex ones could significantly enhance sample efficiency .
The sim-to-real gap represents another significant hurdle. Policies trained in simulated environments often fail to translate effectively to real-world USV swarm operations due to discrepancies in environmental dynamics, sensor noise, and vehicle characteristics . The current fidelity of marine robotics simulations, particularly in environmental dynamics (e.g., weather, currents) and rendering performance, needs substantial enhancement to support robust RL model training . To address this, future research should investigate advanced Bayesian reinforcement learning methods to quantify and reduce uncertainty in learned policies, leading to more robust real-world performance. Furthermore, research into procedural content generation techniques is crucial for creating highly diverse and adversarial simulation environments that specifically target the identified weaknesses of current RL algorithms, such as robustness against sensor noise or abrupt environmental changes. This would enhance the training data variability and better prepare policies for real-world unpredictability.
Scalability to large swarms remains a considerable challenge, with the complexity of multi-agent interactions and the associated computational burden increasing exponentially with swarm size . Future research directions must explore communication-efficient Multi-Agent Reinforcement Learning (MARL) algorithms, such as graph neural networks for learned communication protocols, or hierarchical RL structures that decompose swarm control into manageable sub-problems, drawing inspiration from biological swarm systems or decentralized control theory . Explicitly integrating communication constraints into MARL frameworks is also vital for practical deployment.
The interpretability of learned policies is another limitation . Black-box DRL models make it difficult to understand the reasoning behind a swarm's navigation decisions, hindering debugging, validation, and human trust. Research into explainable MARL (XMARL) is paramount. XMARL systems should not only learn from human feedback but also provide interpretable justifications for their navigation decisions, thereby building trust and facilitating human oversight in critical USV swarm operations . This also includes addressing the inconsistency in large-scale human feedback for reward model reliability, potentially through active learning techniques for selective feedback acquisition .
Furthermore, the robust handling of dynamic and unpredictable environments is crucial for real-world applications . Current approaches often struggle with unforeseen obstacles, changing weather conditions, or adversarial actions. Future research should focus on developing novel MARL frameworks that can effectively integrate and fuse information from diverse sensor modalities (e.g., sonar, lidar, visual cameras, acoustic sensors) for enhanced state representation and decision-making under varying environmental conditions and sensor degradation. This multi-modal sensing approach would improve the swarm's perception and adaptability.
Beyond these technical challenges, the burgeoning field of autonomous USV swarms presents significant ethical and societal challenges that are largely unaddressed in current research. These include accountability in case of accidents, data privacy concerns arising from extensive data collection, and the potential for misuse (e.g., unauthorized surveillance). The development of comprehensive regulatory frameworks is essential to govern operational boundaries, data governance, and liability. Bias mitigation in RL policies is another critical area, ensuring fairness and preventing unintended discriminatory behaviors. Proactive research into these areas, coupled with the integration of emerging technologies like explainable AI and federated learning for distributed and privacy-preserving learning, will be crucial for the responsible and beneficial deployment of USV swarm navigation systems.
6.1 Ethical and Societal Challenges
The current body of research on reinforcement learning-based navigation algorithms for Unmanned Surface Vehicle (USV) swarms predominantly focuses on technical aspects such as path planning and collision avoidance, as evidenced by various studies . However, a critical gap exists in the explicit consideration of ethical and societal challenges associated with the deployment of autonomous USV swarms. None of the reviewed papers directly address issues such as accountability, data privacy, potential misuse, explainability, bias mitigation, or the development of regulatory frameworks .
The proliferation of autonomous USV swarms necessitates proactive research into their ethical implications. A primary concern is accountability: in the event of an accident or unintended consequence, determining liability when decisions are made by an autonomous system can be profoundly complex. Furthermore, the collection and processing of data by USV swarms raise significant data privacy concerns, particularly in sensitive maritime environments or when interacting with human-operated vessels. The potential for misuse, such as employing swarms for unauthorized surveillance or aggressive actions, also presents a substantial societal challenge that requires careful consideration.
To foster trust and enable human oversight, future research must prioritize the development of explainable Multi-Agent Reinforcement Learning (XMARL) systems for USV swarm navigation. XMARL systems should be designed to provide clear justifications for their navigation decisions, offering insights into the reasoning behind a swarm's collective behavior. This interpretability is crucial for establishing accountability by allowing human operators or investigators to understand why a particular action was taken, thereby identifying the root cause of any adverse events. Moreover, transparent decision-making can act as a deterrent against misuse, as the rationale behind potentially harmful actions would be traceable and auditable.
Another critical research direction involves strategies for bias mitigation in RL policies. Biases can inadvertently be introduced into RL models through biased training data or reward functions, leading to unfair or inequitable operational outcomes. For instance, a policy might implicitly favor certain navigation routes or behaviors, potentially neglecting optimal solutions for specific swarm members or mission objectives under diverse environmental conditions. Future research should focus on developing robust techniques for bias detection and correction within RL reward functions and state representations. This would ensure fair and equitable operation of USV swarms, preventing preferential treatment and promoting adaptive performance across varied and dynamic maritime scenarios.
Finally, the increasing autonomy of USV swarms underscores the urgent need for appropriate regulatory frameworks. These frameworks should address aspects such as operational boundaries, data governance, liability assignment, and the ethical guidelines for design and deployment. Establishing clear regulations will be essential for ensuring the safe, responsible, and beneficial integration of autonomous USV swarms into maritime operations, safeguarding societal values while maximizing technological potential.
7. Conclusion
This survey has systematically examined the significant progress achieved in reinforcement learning (RL)-based navigation algorithms for Unmanned Surface Vehicle (USV) swarms, highlighting their transformative potential in complex maritime operations. A primary contribution lies in the demonstrated efficacy of Deep Reinforcement Learning (DRL) and Multi-Agent Reinforcement Learning (MARL) in addressing critical navigation challenges such as collision avoidance, cooperative behavior, and efficient path generation . Specifically, decentralized DRL approaches have proven effective in enabling USVs to intelligently avoid collisions within a swarm, ensuring safer operations . Furthermore, enhanced MARL methods like MA-DDPG have facilitated coordinated task completion, efficient localization, and tracking in dynamic aquatic environments through autonomous communication models, promoting improved performance and stability via collective rewards and decentralized control . The development of advanced simulation platforms, such as Stonefish, has also been instrumental, providing comprehensive sensor simulations and robust physics engines necessary for the development and rigorous testing of these sophisticated algorithms under realistic conditions .

Despite these notable advancements, several formidable challenges persist in the field. Key among these are issues related to sample efficiency, particularly in real-world deployments where data acquisition can be costly and time-consuming, and the inherent complexities of sim-to-real transfer, which often result in a performance gap between simulated and physical environments . Another significant hurdle involves the handling of inconsistent large-scale human feedback, which is crucial for fine-tuning policies to align with complex human preferences .
Looking ahead, the future outlook for RL-based USV swarm navigation is promising, with a strong emphasis on integrating ethical considerations and human preferences into algorithm design. The development of methods for incorporating human implicit feedback, such as the Agent-Level Feedback system combined with LLM evaluators, represents a crucial step towards aligning system behavior with user preferences, especially when direct reward function encoding is challenging . Future research should prioritize exploring active learning strategies to enable more efficient and robust feedback acquisition, mitigating the challenges posed by inconsistent human input . Furthermore, research efforts should focus on enhancing the robustness and adaptability of RL models to unforeseen environmental dynamics and adversarial conditions, ensuring their reliability in real-world scenarios. Addressing these challenges and integrating human-centric design principles will be paramount in realizing the full potential of RL-based USV swarm navigation.
References
Human Implicit Preference-Based Policy Fine-tuning for Multi-Agent Reinforcement Learning in USV Swarm - arXiv https://arxiv.org/pdf/2503.03796
[Literature Review] Stonefish: Supporting Machine Learning ... https://www.themoonlight.io/en/review/stonefish-supporting-machine-learning-research-in-marine-robotics
[2304.08189] Control and Coordination of a SWARM of Unmanned Surface Vehicles using Deep Reinforcement Learning in ROS - arXiv https://arxiv.org/abs/2304.08189
[2503.03796] Human Implicit Preference-Based Policy Fine-tuning for Multi-Agent Reinforcement Learning in USV Swarm - arXiv https://arxiv.org/abs/2503.03796
A Review of Research on Path Planning of Unmanned Surface Vessel Swarm: Deep Reinforcement Learning - SciEngine https://www.sciengine.com/doi/10.11993/j.issn.2096-3920.2025-0034
WO/2021/082864 DEEP REINFORCEMENT LEARNING-BASED INTELLIGENT COLLISION-AVOIDANCE METHOD FOR SWARM OF UNMANNED SURFACE VEHICLES - Patentscope https://patentscope.wipo.int/search/en/WO2021082864